Elasticsearch is packed with new features to help you build the best search solutions for your use case. Learn how to put them into action in our hands-on webinar on building a modern Search AI experience. You can also start a free cloud trial or try Elastic on your local machine now.
Span queries have long been a tool for ordered and proximity search. These are especially useful for specific domains, such as legal or patent search. But the relatively new Interval queries actually fit this job much better. Unlike Span queries, Interval queries are true positional queries that score documents only based on positional proximity (expanded upon below).
Starting from Elasticsearch v8.16, we have brought Interval queries into parity with Span queries. Specifically:
- Interval queries now support "range" and "regexp" rules.
- Interval rules based on multiple terms similar to Span queries can expand up to
indices.query.bool.max_clause_countterms instead of previous128value.
Our future plan is to deprecate Span queries in favor of Intervals queries, which cover the same functional capability but do so in a more user-friendly way.
Advantages of Interval queries over Span queries
Interval queries rank documents based on the order and proximity of matching terms. Some advantages of Interval queries:
- True positional queries
- Grounded in academic research, based on the minimal interval semantics paper with proven algorithms that scale linearly with the number of positions
- Simpler syntax
- Slightly faster (no need of score calculations based on corpus statistics)
- Ability to use scripts for specialized use cases
Interval queries are true positional queries and only consider positional information while scoring documents (scores are inversely proportional to interval's length). This is unlike Span queries that also consider standard metrics like TF-IDF. Below is an example that illustrates how interval queries can do better ranking.
We want to find documents where the term "she" is near the term "sells". The desired ranking would return the 1st document followed by the 2nd document, as these terms occur closer to each other in the 1st document than in the second document.
But if we run a Span query, we will get a different ranking: [doc2, doc1], because Span queries in addition to proximity calculations also incorporate corpus stats such as TF and IDF metrics that will distort ranking purely by proximity.
In contrast, Interval queries calculate scores based on proximity and don't consider corpus stats and length of documents. We will get the desired ranking: [doc1, doc2].
This makes Interval queries an ideal choice for true proximity queries.
Interval queries allow to extract the proximity score as a signal for the overall relevance score. They are optimised to be mixed with other relevance signals like BM25, for instance:
Note that this could also be applied to rescoring: we can make the first pass with BM25 alone and then add a rescorer with BM25 + Intervals combination.
Note that if we need to model Span queries behaviour in matching and scoring by BM25 and proximity, we can do it by combining interval queries with BM25 queries as must clauses in a boolean query with appropriate boosts set.
Transition guide
Below we show ways to transition from the following Span queries to the equivalent Interval queries:
- span_containing
- span_field_masking
- span_first
- span_multi
- span_near
- span_not
- span_or
- span_term
- span_within
SPAN NEAR
SPAN FIRST
SPAN OR
SPAN CONTAINING
SPAN WITHIN
SPAN NOT
SPAN_MULTI
wildcard
fuzzy
prefix
regexp
range
span_field_masking
use use_field of Intervals
Conclusion
Interval queries is a powerful tool to do true positional search. Try them with expanded functionalities from 8.16 release.
Frequently Asked Questions
What are interval queries in Elasticsearch?
Elasticsearch interval queries are true positional queries that score documents only based on positional proximity.
What are the advantages of interval queries?
They are true positional queries, have a simpler syntax, are slightly faster (no need for score calculations based on corpus statistics) and provide the ability to use scripts for specialized use cases.
Related Content
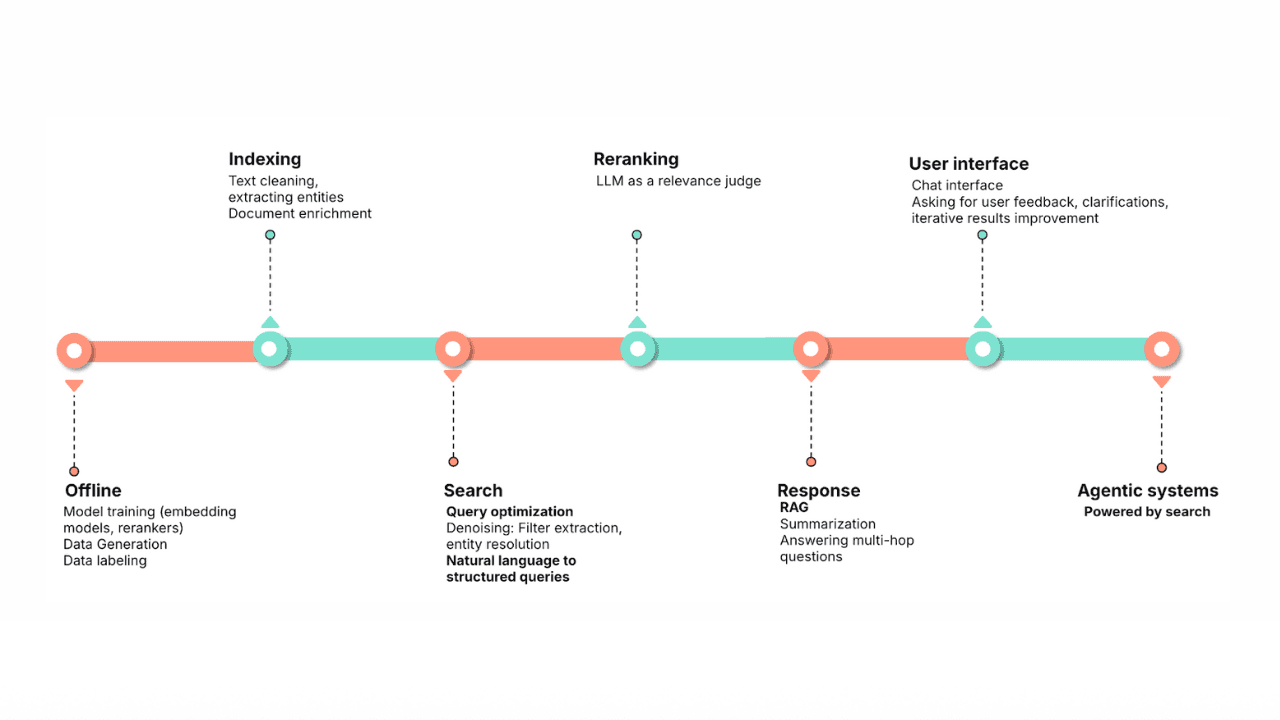
January 30, 2026
Query rewriting strategies for LLMs and search engines to improve results
Exploring query rewriting strategies and explaining how to use the LLM's output to boost the original query's results and maximize search relevance and recall.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
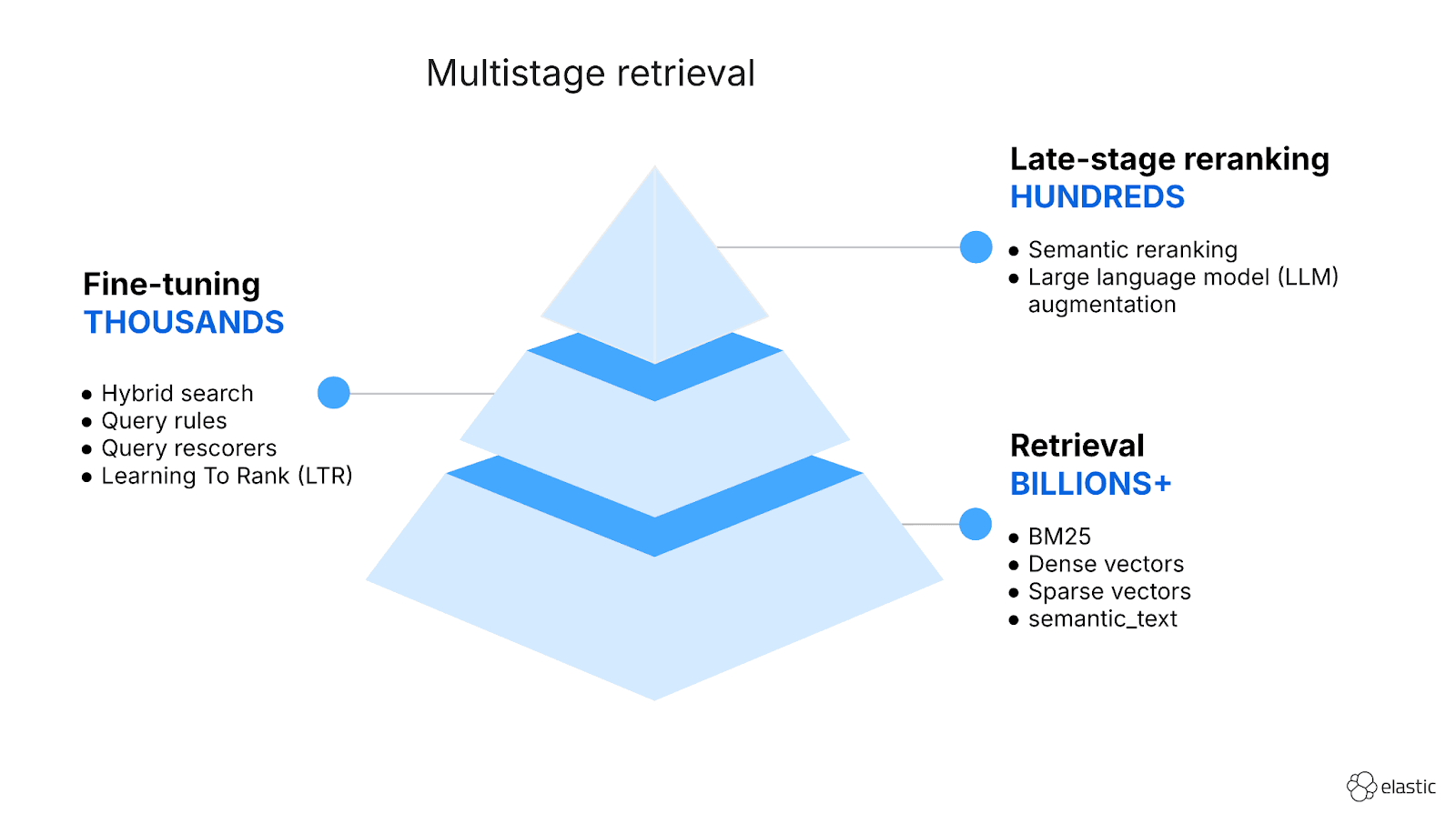
January 8, 2026
Hybrid search and multistage retrieval in ES|QL
Explore the multistage retrieval capabilities of ES|QL, using FORK and FUSE commands to integrate hybrid search with semantic reranking and native LLM completions.
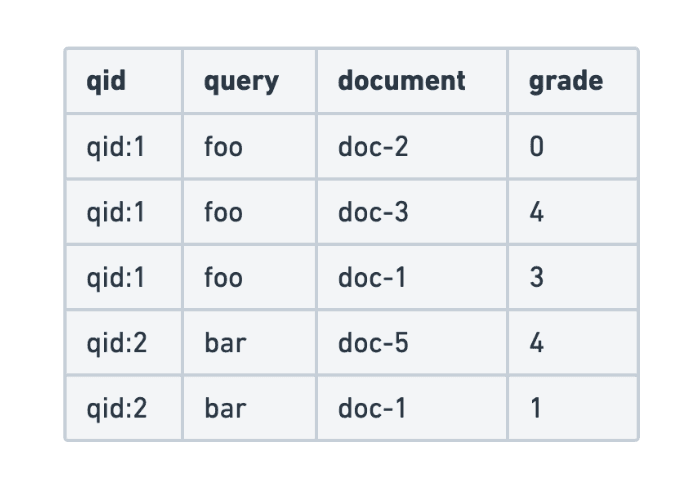
December 11, 2025
Evaluating search query relevance with judgment lists
Explore how to build judgment lists to objectively evaluate search query relevance and improve performance metrics such as recall, for scalable search testing in Elasticsearch.
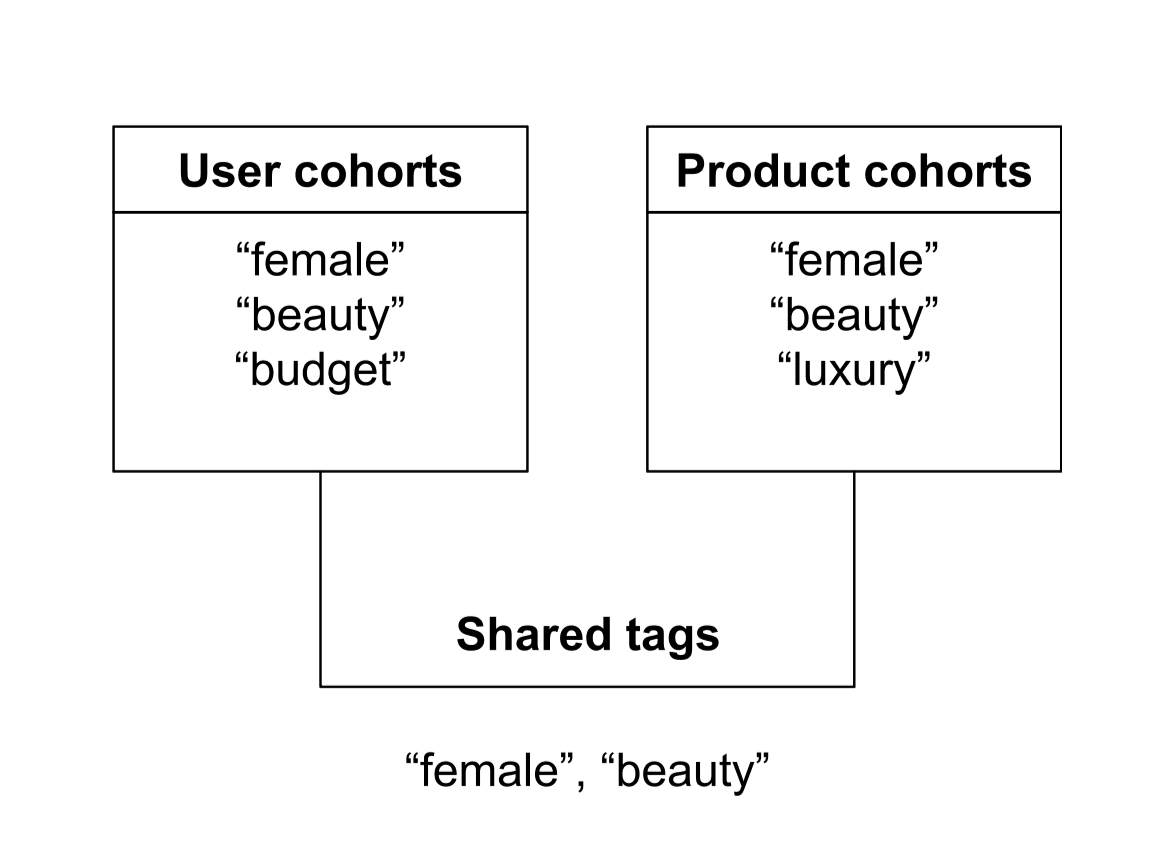
December 10, 2025
How to improve e-commerce search relevance with personalized cohort-aware ranking
Improve e-commerce search relevance with explainable, cohort-aware ranking in Elasticsearch. Learn how multiplicative boosting delivers stable, predictable personalization at query time.