Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
Elastic expanded their open inference API capabilities with the integration of IBM watsonx™ Slate embedding models, marking an important milestone in our ongoing partnership with the IBM watsonx team. With this, Elasticsearch users gain immediate, simplified access to IBM’s Slate family of models while the IBM watsonx community can take advantage of Elasticsearch’s comprehensive AI search tooling and proven vector database capabilities.
Elastic’s open inference API, now generally available, enables you to create endpoints and use machine learning models from providers like IBM watsonx™. IBM® watsonx™ AI and Data Platform includes core components and AI assistants designed to scale and accelerate AI's impact using trusted data. The platform features open-sourced Slate embedding models (slate-125m, slate-30m) for retrieval-augmented generation, semantic search, and document comparison, and also the Granite family of LLMs trained on trusted enterprise data.
In this blog, we will explain how to use IBM watsonx™ Slate text embeddings when building Search AI experiences with Elasticsearch vector database. Elastic now supports the usage of these text embeddings, with the new semantic_text field chunking incoming text by default to fit the token limits of the platform’s models.
Prerequisites & creation of inference endpoint
You will need an IBM Cloud® Databases for Elasticsearch deployment. You can provision one through the catalog, the Cloud Databases CLI plug-in, the Cloud Databases API, or Terraform. Once the account is set up successfully, you should land on the IBM cloud home page.
You can then provision a Kibana instance and connect to your Databases for Elasticsearch instance using the managed service model of IBM Cloud using these steps -
- Set the Admin Password for your Elasticsearch deployment.
- Install Docker to pull the Kibana container image and connect it to Databases for Elasticsearch.
Alternatively, if you prefer not to run Kibana locally or install Docker, you can deploy Kibana using IBM Cloud® Code Engine. For details, see the documentation on deploying Kibana with Code Engine and connecting it to your Databases for Elasticsearch instance.
Generate an API key
- Go to IBM watsonx.ai cloud and log in using your credentials. You will land on the welcome page.
- Go to the API keys page.
- Create an API key.
Steps in Elasticsearch
Using DevTools in Kibana, create an inference endpoint using the watsonxai service for text_embedding
You will receive the following response on the successful creation of the inference endpoint:
Generate embeddings
Below is an example of generating text_embedding for a single string
You will receive the following response as embeddings:
Additionally, let's look at a semantic_text mapping example
Create an index containing semantic_text field
Insert some documents to the created index
Next, run a query using semantic_text
You will receive the following response from the query
Conclusion
With the integration of IBM watsonx™ text embeddings, the Elasticsearch Open Inference API continues to empower developers with enhanced capabilities for building powerful and flexible AI-powered search experiences. Explore more supported encoder foundation models available with watsonx.ai.
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
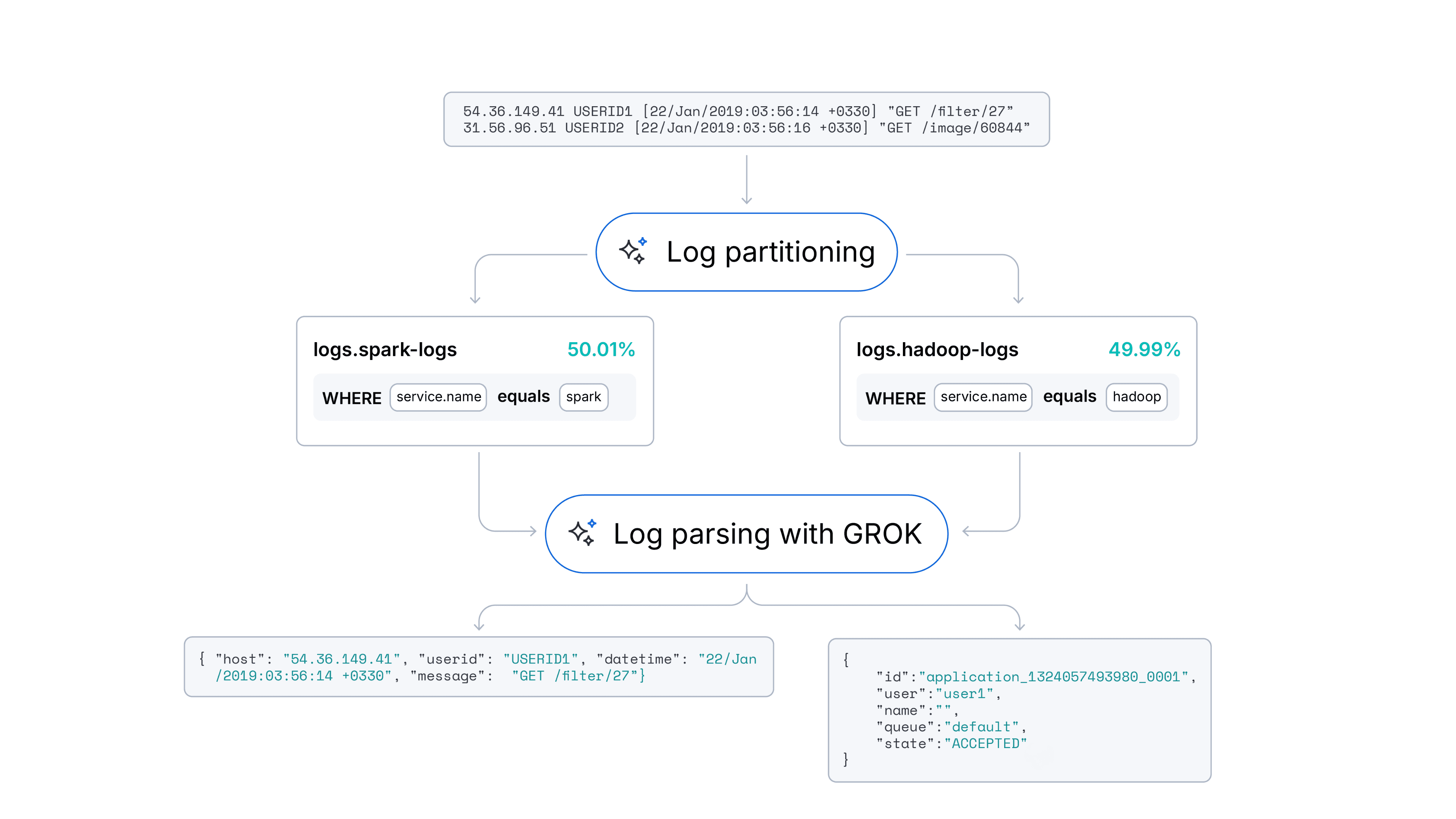
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
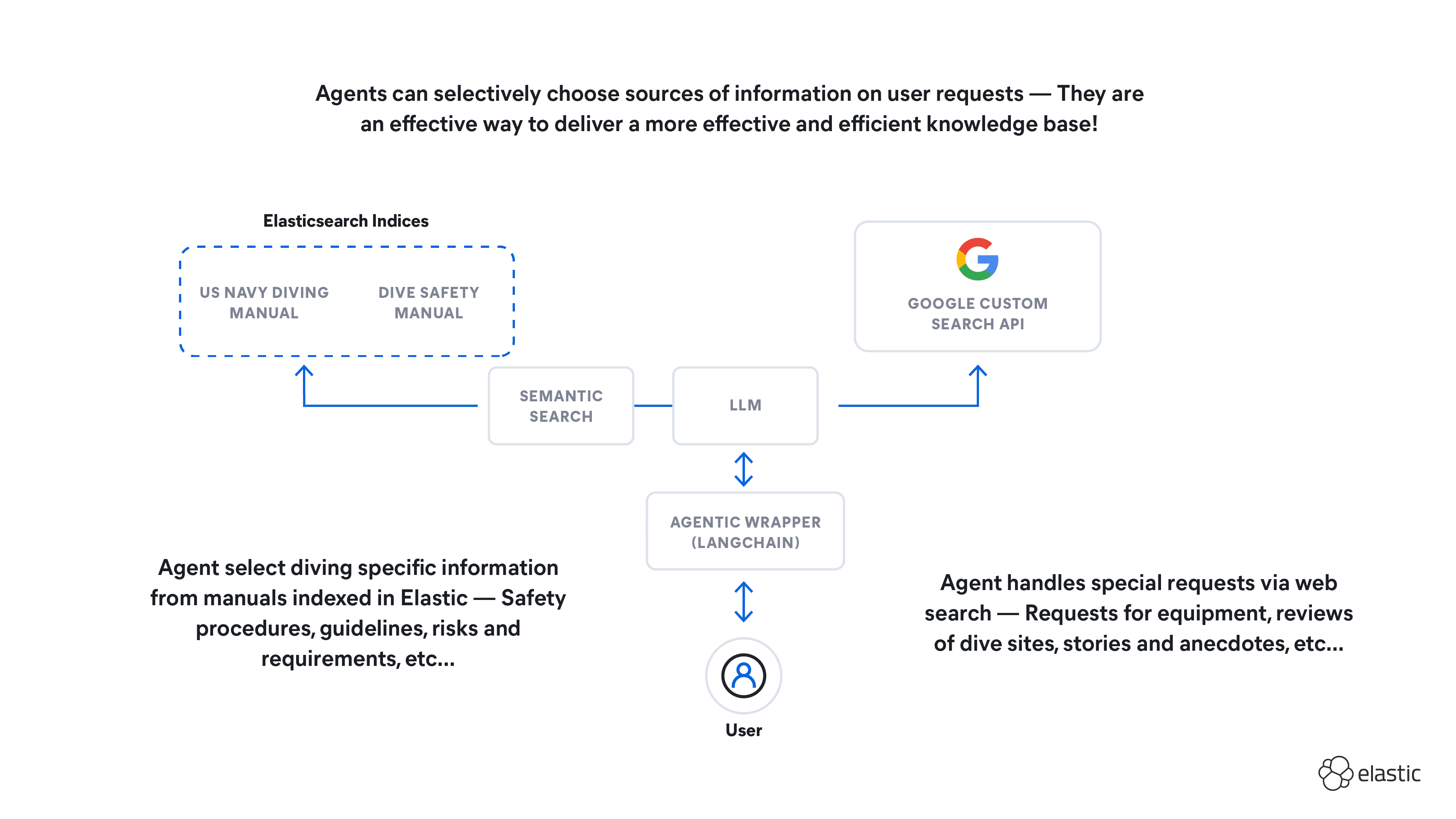
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.