Get hands-on with Elasticsearch: Dive into our sample notebooks, start a free cloud trial, or try Elastic on your local machine now.
The LangChain4j framework was created in 2023 with this target:
The goal of LangChain4j is to simplify integrating LLMs into Java applications.
LangChain4j is providing a standard way to:
- create embeddings (vectors) from a given content, let say a text for example
- store embeddings in an embedding store
- search for similar vectors in the embedding store
- discuss with LLMs
- use a chat memory to remember the context of a discussion with an LLM
This list is not exhaustive and the LangChain4j community is always implementing new features.
This post will cover the first main parts of the framework.
Adding LangChain4j OpenAI to our project
Like in all Java projects, it's just a matter of dependencies. Here we will be using Maven but the same could be achieved with any other dependency manager.
As a first step to the project we want to build here, we will be using OpenAI so we just need to add the langchain4j-open-ai artifact:
For the rest of the code we will be using either our own API key, which you can get by registering for an account with OpenAI, or the one provided by LangChain4j project for demo purposes only:
We can now create an instance of our ChatLanguageModel:
And finally we can ask a simple question and get back the answer:
The given answer might be something like:
If you'd like to run this code, please check out the Step1AiChatTest.java class.
Providing more context with langchain4j
Let's add the langchain4j artifact:
This one is providing a toolset which can help us build a more advanced LLM integration to build our assistant. Here we will just create an Assistant interface which provides the chat method which will be calling automagically the ChatLanguageModel we defined earlier:
We just have to ask LangChain4j AiServices class to build an instance for us:
And then call the chat(String) method:
This is having the same behavior as before. So why did we change the code? In the first place, it's more elegant but more than that, you can now give some instructions to the LLM using simple annotations:
This is now giving:
If you'd like to run this code, please check out the Step2AssistantTest.java class.
Switching to another LLM: langchain4j-ollama
We can use the great Ollama project. It helps to run a LLM locally on your machine.
Let's add the langchain4j-ollama artifact:
As we are running the sample code using tests, let's add Testcontainers to our project:
We can now start/stop Docker containers:
We "just" have to change the model object to become an OllamaChatModel instead of the OpenAiChatModel we used previously:
Note that it could take some time to pull the image with its model, but after a while, you could get the answer:
Better with memory
If we ask multiple questions, by default the system won't remember the previous questions and answers. So if we ask after the first question "When was he born?", our application will answer:
Which is nonsense. Instead, we should use Chat Memory:
Running the same questions now gives a meaningful answer:
Conclusion
In the next post, we will discover how we can ask questions to our private dataset using Elasticsearch as the embedding store. That will give us a way to transform our application search to the next level.
Frequently Asked Questions
What is LangChain4j?
LangChain4j (LangChain for Java) is a powerful toolset to build your RAG application in plain Java.
Related Content
January 2, 2026
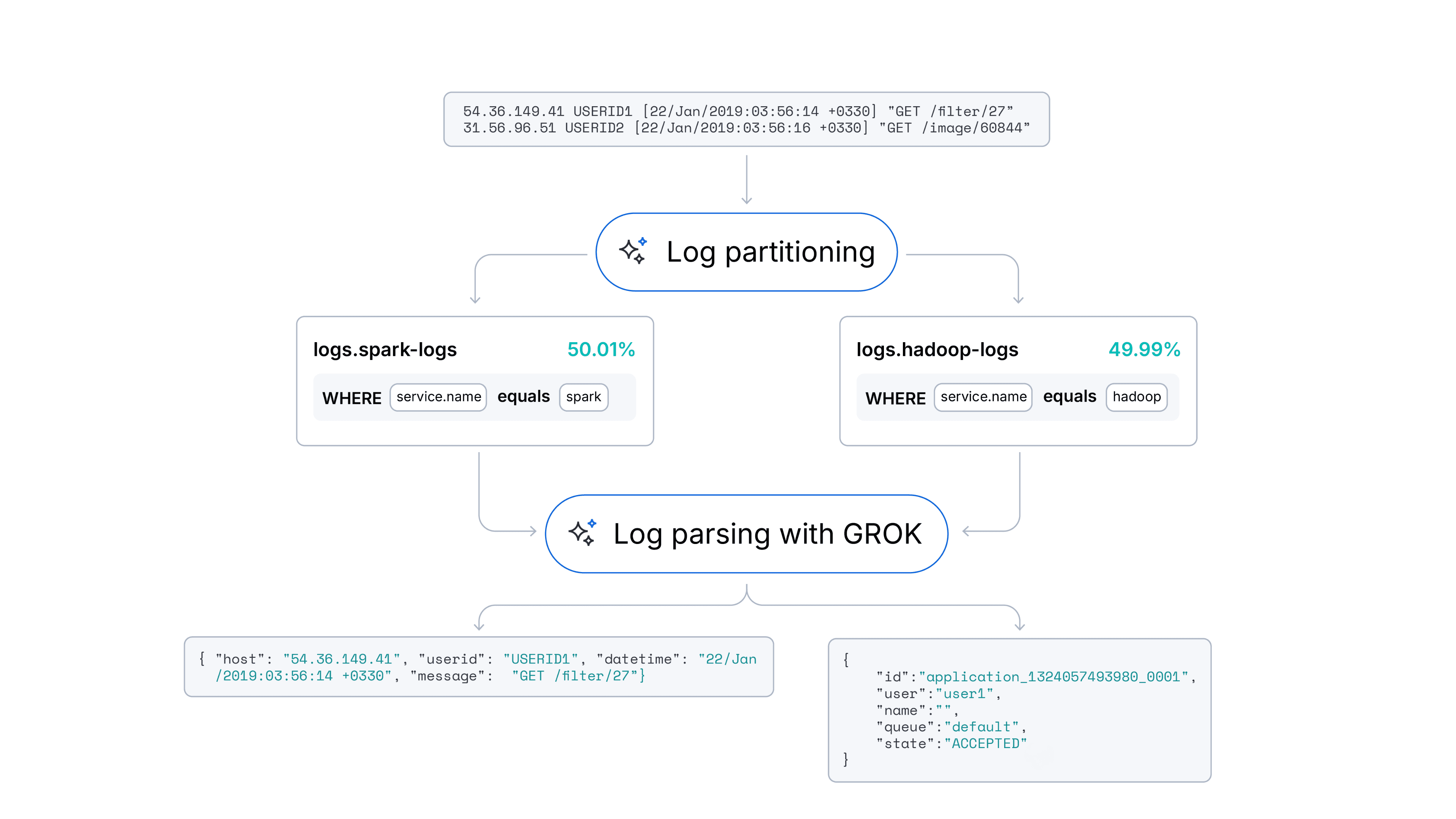
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
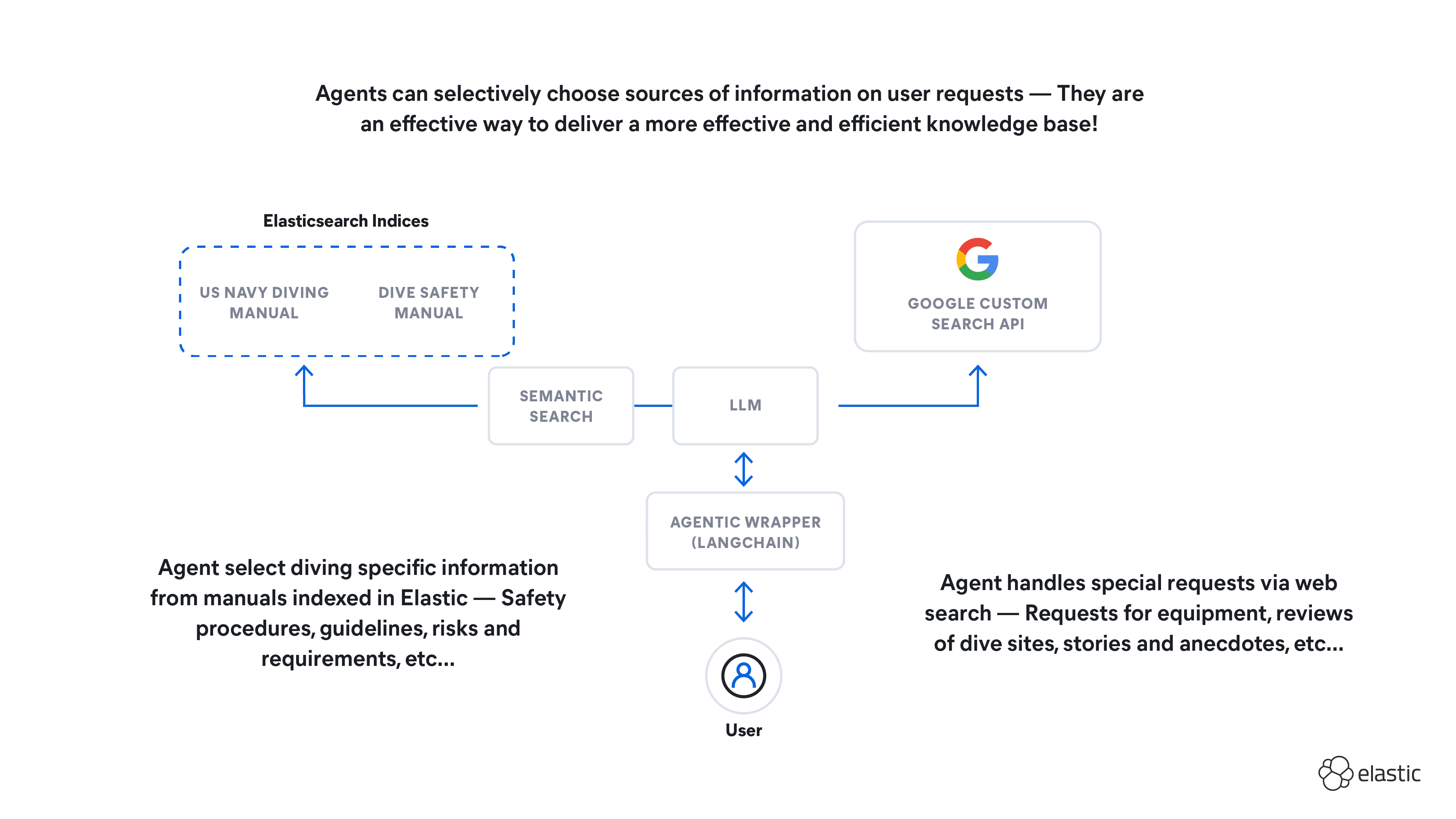
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.

December 29, 2025
Creating reliable agents with structured outputs in Elasticsearch
Explore what structured outputs are and how to leverage them in Elasticsearch to ground agents in the most relevant context for data contracts.
December 15, 2025
Getting started with Elastic Agent Builder and Strands Agents SDK
Learn how to create an agent with Elastic Agent Builder and then explore how to use the agent via the A2A protocol orchestrated with the Strands Agents SDK.

November 25, 2025
Top Elastic Agent Builder projects and learnings from Cal Hacks 12.0
Explore the top Elastic Agent Builder projects from Cal Hacks 12.0 and dive into our technical takeaways on Serverless, ES|QL, and agent architectures.