Elasticsearch allows you to index data quickly and in a flexible manner. Try it free in the cloud or run it locally to see how easy indexing can be.
OneLake is a tool that allows you to connect to different Microsoft data sources like Power BI, Data Activator, and Data factory, among others. It enables centralization of data in DataLakes, large-volume repositories that support comprehensive data storage, analysis, and processing.
In this article, we’ll learn to configure OneLake, consume data using Python and index documents in Elasticsearch to then run semantic searches.
Sometimes you would want to run searches across unstructured data, and structured from different sources and software providers, and create visualizations with Kibana. For this kind of task indexing the documents in Elasticsearch as a central repository becomes extremely helpful.
For this example, we’ll use a fake company called Shoestic, an online shoe store. We have the list of products in a structured file (CSV) while some of the products’ datasheets are in an unstructured format (DOCX). The files are stored in OneLake.
You can find a Notebook with the complete example (including test documents) here.
Steps
OneLake initial configuration
OneLake architecture can be summarized like this:
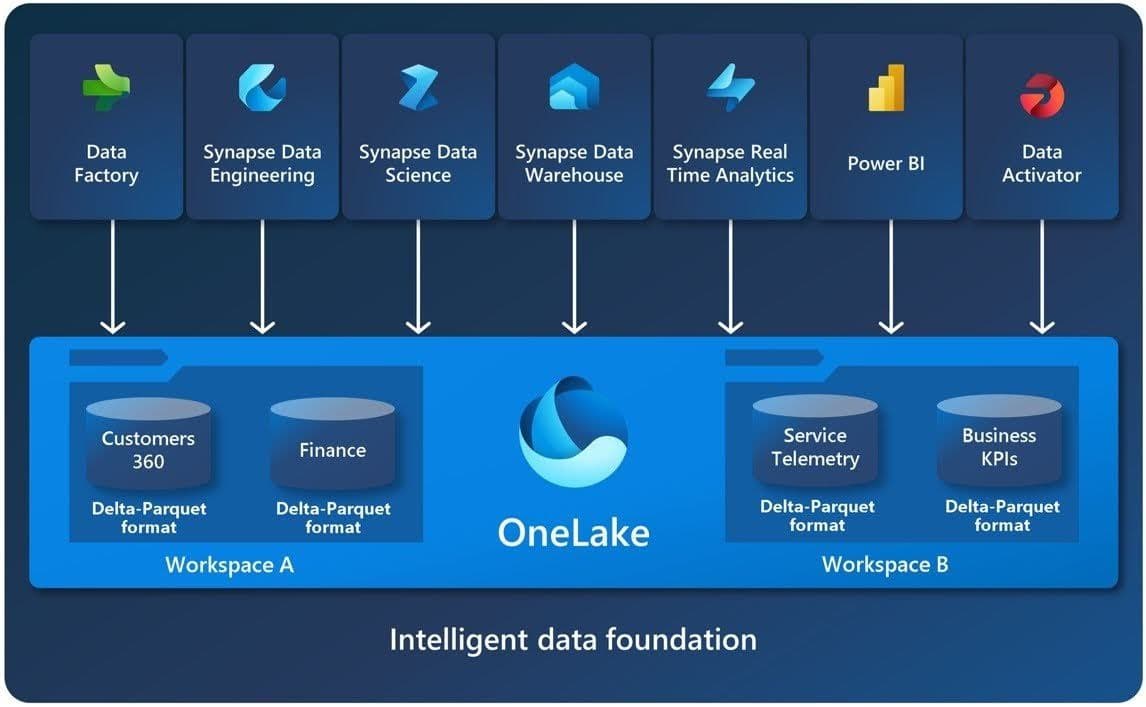
To use OneLake and Microsoft Fabric, we’ll need an Office 365 account. If you don’t have one, you can create a trial account here.
Log into Microsoft Fabric using your account. Then, create a workspace called "ShoesticWorkspace". Once inside the newly created workspace, create a Lakehouse and name it "ShoesticDatalake". The last step will be creating a new folder inside “Files”. Click on “new subfolder” and name it "ProductsData".
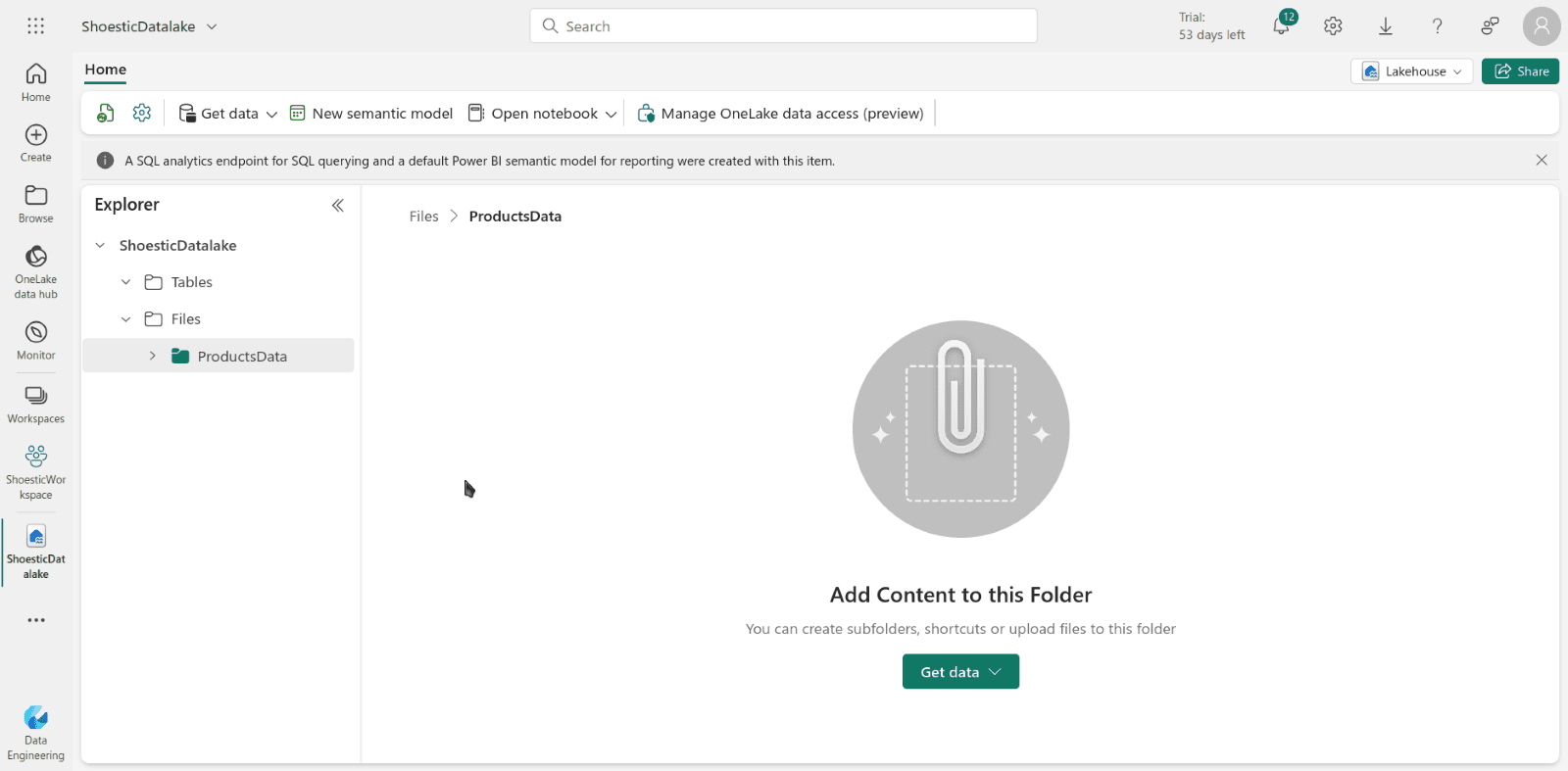
Done! We're ready to begin ingesting our data.
Connect to OneLake using Python
With our OneLake configured, we can now prepare the Python scripts. Azure has libraries to handle credentials and communicate with OneLake.
Installing dependencies
Run the following in the terminal to install dependencies
The "azure-identity azure-storage-file-datalake" library lets us interact with OneLake while "azure-cli" access credentials and grant permissions. To read the files’ content to later index it to Elasticsearch, we use python-docx.
Saving Microsoft Credentials in our local environment
We’ll use "az login" to enter our Microsoft account and run:
The flag " --allow-no-subscriptions" allows us to authenticate to Microsoft Azure without an active subscription.
This command will open a browser window in which you’ll have to access your account and then select your account’s subscription number.
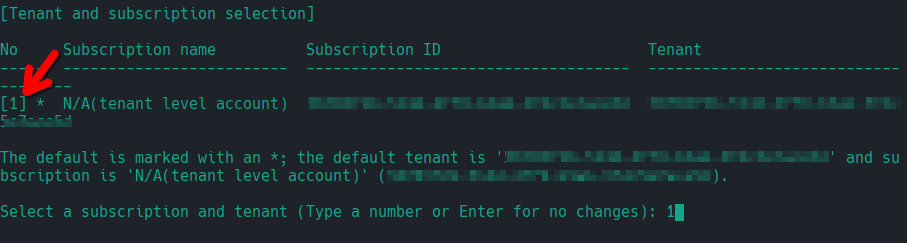
We’re now ready to start writing the code!
Create a file called onelake.py and add the following:
_onelake.py_
Uploading files to OneLake
In this example, we’ll use a CSV file and some .docx files with info about our shoe store products. Though you can upload them using the UI, we’ll do it with Python. Download the files here.
We’ll place the files in a folder /data next to a new python script called upload_files.py:
Run the upload script
The result should be:
Now that we have the files ready, let’s start analyzing and searching our data with Elasticsearch!
Indexing documents
We’ll be using ELSER as the embedding provider for our vector database so we can run semantic queries.
We choose ELSER because it is optimized for Elasticsearch, outperforming most of the competition in out-of-domain retrieval, which means using the model as it is, without fine tuning it for your own data.
Configuring ELSER
Start by creating the inference endpoint:
While loading the model in the background, you can get a 502 Bad Gateway error if you haven’t used ELSER before. In Kibana, you can check the model status at Machine Learning > Trained Models. Wait until the model is deployed before proceeding to the next steps.
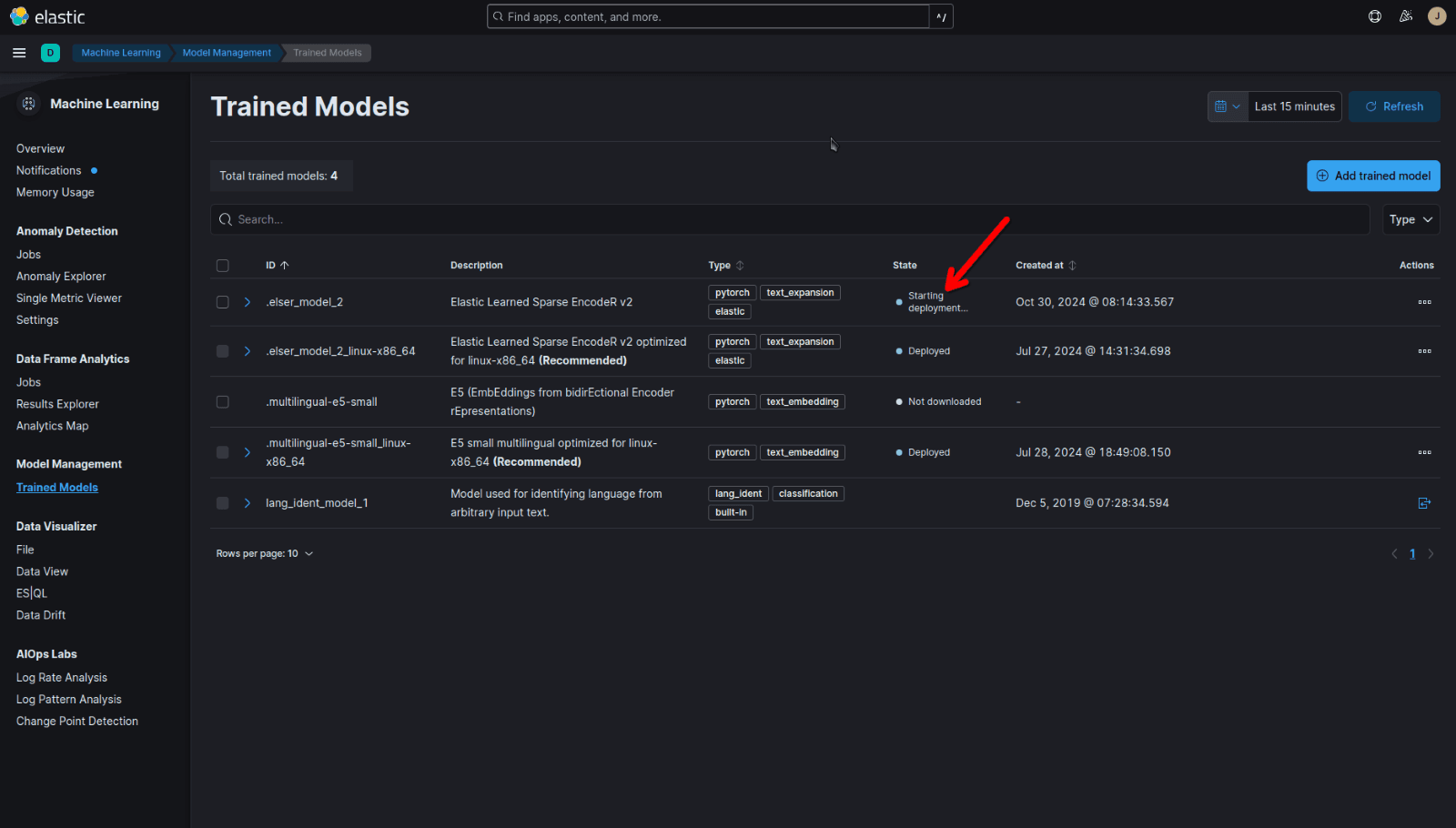
Index data
Now, since we have both structured and unstructured data, we’ll use two different indices with different mappings as well in the Kibana DevTools Console.
For our structured sales let’s create the following index:
And to index our unstructured data (product datasheets) we'll use:
Note: It’s important to use a field with copy_to to also allow running full-text and not just semantic searches on the body field.
Reading OneLake files
Before we begin, we need to initialize our Elasticsearch client using these commands (with your own Cloud ID and API-key).
Create a python script called indexing.py and add the following lines:
Now, run the script:
Queries
Once the documents have been indexed in Elasticsearch, we can test the semantic queries. In this case, we’ll search for a unique term in some of the products (tag). We’ll run a keyword search against the structured data, and a semantic one against the unstructured data.
1. Keyword search
Result:
2. Semantic search:
*We excluded embeddings and chunks just for readability.
Result:
As you can see, when using the keyword search, we got an exact match to one of the tags and in contrast, when we used semantic search, we got a result that matches the meaning in the description, without needing an exact match.
Conclusion
OneLake makes it easier to consume data from different Microsoft sources and then indexing these documents Elasticsearch allows us to use advanced search tools. In this first part, we learnt how to connect to OneLake and index documents in Elasticsearch. In part two, we’ll make a more robust solution using the Elastic connector framework.
Frequently Asked Questions
What is OneLake?
OneLake is a tool that allows you to connect to different Microsoft data sources like Power BI, Data Activator, and Data factory, among others. It enables centralization of data in DataLakes, large-volume repositories that support comprehensive data storage, analysis, and processing.
Related Content
December 16, 2025
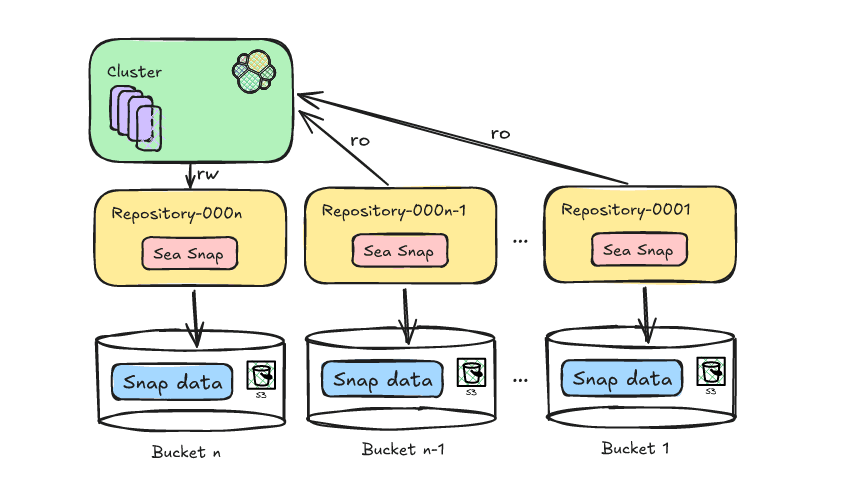
Reducing Elasticsearch frozen tier costs with Deepfreeze S3 Glacier archival
Learn how to leverage Deepfreeze in Elasticsearch to automate searchable snapshot repository rotation, retaining historical data and aging it into lower cost S3 Glacier tiers after index deletion.

September 22, 2025
Elastic Open Web Crawler as a code
Learn how to use GitHub Actions to manage Elastic Open Crawler configurations, so every time we push changes to the repository, the changes are automatically applied to the deployed instance of the crawler.

August 6, 2025
How to display fields of an Elasticsearch index
Learn how to display fields of an Elasticsearch index using the _mapping and _search APIs, sub-fields, synthetic _source, and runtime fields.

July 14, 2025
Run Elastic Open Crawler in Windows with Docker
Learn how to use Docker to get Open Crawler working in a Windows environment.

June 24, 2025
Ruby scripting in Logstash
Learn about the Logstash Ruby filter plugin for advanced data transformation in your Logstash pipeline.