Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
In this article, we’ll explore how Artificial Intelligence (AI), specifically using advanced language models like GPT-4, can help create more contextual facets, making them even more relevant and useful for users.
Facet search is a powerful tool in e-commerce platforms. It helps organize and refine search results based on the characteristics of the displayed items. While often confused with filters, facets work differently. Filters are fixed attributes, defined by information always present in the index, such as the category or format of a product. Facets, on the other hand, are dynamic and generated from the results returned by the executed search.
Imagine a clothing catalog: fields like "category" (e.g., t-shirts, pants) or "gender" (e.g., male, female) are filters that help narrow down results. Facets, however, reflect specific characteristics of the products appearing in the results, such as common colors, available sizes, or materials. This allows for a more adaptable and contextual search experience.
Below is an image where we interact with a facet and can see the search results filtered by them.
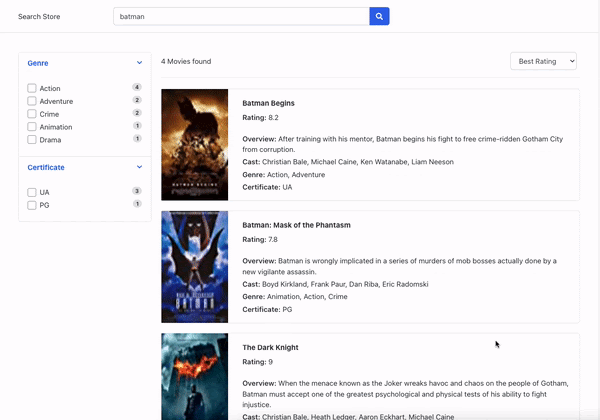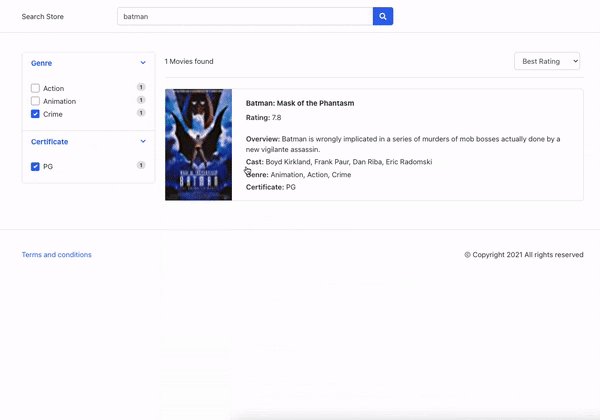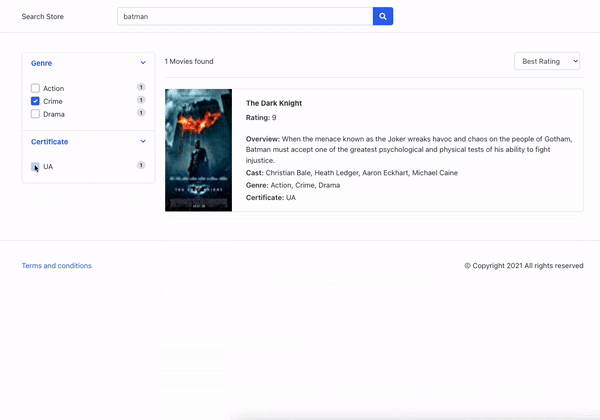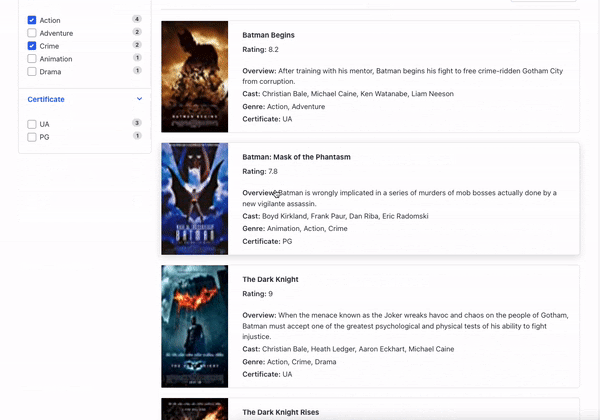
How AI can improve facet generation
Artificial Intelligence is often associated with semantic search and embeddings, but what about facets? How can AI be leveraged to make facets more useful and context-specific for each search?
One intriguing possibility is using AI to create new categorizations that go beyond the traditional classifications in the index. By analyzing specific characteristics of the content, these new categories can provide richer and more precise contextualization, making facets more relevant and aligned with users’ needs. This enables a more meaningful refinement of results compared to the original document categories.
How AI can refine movie classifications for better searches
Let’s analyze the following films, all currently classified under the Drama genre:
- Requiem for a Dream
Resume: The drug-induced utopias of four Coney Island people are shattered when their addictions run deep. - American Beauty
Resume: A sexually frustrated suburban father has a mid-life crisis after becoming infatuated with his daughter's best friend. - Good Will Hunting
Resume: Will Hunting, a janitor at M.I.T., has a gift for mathematics, but needs help from a psychologist to find direction in his life.
This genre classification doesn’t capture the subtle differences or unique contexts of each film. By leveraging AI to analyze synopses and central themes, we can create new categories that better reflect the true context of each movie. For instance:
- Requiem for a Dream - New Category: "Addiction and Dependency"
- American Beauty - New Category: "Mid-life Crisis"
- Good Will Hunting - New Category: "Intellectual Struggle"
These new categories make searches much more precise while offering users more meaningful filters to refine their results. This approach is particularly effective when original categories are overly generic, enabling users to find exactly what they’re looking for with greater ease.
Creating new categories with GPT-4: Faceted search example
In this example, we will show how an AI model can be used to create new movie categories that are more precise and aligned with the context of each work. To demonstrate this process, we will use the Elastic simulation pipeline together with the OpenAI inference service. A pipeline with several processors will be created, including the Script Processor, which will be responsible for creating the prompt to be executed in the Inference Processor, capable of determining the new categories. The other processors will be used to manipulate the data and auxiliary fields generated during the pipeline execution. It is worth mentioning that this logic can also be applied with other similar tools or models.
First, we need to create the inference endpoint, where we define the service as OpenAI, the token required to access the service, and the model. In this example, I am using gpt-4o-mini. For more details about the OpenAI inference service click here.
With the endpoint created, we are now ready to use it to create the new categories. Below is a pipeline that handles the entire process of document data manipulation and prompt generation. I will explain the function of each processor in detail.
The first processor will be responsible for building the prompt. It is very important to clearly detail the instructions so that the AI can correctly analyze and identify the topics. In this prompt, I am requesting 2 topics based on the analysis of the title, description, and genres of the movies.
The next pipeline is the inference pipeline, it will receive the prompt and send it to our generate_topics_ia endpoint. The response generated by the model will be stored in the result field.
Next, we have 3 processors used to manipulate the response and set it in the topics field, in addition to removing temporary fields that I created.
When executing this pipeline, we will have the results below:
Note that we have new categories that are more related to the context of the films, even though some are initially from the same genre.
We can now use these new categories and index them together with the document. This way, when generating the facets, in addition to the primary category, we have more specific subcategories that are aligned with the context of the films.
In addition, it is possible to vectorize these new categories and use them in vector searches. This means that the new categories not only serve as filters, but can also be used to calculate semantic similarities with the search terms, further increasing the relevance of the results presented.
Complete pipeline:
Conclusion
Using AI to improve facets can transform the search experience by making results more specific and contextual. Unlike fixed categories, which are often broad, AI-generated categories can better reflect context. For example, when reclassifying movies, we can capture context that the primary categories miss, providing much more relevant groupings.
These new categories can be added to the index not only to improve faceting, but also to enable vector searches. The result is a more efficient search experience, with filters that are more aligned to context.
References
https://www.elastic.co/guide/en/elasticsearch/reference/current/infer-service-openai.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/simulate-pipeline-api.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/script-processor.html
Frequently Asked Questions
What is faceted search?
Faceted search is a tool in e-commerce platforms. It helps organize and refine search results based on the characteristics of the displayed items.
How AI can improve faceted search?
AI can improve facet generation in search by creating new categorizations that go beyond the traditional classifications in the index, making results more specific and contextual.
Related Content

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
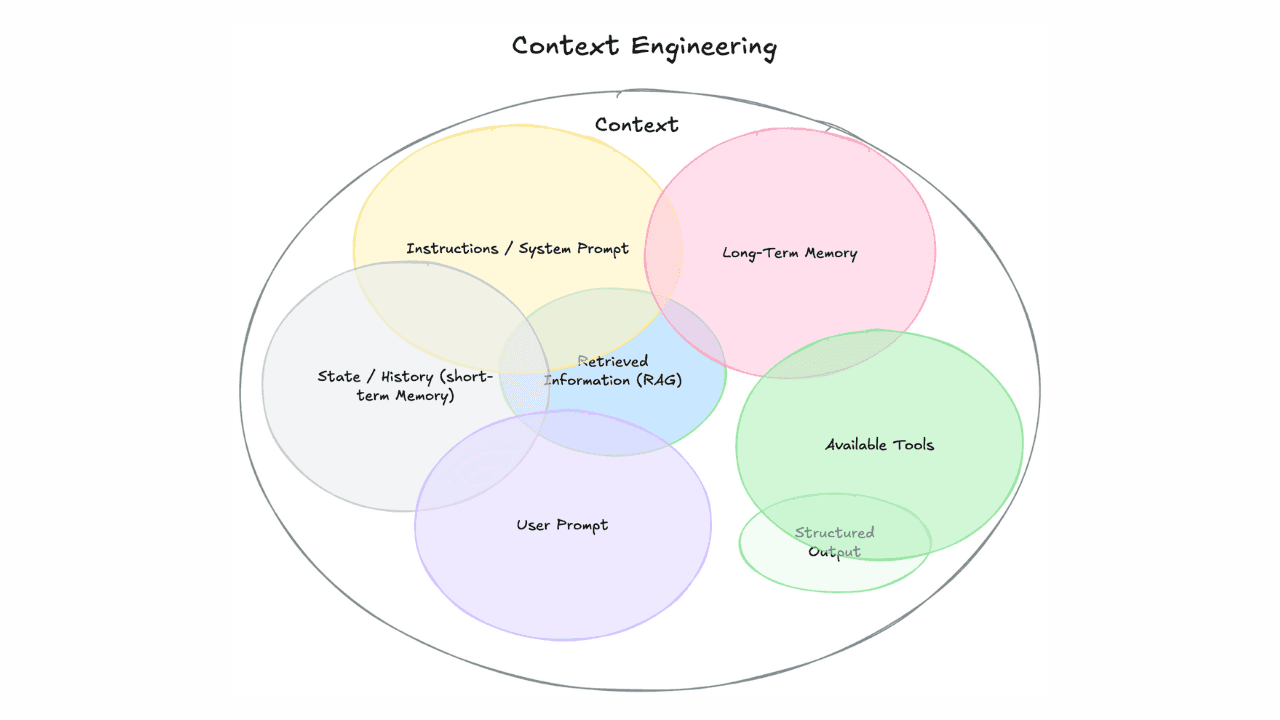
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
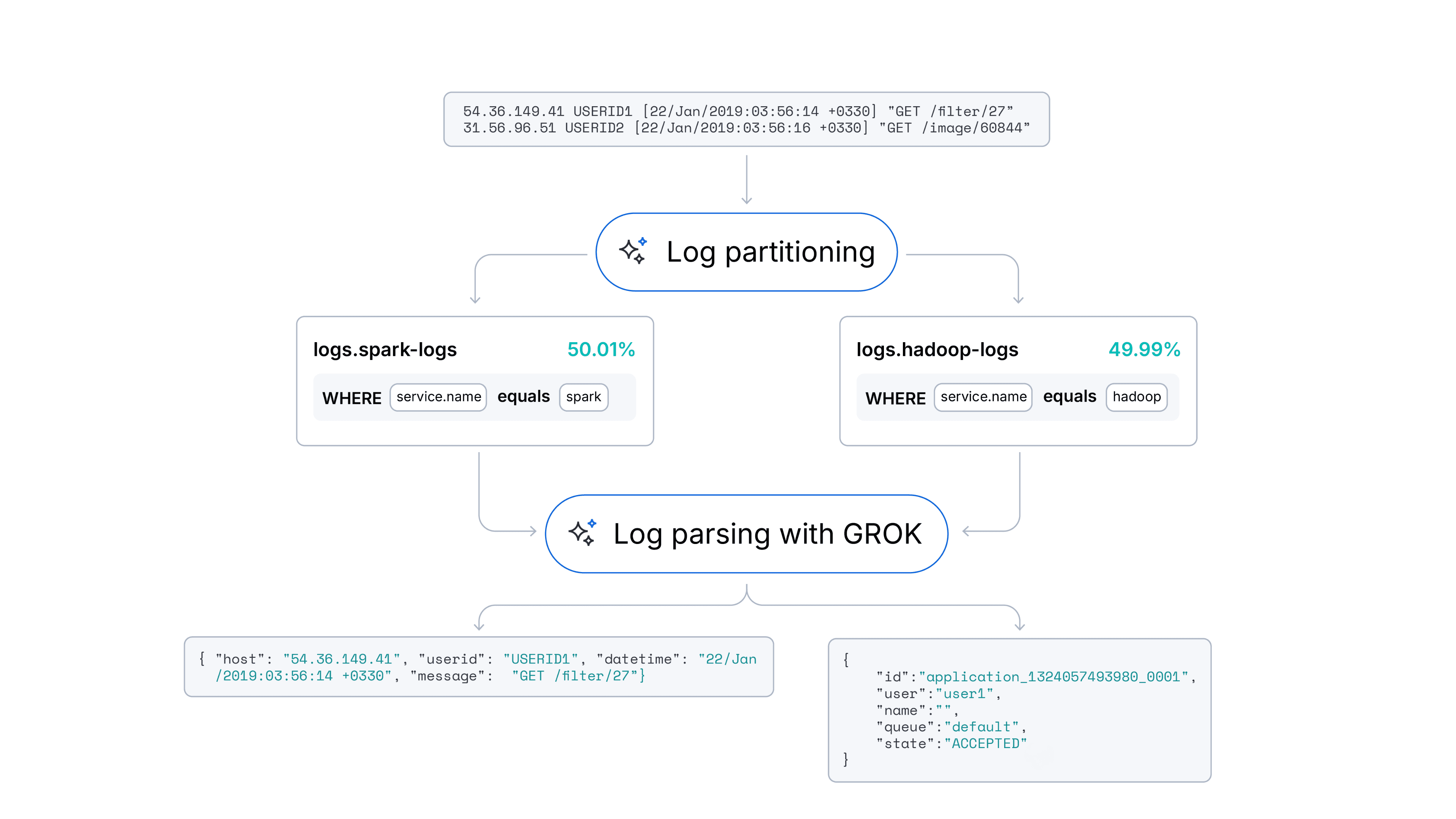
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
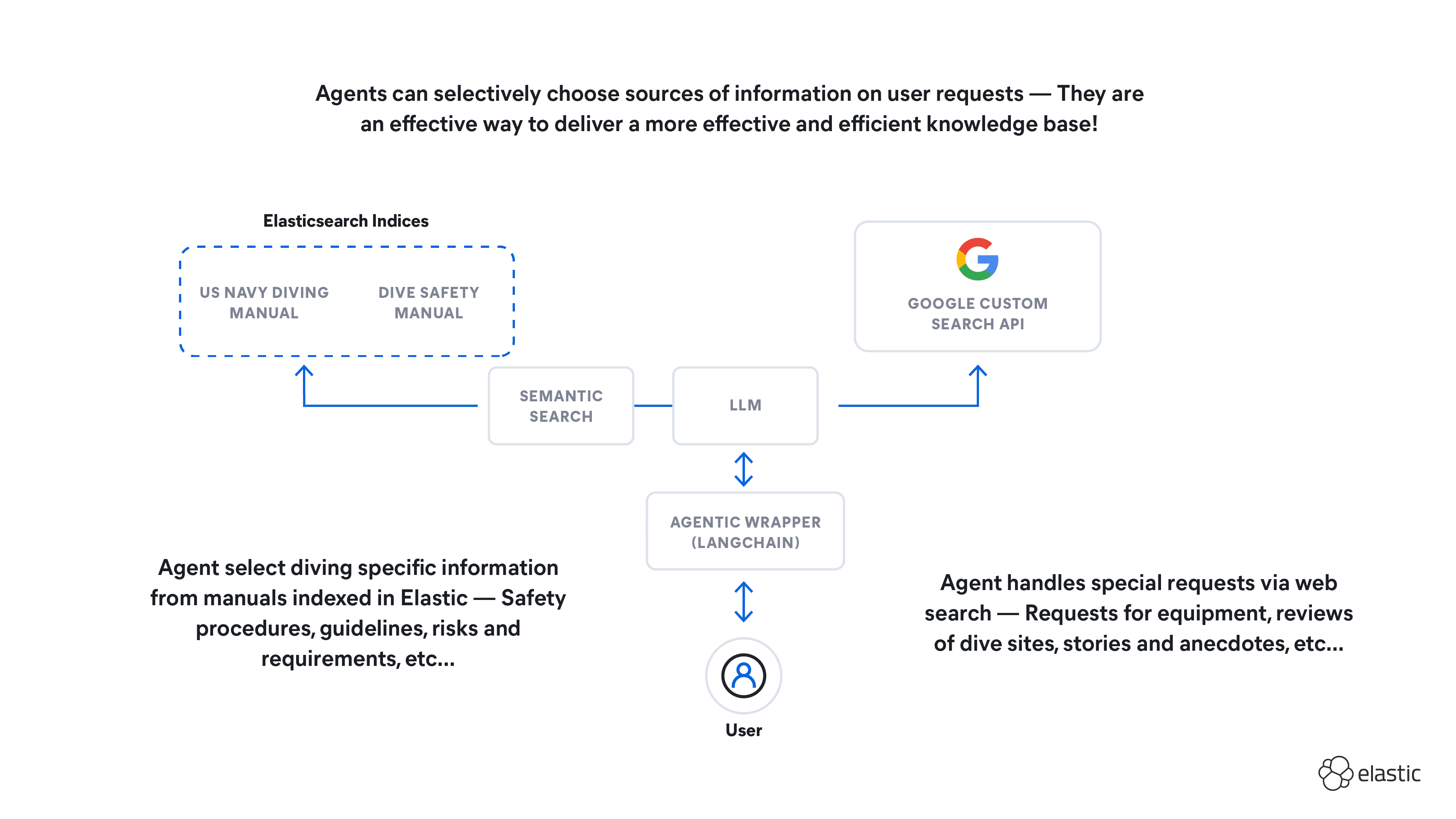
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.

December 29, 2025
Creating reliable agents with structured outputs in Elasticsearch
Explore what structured outputs are and how to leverage them in Elasticsearch to ground agents in the most relevant context for data contracts.