Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
There’s a lot to say about a wide variety of open models. Some of them are known as the Mixtral family, in all of their sizes, and a maybe less known kind are the openbiollm, a Llama 3 adaptation for the medical field. Testing all of them by implementing their APIs would take a lot of work. However, Ollama allows us to test them all using a friendly interface and a straightforward command line.
In this article, we’ll build a RAG application in Golang, using Ollama as the LLM server and Elasticsearch as the vector database.
Steps for building RAG application with Ollama & Go
Install Ollama
What is Ollama?
Ollama is a framework that allows you to download and access models locally with a CLI. With simple commands we can download, chat, and set up a server with the model we want to consume from our app.
Download the Ollama installer here:
The library with the available models is here:
Once you have installed Ollama, we can test that everything works by running one of the available models. Let’s install llama3.2 with 3B parameters. The library includes the necessary commands to download and run the model:
We’ll run the command for the 3B version:
The first time, it will download the model and then open a chat in the terminal:
Now we can type /exit to exit and use the server set up in this location: http://localhost:11434. Let's test the endpoints to make sure everything is working as expected.
Ollama offers two answer modes: generate to provide a single answer and chat to have conversations with the model:
Generate
We use generate when we expect a single answer to a single question and nothing else.
Chat
We use chat when we expect to continue the conversation after the first question, and we want the LLM to remember the previous interactions.
By default, the answer is generated as stream: true but we’ll use stream: false so that the answer is generated in just one message and it’s easier to read. stream: true is useful in UI applications as tokens are sent as they are generated, as opposed to blocking until the entire response is complete.
Let’s move on to the data.
Ingesting data
Let's index some medical documents in Elasticsearch as text and vectors. We'll use these to test the quality of the answers from a medical-oriented model like openbiollm compared to a general one.
Before we start, make sure that we have created the inference endpoint to use ELSER as our embeddings model:
Now, let’s continue creating the index using the semantic_text field type that will allow us to control the chunking size, as well as vector configuration. This allows our index to support full text, semantic, and hybrid searches.
Now, let’s index the documents:
Done! Now that we have the model and data ready, we can put everything together with our Go app.
RAG App in Go
For our Go application, we could make calls to the Ollama server directly but I’ve decided to use parakeet instead. Parakeet is a library to create GenAI applications based on Go text. It provides Go interfaces to abstract the HTTP communication, besides giving helpers for embeddings, chunking, and memory, among others, so it makes it very easy to create an application.
We’ll begin by creating our work folder and setting up dependencies:
Now, create a main.go file with the minimum you need to test that everything is configured correctly:
main.go
Run it:
In the terminal, you should see an answer similar to this:
Elastic, a company known for its innovative and user-friendly software solutions, has disrupted the traditional IT industry by empowering businesses to create, deploy, and manage applications quickly and reliably.
This answer is based on the LLM's training data, which is not something that we can provide or control and present some disadvantages:
- Information may be wrong
- Information may be outdated
- There is no way to get citations of the source
Now, let’s create a file called elasticsearch/elasticsearch.go to connect with Elasticsearch using the Go’s official client and be able to use the information in our documents to generate grounded answers based on our data.
The EsClient function initializes the Elasticsearch client using the Cloud Credentials provided, and SemanticRetriever performs a semantic query to build the context the LLM needs to answer a question.
To find your Cloud ID and API Key, go to this link.
Let’s go back to our main.go file and update with the above features to call Elasticsearch and run a semantic query: This builds the LLM context:
main.go
As you can see, we send the user’s question together with all of the documents related to it. This is how we get an answer based on documents in Elasticsearch.
We can test by running the code:
You should see something like:
According to the article "JAK Inhibitors vs. Monoclonal Antibodies in Rheumatoid Arthritis Treatment", JAK inhibitors and monoclonal antibodies are two classes of drugs used to treat rheumatoid arthritis (RA). The main difference between them lies in their mechanisms of action:
JAK inhibitors target intracellular signaling pathways, specifically the Janus kinase (JAK) pathway, which is involved in inflammation and immune response. They have a rapid onset of action and are administered orally.
Monoclonal antibodies target specific proteins involved in the inflammatory process, such as tumor necrosis factor-alpha (TNF-α), interleukin-6 (IL-6), and interleukin-17 (IL-17).
The article highlights that JAK inhibitors have a more favorable safety profile compared to monoclonal antibodies, with fewer gastrointestinal side effects. However, the choice between these two classes of drugs depends on patient characteristics and disease severity.
"References:"
"JAK Inhibitors vs. Monoclonal Antibodies in Rheumatoid Arthritis Treatment" (document title)
Parakeet will handle the Ollama interaction for us, including the token stream! From now on, we can test different models quite easily without making changes to the code.
Besides the models in the main library, we also have access to the ones uploaded by community members.
To use one, we just have to make sure to download into Ollama first. For example, let’s test openbiollm:
ollama run taozhiyuai/openbiollm-llama-3:8b_q8_0
Once installed, we can use it with our Go code:
Let’s run it again with the same question. Do you notice any differences?
In rheumatoid arthritis treatment, JAK inhibitors and monoclonal antibodies are commonly used. This article discusses the benefits and drawbacks of both therapies. JAK inhibitors work by targeting intracellular signaling pathways involved in the immune response. They have a rapid onset of action and can be administered orally, making them convenient for patients. Recent clinical trial data has shown that JAK inhibitors are effective at reducing inflammation and slowing joint damage progression in rheumatoid arthritis. However, there is still ongoing research to fully understand their long-term safety profile. Monoclonal antibodies, on the other hand, specifically target molecules involved in the immune system. These drugs have been found to be highly effective in managing symptoms of rheumatoid arthritis and improving joint function. They can provide prolonged symptom control and are often used as first-line treatment options. However, due to their complexity and unique administration requirements, monoclonal antibodies may not be suitable for all patients. In conclusion, both J AK inhibitors and monoclonal antibodies have their own advantages and disadvantages in treating rheumatoid arthritis. The choice of therapy depends on individual patient characteristics and disease severity. Ongoing research will contribute to a deeper understanding of the efficacy and safety profiles of these treatments, ultimately leading to improved care for patients with rheumatoid arthritis.
It seems that the openbiollm model provided more details with the technical lingo, but it didn’t follow instructions about referencing the documents provided in the context and giving brief answers. In comparison, Llama3.2 followed instructions better.
You can find the full working example here
Conclusion
Ollama provides a very straightforward and simple way to download and test different open models, from the better-known to those fine-tuned by community members. Pairing it with Parakeet and the official Elasticsearch Go client, makes it very easy to create a RAG application. In addition, by using the semantic_text field type, you can create a semantic-query-ready index that uses ELSER–the Elastic Sparse embeddings model–without any additional configurations, thus simplifying the chunking, indexing, and vector querying process, too.
Related Content
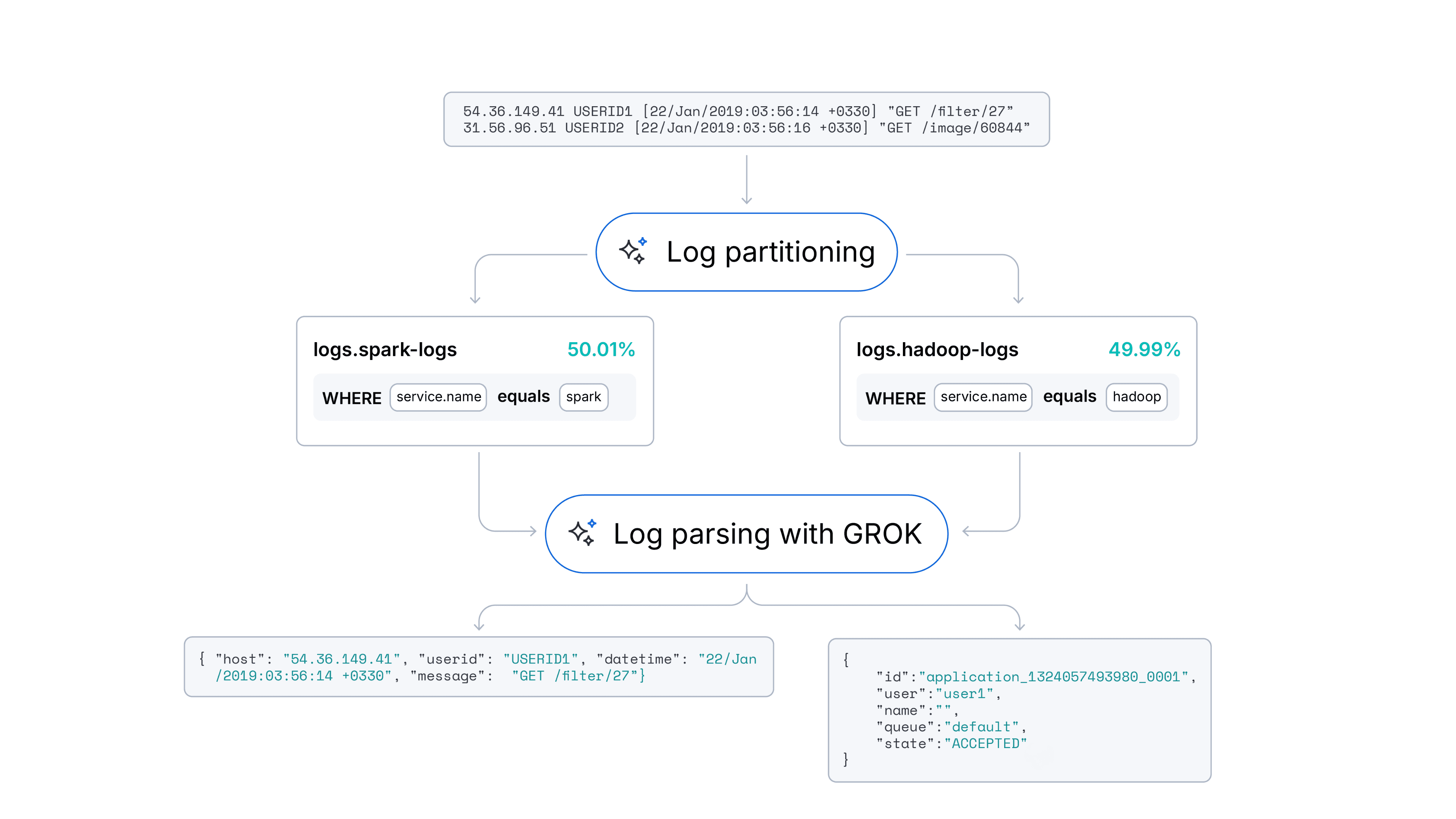
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
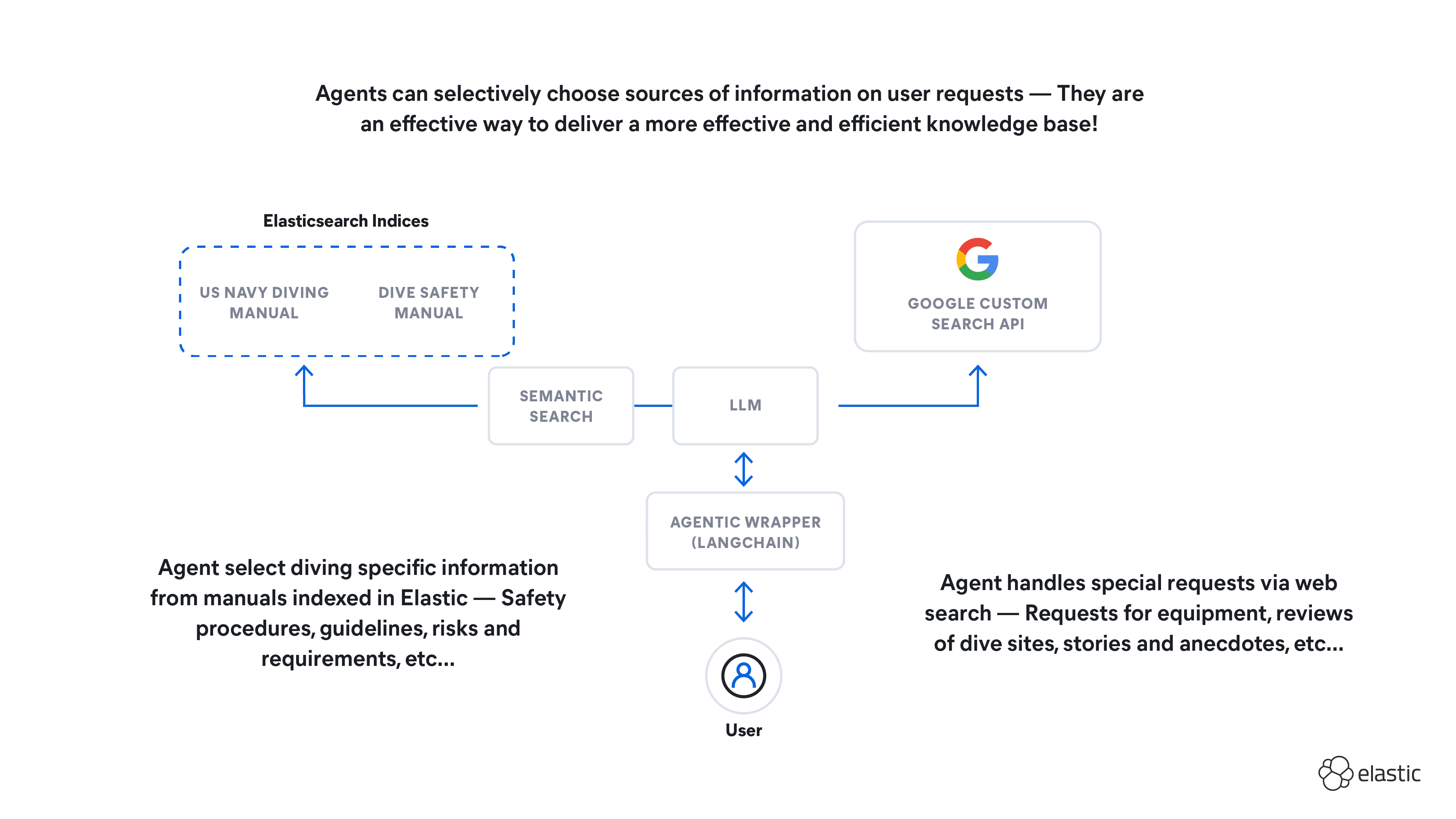
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.

December 29, 2025
Creating reliable agents with structured outputs in Elasticsearch
Explore what structured outputs are and how to leverage them in Elasticsearch to ground agents in the most relevant context for data contracts.
December 23, 2025
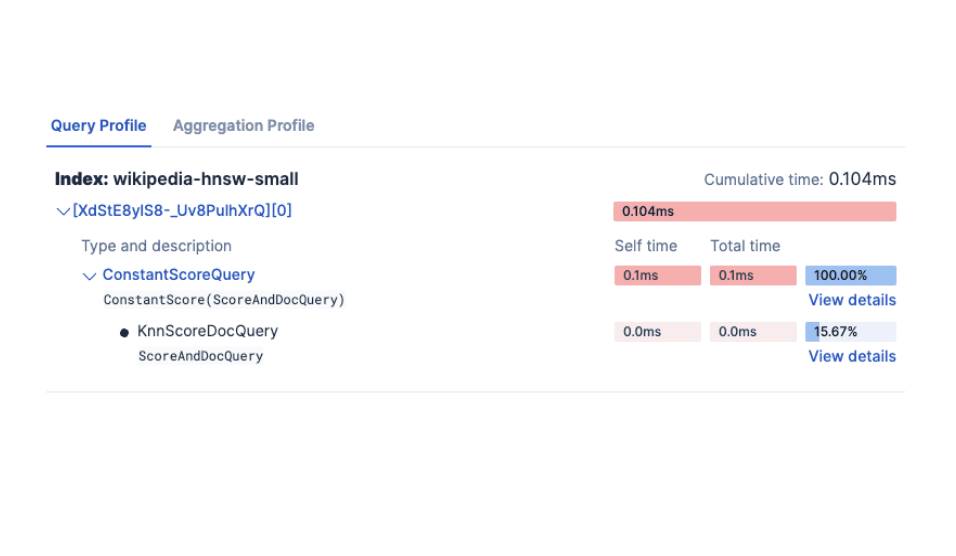
Comparing dense vector search performance with the Profile API in Elasticsearch
Learn how to use the Profile API in Elasticsearch to compare dense vector configurations and tune kNN performance with visual data from Kibana.
December 15, 2025
Getting started with Elastic Agent Builder and Strands Agents SDK
Learn how to create an agent with Elastic Agent Builder and then explore how to use the agent via the A2A protocol orchestrated with the Strands Agents SDK.