Ingest data with Python on Elastic Cloud Enterprise
editIngest data with Python on Elastic Cloud Enterprise
editThis guide tells you how to get started with:
- Securely connecting to Elastic Cloud Enterprise with Python
- Ingesting data into your deployment from your application
- Searching and modifying your data on Elastic Cloud Enterprise
If you are an Python application programmer who is new to the Elastic Stack, this content can help you get started more easily.
Time required: 45 minutes
Prerequisites
editThese steps are applicable to your existing application. If you don’t have one, you can use the example included here to create one.
Get the elasticsearch packages
editpython -m pip install elasticsearch python -m pip install elasticsearch-async
Create the setup.py file
edit# Elasticsearch 7.x elasticsearch>=7.0.0,<8.0.0
Create a deployment
edit- Log into the Elastic Cloud Enterprise admin console.
- Click Create deployment.
- Give your deployment a name. You can leave all other settings at their default values.
- Click Create deployment and save your Elastic deployment credentials. You will need these credentials later on.
-
You also need the Cloud ID later on, as it simplifies sending data to Elastic Cloud Enterprise. Click on the deployment name from the Elastic Cloud Enterprise portal or the Deployments page and copy down the information under Cloud ID:
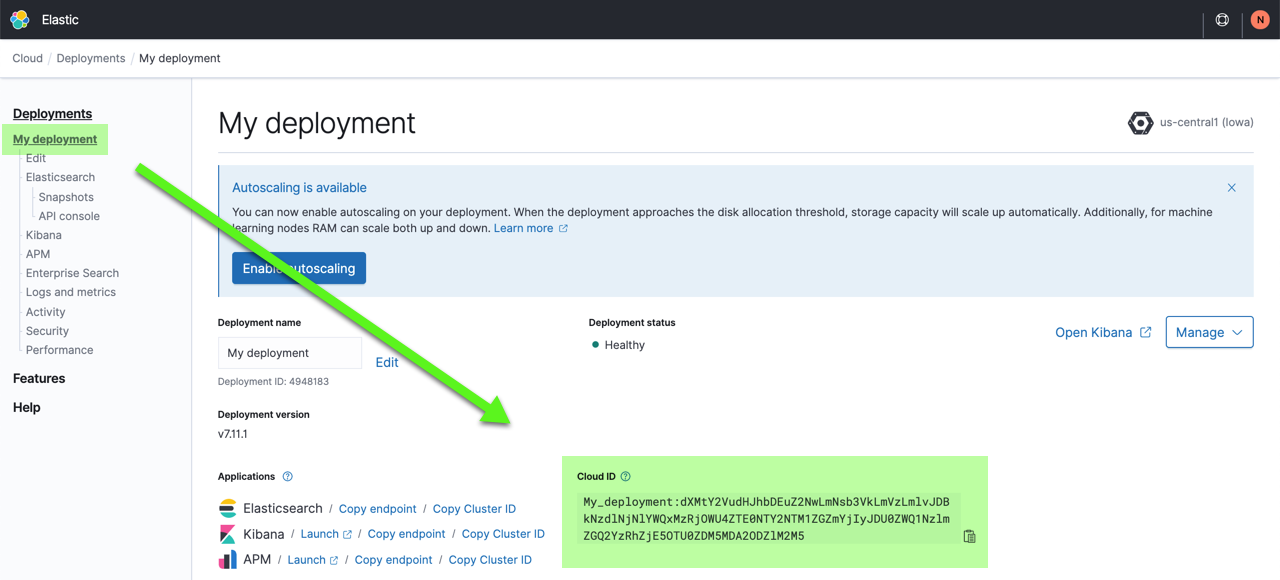
Connect securely
editWhen connecting to Elastic Cloud Enterprise you can use a Cloud ID to specify the connection details. You must pass the Cloud ID that you can find in the cloud console.
To connect to, stream data to, and issue queries with Elastic Cloud Enterprise, you need to think about authentication. Two authentication mechanisms are supported, API key and basic authentication. Here, to get you started quickly, we’ll show you how to use basic authentication, but you can also generate API keys as shown later on. API keys are safer and preferred for production environments.
Basic authentication
editFor basic authentication, use the same deployment credentials (username and password parameters) and Cloud ID you copied down earlier when you created your deployment. (If you did not save the password, you can
reset the password.
.)
You first need to create and edit an example.ini file with your deployment details:
[ELASTIC] cloud_id = DEPLOYMENT_NAME:CLOUD_ID_DETAILS user = elastic password = LONGPASSWORD ca = /path/to/your/elastic-ece-ca-cert.pem
|
This line is only used when you have a self signed certificate for your Elastic Cloud Enterprise proxy. If needed, specify the full path to the PEM formatted root cetificate (Root CA) used for the Elastic Cloud Enterprise proxy. You can retrieve the certificate chain from your ECE system by following the instructions in Get existing ECE security certificates. Save the final certificate in the chain to a file, in the example above the file is named |
The following examples are to be typed into the Python interpreter in interactive mode. The prompts have been removed to make it easier for you to copy the samples, the output from the interpreter is shown unmodified.
Import libraries and read in the configuration
edit❯ python3
Python 3.9.6 (default, Jun 29 2021, 05:25:02)
[Clang 12.0.5 (clang-1205.0.22.9)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
from elasticsearch import Elasticsearch, helpers
import configparser
from ssl import create_default_context
config = configparser.ConfigParser()
config.read('example.ini')
Output
edit['example.ini'] >>>
Instantiate the Elasticsearch connection
editcontext = create_default_context(cafile=config['ELASTIC']['ca'])
es = Elasticsearch(
cloud_id=config['ELASTIC']['cloud_id'],
scheme="https",
use_ssl=True,
verify_certs=False,
ssl_show_warn=False,
http_auth=(config['ELASTIC']['user'], config['ELASTIC']['password'])
)
You can now confirm that you have connected to the deployment by returning some information about the deployment:
es.info()
Output
edit{'name': 'instance-0000000000',
'cluster_name': '747ab208fb70403dbe3155af102aef56',
'cluster_uuid': 'IpgjkPkVQ5efJY-M9ilG7g',
'version': {'number': '7.15.0', 'build_flavor': 'default', 'build_type': 'docker', 'build_hash': '79d65f6e357953a5b3cbcc5e2c7c21073d89aa29', 'build_date': '2021-09-16T03:05:29.143308416Z', 'build_snapshot': False, 'lucene_version': '8.9.0', 'minimum_wire_compatibility_version': '6.8.0', 'minimum_index_compatibility_version': '6.0.0-beta1'},
'tagline': 'You Know, for Search'}
Ingest data
editAfter connecting to your deployment, you are ready to index and search data. Let’s create a new index, insert some quotes from our favorite characters, and then refresh the index so that it is ready to be searched. A refresh makes all operations performed on an index since the last refresh available for search.
Index a document
edites.index(
index='lord-of-the-rings',
document={
'character': 'Aragon',
'quote': 'It is not this day.'
})
Output
edit{'_index': 'lord-of-the-rings',
'_type': '_doc',
'_id': 'IanWEnwBg_mH2XweqDqg',
'_version': 1,
'result': 'created',
'_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 34, '_primary_term': 1}
Index another record
edites.index(
index='lord-of-the-rings',
document={
'character': 'Gandalf',
'quote': 'A wizard is never late, nor is he early.'
})
Output
edit{'_index': 'lord-of-the-rings',
'_type': '_doc',
'_id': 'IqnWEnwBg_mH2Xwezjpj',
'_version': 1,
'result': 'created',
'_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 35, '_primary_term': 1}
Index a third record
edites.index(
index='lord-of-the-rings',
document={
'character': 'Frodo Baggins',
'quote': 'You are late'
})
Output
edit{'_index': 'lord-of-the-rings',
'_type': '_doc',
'_id': 'I6nWEnwBg_mH2Xwe_Tre',
'_version': 1,
'result': 'created',
'_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 36, '_primary_term': 1}
Refresh the index
edites.indices.refresh(index='lord-of-the-rings')
Output
edit{'_shards': {'total': 2, 'successful': 1, 'failed': 0}}
When using the es.index API, the request automatically creates the lord-of-the-rings index, if it doesn’t exist already, as well as document IDs for each indexed document if they are not explicitly specified.
Search and modify data
editAfter creating a new index and ingesting some data, you are now ready to search. Let’s find what different characters have said things about being late:
result = es.search(
index='lord-of-the-rings',
query={
'match': {'quote': 'late'}
}
)
result['hits']['hits']
Output
edit[{'_index': 'lord-of-the-rings',
'_type': '_doc',
'_id': '2EkAzngB_pyHD3p65UMt',
'_score': 0.5820575,
'_source': {'character': 'Frodo Baggins', 'quote': 'You are late'}},
{'_index': 'lord-of-the-rings',
'_type': '_doc',
'_id': '10kAzngB_pyHD3p65EPR',
'_score': 0.37883914,
'_source': {'character': 'Gandalf',
'quote': 'A wizard is never late, nor is he early.'}}]
The search request returns content of documents containing late in the quote field, including document IDs that were automatically generated.
You can make updates to specific documents using document IDs. Let’s add a birthplace for our character:
|
The example update above uses the field |
Output
edites.get(index='lord-of-the-rings', id='2EkAzngB_pyHD3p65UMt')
{'_index': 'lord-of-the-rings',
'_type': '_doc',
'_id': '2EkAzngB_pyHD3p65UMt',
'_version': 2,
'_seq_no': 3,
'_primary_term': 1,
'found': True,
'_source': {'character': 'Frodo Baggins',
'quote': 'You are late',
'birthplace': 'The Shire'}}
For frequently used API calls with the Python client, see Examples.
Switch to API key authentication
editTo get started, authentication to Elasticsearch used the elastic
superuser and password, but an API key is much safer and a best practice for production.
In the example that follows, an API key is created with the cluster monitor privilege which gives read-only access for determining the cluster state. Some additional privileges also allow create_index, write, read, and manage operations for the specified index. The index manage privilege is added to enable index refreshes.
The easiest way to create this key is in the API console for your deployment. Select the deployment name and go to Elasticsearch > API console:
POST /_security/api_key
{
"name": "python_example",
"role_descriptors": {
"python_read_write": {
"cluster": ["monitor"],
"index": [
{
"names": ["test-index"],
"privileges": ["create_index", "write", "read", "manage"]
}
]
}
}
}
The output is:
edit{
"id" : "API_KEY_ID",
"name" : "python_example",
"api_key" : "API_KEY_DETAILS"
}
Edit the example.ini file you created earlier and add the id and api_key you just created. You should also remove the lines for user and password you added earlier after you have tested the api_key, and consider changing the elastic password using the Cloud UI.
[DEFAULT] cloud_id = DEPLOYMENT_NAME:CLOUD_ID_DETAILS apikey_id = API_KEY_ID apikey_key = API_KEY_DETAILS
You can now use the API key in place of a username and password. The client connection becomes:
es = Elasticsearch(
cloud_id=config['DEFAULT']['cloud_id'],
api_key=(config['DEFAULT']['apikey_id'], config['DEFAULT']['apikey_key']),
)
See Create API key API to learn more about API Keys and Security privileges to understand which privileges are needed. If you are not sure what the right combination of privileges for your custom application is, you can enable audit logging on Elasticsearch to find out what privileges are being used. To learn more about how logging works on Elastic Cloud Enterprise, see Monitoring Elastic Cloud deployment logs and metrics.
For more information on refreshing an index, searching, updating, and deleting, see the elasticsearch-py examples.
Best practices
edit- Security
-
When connecting to Elastic Cloud Enterprise, the client automatically enables both request and response compression by default, since it yields significant throughput improvements. Moreover, the client also sets the SSL option
secureProtocoltoTLSv1_2_methodunless specified otherwise. You can still override this option by configuring it.Do not enable sniffing when using Elastic Cloud Enterprise, since the nodes are behind a load balancer. Elastic Cloud Enterprise takes care of everything for you. Take a look at Elasticsearch sniffing best practices: What, when, why, how if you want to know more.
- Schema
- When the above example code was run an index mapping was created automatically. The field types were selected by Elasticsearch based on the content seen when the first record was ingested, and updated as new fields appeared in the data. It would be more efficient to specify the fields and field types in advance to optimize performance. See the Elastic Common Schema documentation and Field Type documentation when you are designing the schema for your production use cases.
- Ingest
-
For more advanced scenarios, Bulk helpers gives examples for the
bulkAPI that makes it possible to perform multiple operations in a single call. If you have a lot of documents to index, using bulk to batch document operations is significantly faster than submitting requests individually.