Elasticsearch is packed with new features to help you build the best search solutions for your use case. Learn how to put them into action in our hands-on webinar on building a modern Search AI experience. You can also start a free cloud trial or try Elastic on your local machine now.
Germans are famous for their lengthy compound words: Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz is the longest word in the german dictionary — and a nightmare for search engines unprepared to handle compounding. Many other languages such as Dutch, Swedish and others have this concept as well. Even English - though to a lesser extent - has some of these words. Think about “sunflower” or “basketball”.
Let’s discuss the problems and challenges that come with compound word search, why this is an issue and how to address it.
The problem with compound word search
When doing full text searches, search engines such as Elasticsearch analyze text during the query and indexing time and turn the text into tokens. Rather than exactly matching the string, we want to extract the meaning of the word. For our search, we don't worry about whether the bunny is “running” or “runs” —we simply reduce the word to its root form: "run."
When we are dealing with compound words this stage will fail if we don’t address it and handle it in a certain way. Imagine we have an index with a document: “Basketballs”. If we were to _analyze this with the standard English analyzer we get:
Response:
In this example, the compound word 'basketballs' is tokenized into 'basketbal'. While we were able to lowercase and remove the plural form of the word, we were not able to capture the meaning that a basketball is also a ball. Now if we were to search for “ball” within our index we would expect to find our basketball - but “bal” (analyzed) does not match “basketbal”, so we are not getting any results!
How do we address this problem?
Can synonyms solve compound word search?
The first thought we might have is to try synonyms to associate the different sub words with our compound words. This works well enough for English because of the fairly limited use of compound words:
Now let’s take a look at German. The way that the grammar works is that any arbitrary amount of words can be combined to form a more precise word.
Rind (cow) and Fleisch (meat) become Rindfleisch (cowmeat/beef).
Rind (cow), Fleisch (meat) and Etikett (label) become Rindfleischetikett (cowmeatlabel). This can be done at arbitrary length until we get lovely words such as Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz.
To solve this with our synonyms file we would have to model an infinite amount of permutation of words:
In languages such as German this becomes impractical really quickly. So we have to approach the problem from the opposite angle. We don’t go from the compound word to its compounds but rather we look at the available compound parts and deconstruct the word based on this knowledge.
Using the Hyphenation Decompounder for compound word search
The Hyphenation Decompounder Token Filter is a Lucene token filter that relies on hyphenation rules to detect potential word splits. Rule files are specified in the Objects For Formatting Objects (OFFO) format, where we can also find some example files. We also need a list of words that is used to decompound the compound words into their sub-parts. The word list can be provided inline, but for production workloads we typically also upload a file to disk as these files can be quite large and typically contain entire dictionaries.
Example files for the German language, provided under their license, can be found in this repository.
So what does it do?
This helps ensure that a user searching for “Tasse” (cup) can find documents that contain the larger compound “Kaffeetasse” (coffee cup).
Notes:
- Check out this article on how to upload a bundle to be able to access these files in your Elastic Cloud Hosted deployments.
- There is also the Dictionary Decompounder, which does the same thing without the hyphenation rules and instead brute forces the word detection. For most use cases we recommend the Hyphenation Decompounder.
Avoiding partial matches
Because we typically use word lists of entire dictionaries with many thousand words, the decompounder may split words in unintended ways with the default settings, leading to irrelevant matches.
This example detects “fee” (fairy) within “Kaffee” (coffee). This is of course accidental and not intended. Another example might be “Streifenbluse” (striped blouse) which finds “Reifen” (tires) in it. “Streifen” (stripe), “Reifen” (tire) and “Bluse” (blouse) are all common words that we would normally want to split on.
Our users searching for “fee” (fairies) and “reifen” (tires) now find coffee and blouses! That’s not good.
In 8.17 there is a new parameter no_sub_matches added to the hyphenation_decompounder to account for this problem.
This prevents creating the “fee” (fairy) token and our search works as expected!
Matching all query terms
With what we have looked at so far an index mapping to search german text might look like something along this index definition:
Note: In a real production setting there will most likely be filters around asciifolding, emoji filters or synonyms in there, but this is already a good starting point and should get good results for German text.
When searching for multiple terms we would typically expect (disregarding advanced query relaxation strategies) that all search terms that we specified are contained in our result. So when searching for Lederjacke (leather jacket) in an e-commerce store we expect our products to be jackets made out of leather and not a random assortment of leather products and jackets.
The way to achieve this is by setting the operator in our search query to AND. So we do that and search for “Lederjacke” (leather jacket) in our products:
Perhaps surprisingly this does not behave as we might expect. We find all products that have either leather or jacket in them. This is because the operator gets evaluated before tokenization and the resulting tokens from the token filter get evaluated with an OR.
In order to fix this we need to decompound our terms within our application. We can do this by calling the _analyze API first and then passing the decompounded terms to our search query. Because we have already decompounded we are using a search analyzer without the decompounder filter in the filter chain.
Alternative ways to search decompounded words
While Elasticsearch Serverless comes with many great advantages for search applications due to its ability to dynamically scale depending on load, at the time of writing this article it is currently not possible to upload files and use the Hyphenation Decompounder in those projects.
Alternative tools
Alternatives that can be used outside the Elastic stack are JWordSplitter which is available for Java and the CharSplit model or the CompoundPiece model which apply a machine learning approach to decompound words without the need for configuration files.
Here's how you can use CompoundPiece with the Hugging Face transformers library:
It supports 56 languages and is able to work without configuration files, which is a nice way to get decompounding for multilingual applications.
Semantic search
Something that we have covered in many of our articles here is semantic search with text embedding models. These are able to interpret the meaning of text and can be searched by turning the documents and query into vectors and finding the closest documents to the query.
Combining lexical search as discussed here with vector search is called hybrid search. This can also help to greatly improve the quality of your results and interpreting the meaning behind those compound words in your texts.
Conclusion
Decompounding is an essential tool for building effective multilingual search applications - especially when languages such as German are involved. By using tools like the Hyphenation Decompounder, we can ensure that our search can understand the meaning behind compound words, delivering better and more relevant results for users.
As with any adjustment to your search algorithms, it's important to assess its overall impact on your search performance. Learn more about how to objectively measure the quality of your search results by exploring our article on the _eval APIs.
Frequently Asked Questions
What is the Hyphenation Decompounder Token Filter?
The Hyphenation Decompounder Token Filter is a Lucene token filter that relies on hyphenation rules to detect potential word splits.
How to search languages with compound words?
You can search languages with compound word by using tools like the Hyphenation Decompounder. This tool ensures that your search can understand the meaning behind compound words, delivering better and more relevant results for users.
Related Content
January 8, 2026
Hybrid search and multistage retrieval in ES|QL
Explore the multistage retrieval capabilities of ES|QL, using FORK and FUSE commands to integrate hybrid search with semantic reranking and native LLM completions.

December 19, 2025
Elasticsearch Serverless pricing demystified: VCUs and ECUs explained
Learn how Elasticsearch Serverless pricing works for Elastic’s fully-managed deployment offering. We explain VCUs (Search, Ingest, ML) and ECUs, detailing how consumption is based on actual allocated resources, workload complexity, and Search Power.
December 11, 2025
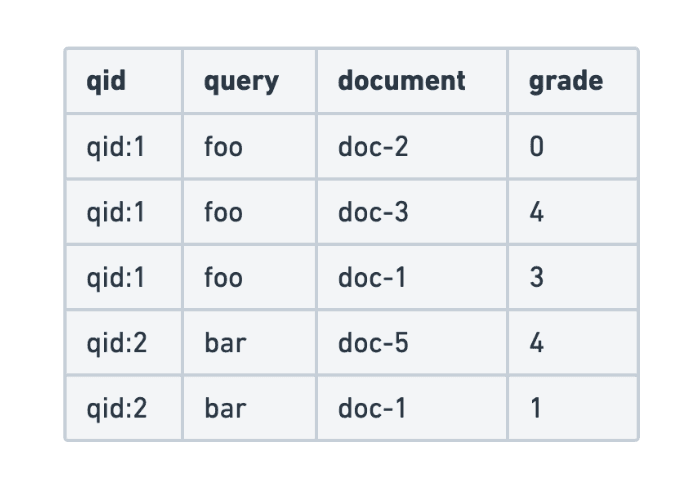
Evaluating search query relevance with judgment lists
Explore how to build judgment lists to objectively evaluate search query relevance and improve performance metrics such as recall, for scalable search testing in Elasticsearch.
December 10, 2025
How to improve e-commerce search relevance with personalized cohort-aware ranking
Improve e-commerce search relevance with explainable, cohort-aware ranking in Elasticsearch. Learn how multiplicative boosting delivers stable, predictable personalization at query time.
December 8, 2025
How excessive replica counts can degrade performance, and what to do about it
Learn about the impact of high replica counts in Elasticsearch, and how to ensure cluster stability by right-sizing your replicas.