Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
In collaboration with the Microsoft Semantic Kernel team, we are announcing the availability of Semantic Kernel Elasticsearch Vector Store Connector, for Microsoft Semantic Kernel (.NET) users. Semantic Kernel simplifies building enterprise-grade AI agents, including the capability to enhance large language models (LLMs) with more relevant, data-driven responses from a Vector Store. Semantic Kernel provides a seamless abstraction layer for interacting with Vector Stores like Elasticsearch, offering essential features such as creating, listing, and deleting collections of records and uploading, retrieving, deleting individual records.
The out-of-the-box Semantic Kernel Elasticsearch Vector Store Connector supports the Semantic Kernel vector store abstractions which make it very easy for developers to plugin Elasticsearch as a vector store while building AI agents.
Elasticsearch has a strong foundation in the open-source community and recently adopted the AGPL license. Combined with the open-source Microsoft Semantic Kernel, these tools offer a powerful, enterprise-ready solution. You can get started locally by spinning up Elasticsearch in a few minutes by running this command curl -fsSL https://elastic.co/start-local | sh (refer start-local for details) and move to cloud-hosted or self-hosted versions while productionizing your AI agents.
In this blog we look at how to use Semantic Kernel Elasticsearch Vector Store Connector when using Semantic Kernel. A Python version of the connector will be made available in the future.
High-level scenario: Building a RAG app with Semantic Kernel & Elasticsearch
In the following section we go through an example. At a high-level we are building a RAG (Retrieval Augmented Generation) application which takes a user's question as input and returns an answer. We will use Azure OpenAI (local LLM can be used as well) as the LLM, Elasticsearch as the vector store and Semantic Kernel (.net) as the framework to tie all components together.
If you are not familiar with RAG architectures, you can have a quick introduction with this article: https://www.elastic.co/search-labs/blog/retrieval-augmented-generation-rag.
The answer is generated by the LLM which is fed with context, relevant to the question, retrieved from Elasticsearch vectorstore. The response also includes the source that was used as the context by the LLM.
RAG example
In this specific example, we build an application that allows users to ask questions about hotels stored in an internal hotel database. The user could e.g. search for a specific hotel, based on different criteria, or ask for a list of hotels.
For the example database, we generated a list of hotels containing 100 entries. The sample size is intentionally small to allow you to try out the connector demo as easily as possible. In a real-world application, the Elasticsearch connector would show its advantages over other options, such as the `InMemory` vector store implementation, especially when working with extremely large amounts of data.
The complete demo application can be found in the Elasticsearch vector store connector repository.
Let’s start with adding the required NuGet packages and using directives to our project:
We can now create our data model and provide it with Semantic Kernel specific attributes to define the storage model schema and some hints for the text search:
The Storage Model Schema attributes (`VectorStore*`) are most relevant for the actual use of the Elasticsearch Vector Store Connector, namely:
VectorStoreRecordKeyto mark a property on a record class as the key under which the record is stored in a vector store.VectorStoreRecordDatato mark a property on a record class as 'data'.VectorStoreRecordVectorto mark a property on a record class as a vector.
All of these attributes accept various optional parameters that can be used to further customize the storage model. In the case of VectorStoreRecordKey , for example, it is possible to specify a different distance function or a different index type.
The text search attributes (TextSearch*) will be important in the last step of this example. We will come back to them later.
In the next step, we initialize the Semantic Kernel engine and obtain references to the core services. In a real world application, dependency injection should be used instead of directly accessing the service collection. The same thing applies to the hardcoded configuration and secrets, which should be read using a configuration provider instead:
The vectorStoreCollection service can now be used to create the collection and to ingest a few demo records:
This shows how Semantic Kernel reduces the use of a vector store with all its complexity to a few simple method calls.
Under the hood, a new index is created in Elasticsearch and all the necessary property mappings are created. Our data set is then mapped completely transparently into the storage model and finally stored in the index. Below is how the mappings look in Elasticsearch.
The embeddings.GenerateEmbeddingsAsync() calls transparently called the configured Azure AI Embeddings Generation service.
Even more magic can be observed in the last step of this demo.
With just a single call to InvokePromptAsync, all of the following operations are performed when the user asks a question about the data:
1. An embedding for the user's question is generated
2. The vector store is searched for relevant entries
3. The results of the query are inserted into a prompt template
4. The actual query in the form of the final prompt is sent to the AI chat completion service
Remember the TextSearch* attributes, we previously defined on our data model? These attributes enable us to use corresponding placeholders in our prompt template which are automatically populated with the information from our entries in the vector store.
The final response to our question "Please show me all hotels that have a rooftop bar." is as follows:
The answer correctly refers to the following entry in our hotels.csv
This example shows very well how the use of Microsoft Semantic Kernel achieves a significant reduction in complexity through its well thought abstractions, as well as enabling a very high level of flexibility. By changing a single line of code, for example, the vector store or the AI services used can be replaced without having to refactor any other part of the code.
At the same time, the framework provides an enormous set of high-level functionality, such as the `InvokePrompt` function, or the template or search plugin system.
The complete demo application can be found in the Elasticsearch vector store connector repository.
What else is possible with Elasticsearch
- Elasticsearch new semantic_text mapping: Simplifying semantic search
- Semantic reranking in Elasticsearch with retrievers
- Advanced RAG techniques part 1: Data processing
- Advanced RAG techniques part 2: Querying and testing
- Building RAG with Llama 3 open-source and Elastic
- A tutorial on building local agent using LangGraph, LLaMA3 and Elasticsearch vector store from scratch
Elasticsearch & Semantic Kernel: What's next?
- We showed how the Elasticsearch vector store can be easily plugged into Semantic Kernel while building GenAI applications in .NET. Stay tuned for a Python integration next.
- As Semantic Kernel builds abstractions for advanced search features like hybrid search, the Elasticsearch connect will enable .NET developers to easily implement them while using Semantic Kernel.
Frequently Asked Questions
What is Microsoft Semantic Kernel?
Microsoft Semantic Kernel is a lightweight, open-source development kit that lets you easily build AI agents and integrate the latest AI models into your C#, Python, or Java codebase.
Related Content
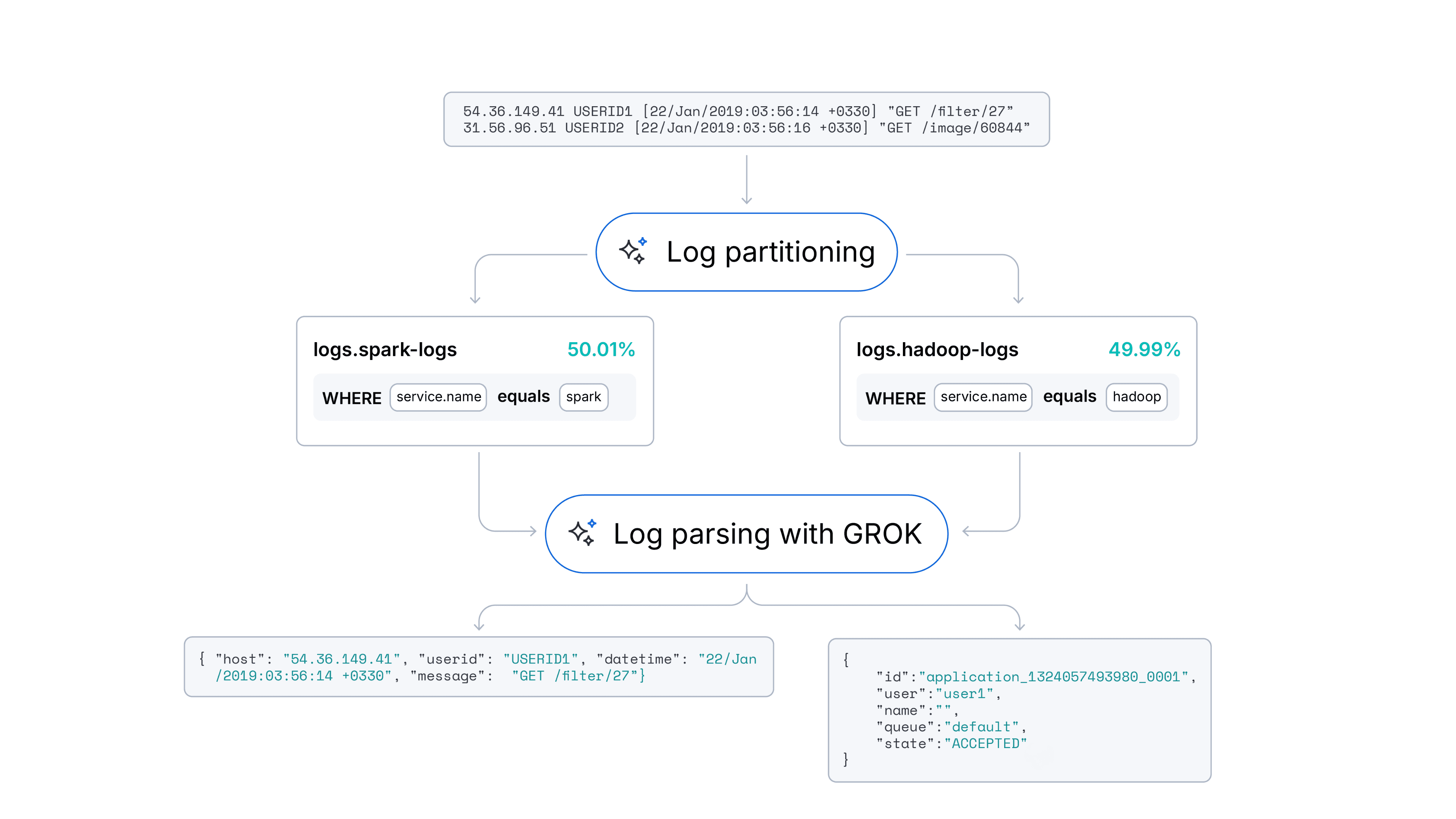
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
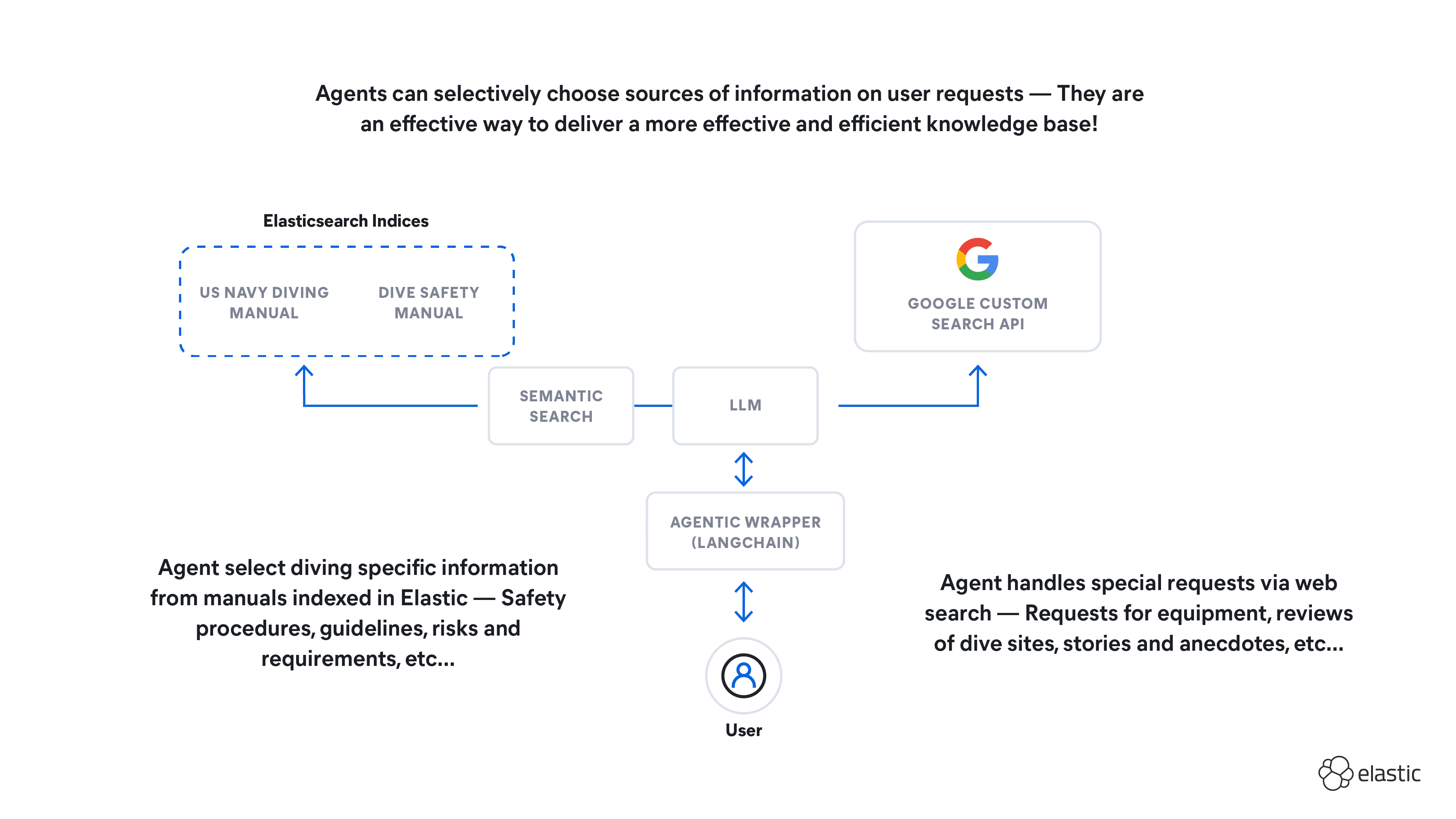
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.

December 29, 2025
Creating reliable agents with structured outputs in Elasticsearch
Explore what structured outputs are and how to leverage them in Elasticsearch to ground agents in the most relevant context for data contracts.
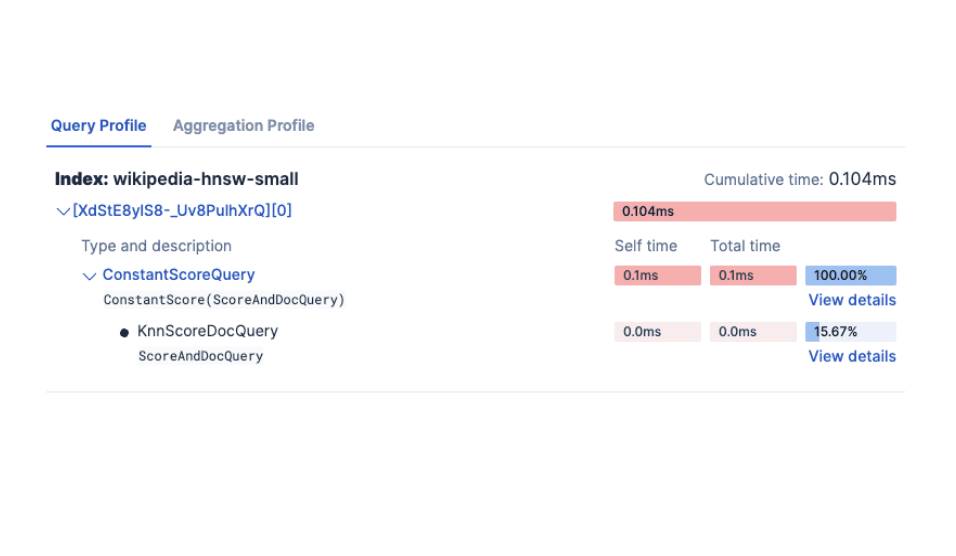
December 23, 2025
Comparing dense vector search performance with the Profile API in Elasticsearch
Learn how to use the Profile API in Elasticsearch to compare dense vector configurations and tune kNN performance with visual data from Kibana.
December 15, 2025
Getting started with Elastic Agent Builder and Strands Agents SDK
Learn how to create an agent with Elastic Agent Builder and then explore how to use the agent via the A2A protocol orchestrated with the Strands Agents SDK.