Elasticsearch allows you to index data quickly and in a flexible manner. Try it free in the cloud or run it locally to see how easy indexing can be.
In part I of this series, we configured the Elastic Jira connector and indexed objects into Elasticsearch. In this second part, we'll review some best practices and advanced configurations to escalate the connector. These practices complement the current documentation and are to be used during the indexing phase.
Having a connector running was just the first step. When you want to index large amounts of data, every detail counts and there are many optimization points you can use when you index documents from Jira.

Jira connector optimization points
- Index only the documents you'll need by applying advanced sync filters
- Index only the fields you'll use
- Refine mappings based on your needs
- Automate Document Level security
- Offload attachment extraction
- Monitor the connector's logs
1. Index only the documents you'll need by applying advanced sync filters
By default, Jira sends all projects, issues, and attachments. If you're only interested in some of these or, for example, just issues "In Progress", we recommend not to index everything.
There are three instances to filter documents before we put them in Elasticsearch:
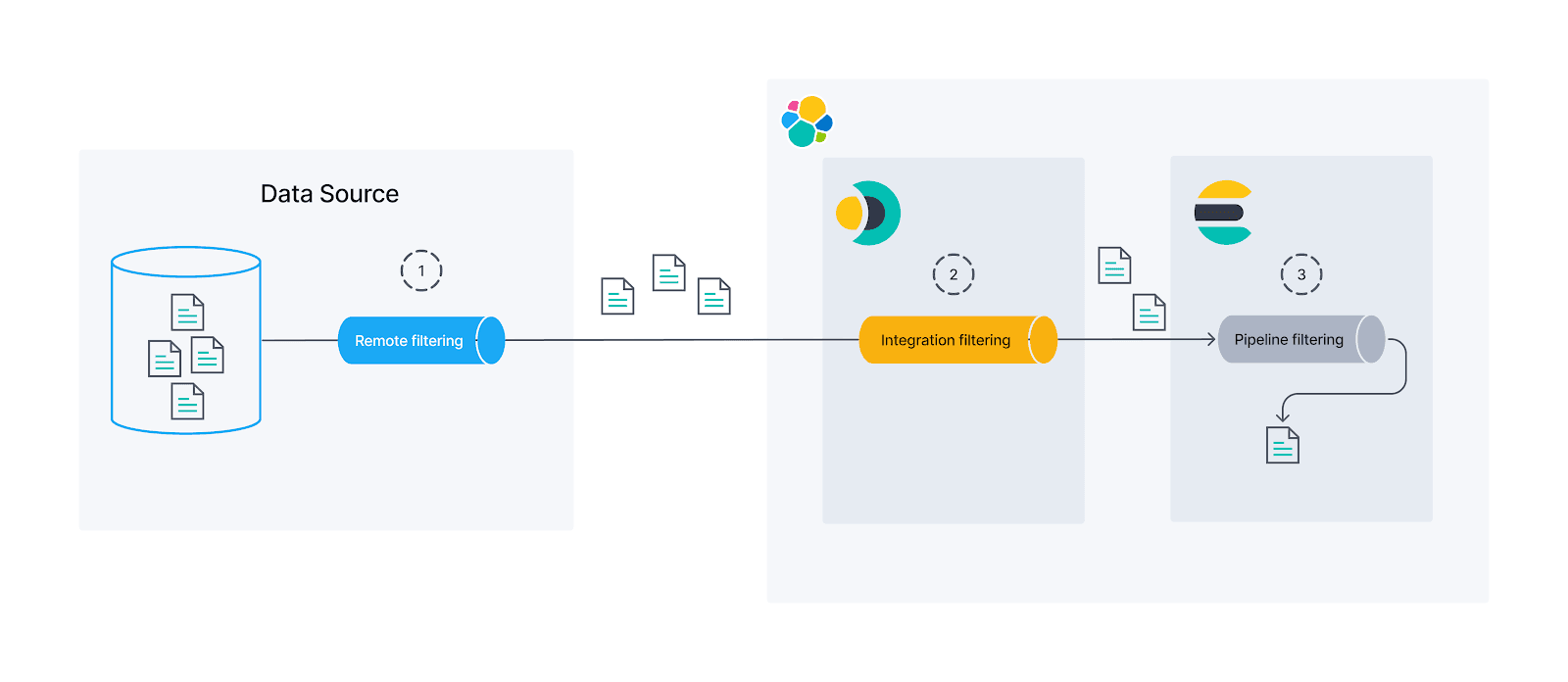
Remote: We can use a native Jira filter to get only what we need. This is the best option and you should try to use this option any time you can since with this, the documents don't even come out of the source before getting into Elasticsearch. We'll use advanced sync rules for this.
Integration: If the source does not have a native filter to provide what we need, we can still filter at an integration level before ingesting into Elasticearch by using basic sync rules.
Ingest Pipelines: The last option to handle data before indexing it is using Elasticsearch ingest pipelines. By using Painless scripts, we get great flexibility to filter or manipulate documents. The downside to this is that the data has already left the source and been through the connector, thus potentially putting a heavy load on the system and creating security issues.
Let's do a quick review of the Jira issues:
Note: We use "exists" query to only return the documents with the field we are filtering.
You can see there are many issues in "To Do" that we don't need:
To only get the issues "In Progress", we'll create an advanced sync rule using a JQL query (Jira query language):
Go to the connector and click on the sync rules tab and then on Draft Rules. Once inside, go to Advanced Sync Rules and add this:
Once the rule has been applied, run a Full Content Sync.
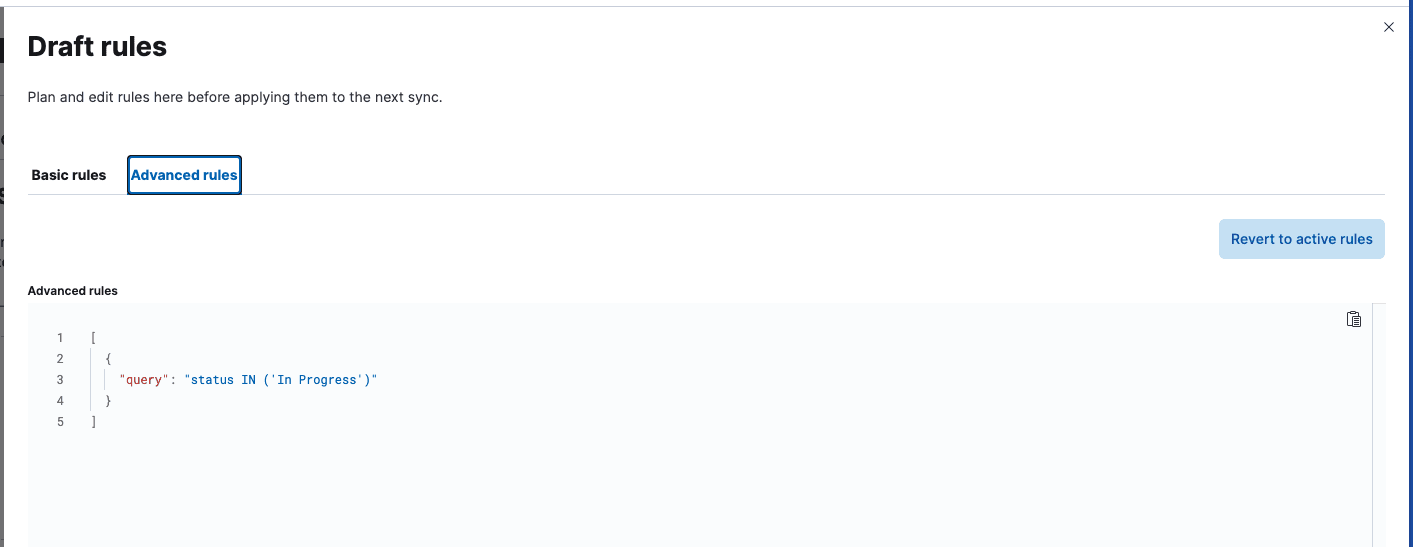

This rule will exclude all issues that are not "In Progress". You can check by running the query again:
Here's the new response:
2. Index only the fields you'll use
Now that we have only the documents we want, you can see that we're still getting a lot of fields that we don't need. We can hide them when we run the query by using _source, but the best option is to simply not index them.
To do so, we'll use the ingest pipelines. We can create a pipeline that drops all the fields we won't use. Let's say we only want this info from an issue:
- Assignee
- Title
- Status
We can create a new ingest pipeline that only gets those fields by using the ingest pipelines' Content UI:

Click on Copy and customize and then modify the pipeline called index-name@custom that should have just been created and empty. We can do it using Kibana DevTools console, running this command:
Let's remove the fields that we don't need and also move the ones that we need to the root of the document.
The remove processor with the keep parameter, will delete all the fields but the ones within the keep array from the document.
We can check this is working by running a simulation. Add the content of one of the documents from the index:
The response will be:
This looks much better! Now, let's run a full content sync to apply the changes.
3. Refine mappings based on your needs
The document is clean. However, we can optimize things more. We can go into “it depends” territory. Some mappings can work for your use case while others will not. The best way to find out is by experimenting.
Let's say we tested and got to this mappings design:
- assignee: full text search and filters
- summary: full text search
- status: filters and sorting
By default, the connector will create mappings using dynamic_templates that will configure all text fields for full-text search, filtering and sorting, which is a solid baseline but it can be optimized if we know what we want to do with our fields.
This is the rule:
Let's create different subfields for different purposes for all text fields. You can find additional information about the analyzers in the documentation.
To use these mappings you must:
- Create the index before you create the connector
- When you create the connector, select that index instead of creating a new one
- Create the ingest pipeline to get the fields you want
- Run a Full Content Sync*
*A Full Content Sync will send all documents to Elasticsearch. Incremental Sync will only send to Elasticsearch documents that changed after the last Incremental, or Full Content Sync. Both methods will fetch all the data from the data source.
Our optimized mappings are below:
For assignee, we kept the mappings as they are because we want this field to be optimized for both search and filters. For summary, we removed the “enum” keyword field because we don’t plan to filter on summaries. We mapped status as a keyword because we only plan to filter on that field.
Note: If you're not sure how you will use your fields, the baselines analyzers should be fine.
4. Automate Document Level security
In the first section, we learned to manually create API keys for a user and limit access based on it using Document Level Security (DLS). However, if you want to automatically create an API Key with permissions every time a user visits our site, you need to create a script that takes the request, generates an API Key using the user ID and then uses it to search in Elasticsearch.
Here's a reference file in Python:
You can call this create_api_key function on each API request to generate an API Key the user can use to query Elasticsearch in the subsequent requests. You can set expiration, and also arbitrary metadata in case you want to register some info about the user or the API that generated the key.
5. Offload attachment extraction
For content extraction, like extracting text from PDF and Powerpoint files, Elastic provides an out of the box service that works fine but has a size limitation.
By default, the extraction service of the native connectors supports 10MB max per attachment. If you have bigger attachments like a PDF with big images inside or you want to host the extraction service, Elastic offers a tool that lets you deploy your own extraction service.
This option is only compatible with Connector Clients, so if you're using a Native connector you will need to convert it to a connector client and host it in your own infrastructure.
Follow these steps to do it:
a. Configure custom extraction service and run it with Docker
EXTRACTION_SERVICE_VERSION you should use 0.3.x for Elasticsearch 8.15
b. Configure yaml con extraction service custom and run
Go to the connector client and add the following to the config.yml file to use the extraction service:
c. Follow steps to run connector client
After configuring you can run the connector client with the connector you want to use.
You can refer to the full process in the docs.
6. Monitor Connector's logs
It's important to have visibility of the connector's logs in case there's an issue and Elastic offers this out of the box.
The first step is to activate logging in the cluster. The recommendation is to send logs to an additional cluster (Monitoring deployment), but in a development environment, you can send the logs to the same cluster where you're indexing documents too.
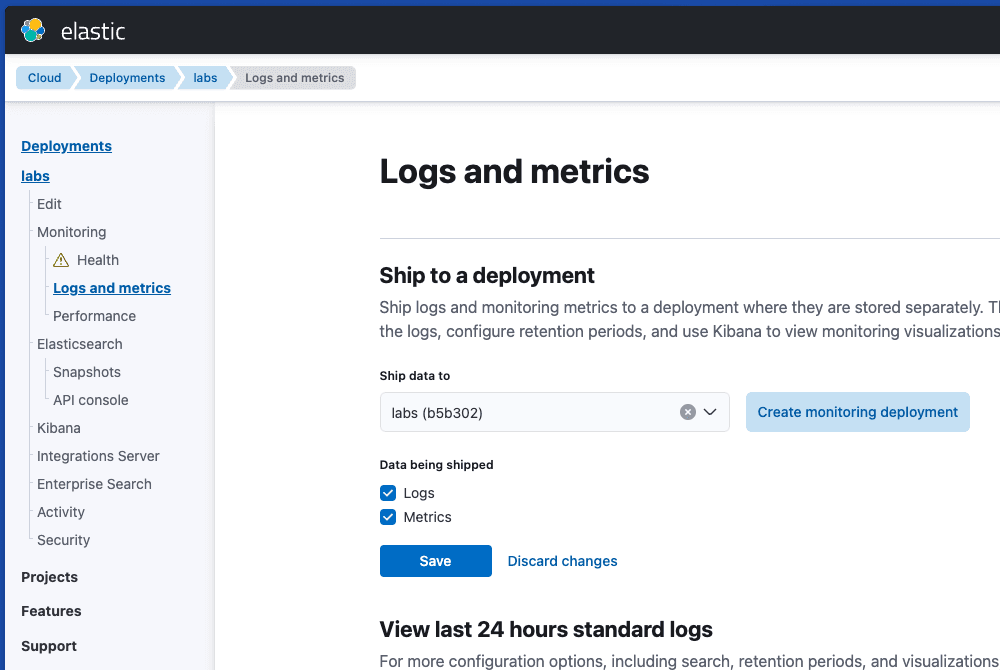
By default, the connector will send the logs to the elastic-cloud-logs-8 index. If you're using Cloud, you can check the logs in the new Logs Explorer:

Conclusion
In this article, we learned different strategies to consider when we take the next step in using a connector in a production environment. Optimizing resources, automating security, and cluster monitoring are key mechanisms to properly run a large-scale system.
How to optimize the Elastic Jira Connector
6 tips for optimizing the Elastic Jira Connector
1
Index only the documents you'll need by applying advanced sync filters
2
Index only the fields you'll use
3
Refine mappings based on your needs
4
Automate Document Level security
5
Offload attachment extraction
6
Monitor the connector's logs
Related Content
December 16, 2025
Reducing Elasticsearch frozen tier costs with Deepfreeze S3 Glacier archival
Learn how to leverage Deepfreeze in Elasticsearch to automate searchable snapshot repository rotation, retaining historical data and aging it into lower cost S3 Glacier tiers after index deletion.

September 22, 2025
Elastic Open Web Crawler as a code
Learn how to use GitHub Actions to manage Elastic Open Crawler configurations, so every time we push changes to the repository, the changes are automatically applied to the deployed instance of the crawler.

August 6, 2025
How to display fields of an Elasticsearch index
Learn how to display fields of an Elasticsearch index using the _mapping and _search APIs, sub-fields, synthetic _source, and runtime fields.

July 14, 2025
Run Elastic Open Crawler in Windows with Docker
Learn how to use Docker to get Open Crawler working in a Windows environment.

June 24, 2025
Ruby scripting in Logstash
Learn about the Logstash Ruby filter plugin for advanced data transformation in your Logstash pipeline.