Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
This project allows you to interact directly with a GitHub repository and leverage semantic search to understand the codebase. You'll learn how to ask specific questions about the repository's code and receive meaningful, context-aware responses. You can follow the GitHub code here.
Key considerations
- Quality of data: The output is only as good as the input—ensure your data is clean and well-structured.
- Chunk size: Proper chunking of data is crucial for optimal performance.
- Performance evaluation: Regularly assess the performance of your RAG-based application.
Components
- Elasticsearch: Serves as the vector database for efficient storage and retrieval of embeddings.
- LlamaIndex: A framework for building applications powered by LLM.
- OpenAI: Used for both the LLM and generating embeddings.
Architecture
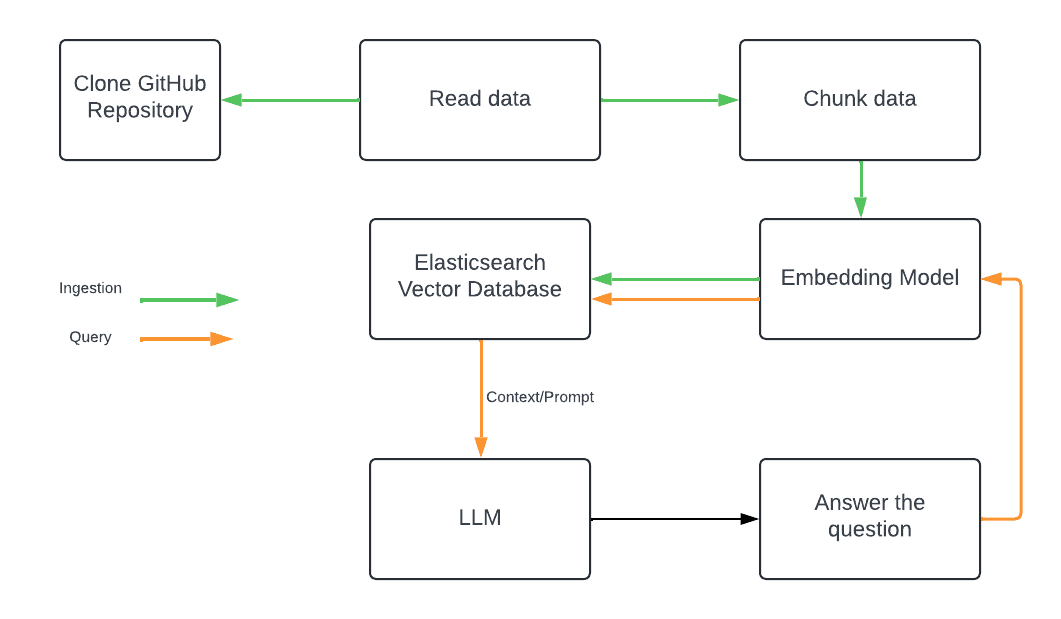
Ingestion
The process starts by cloning a GitHub repository locally to the /tmp directory. The SimpleDirectoryReader is then used to load the cloned repository for indexing, the documents are split into chunks based on file type, utilizing CodeSplitter for code files, along with JSON, Markdown, and SentenceSplitters for other formats, see:
If you want to add more support language into this code, you can just add a new parser and extension to the parsers_and_extensions list. After parsing the nodes, embeddings are generated using the text-embedding-3-large model and stored in Elasticsearch. The embedding model is declared using the Setting bundle, which a global variable:
This is then utilized in the main function as part of the Ingest Pipeline. Since it's a global variable, there's no need to call it again during the ingestion process:
The code block above starts by parsing the documents into smaller chunks (nodes) and then initializes a connection to Elasticsearch. The IngestionPipeline is created with the specified Elasticsearch vector store, and the pipeline is executed to process the nodes and store their embeddings in Elasticsearch, while displaying the progress during the process. At this point we should have your data indexed in Elasticsearch with the embeddings generated and stored. Below is one example of how the document looks like in ESS:
Query
Once the data is indexed, you can query the Elasticsearch index to ask questions about the codebase. The query.py script allows you to interact with the indexed data and ask questions about the codebase. It retrieves a query input from the user, creates an embedding using the same OpenAIEmbedding model used in the index.py, and sets up a query engine with the VectorStoreIndex loaded from the Elasticsearch vector store. The query engine uses similarity search, retrieving the top 3 most relevant documents based on the query's similarity to the stored embeddings. The results are summarized in a tree-like format using response_mode="tree_summarize", you can see the code snippet below:
Installation
1. Clone the repository:
2. Install required libraries:
3. Set up environment variables: Update the .env file with your Elasticsearch credentials and the target GitHub repository details (eg, GITHUB_TOKEN, GITHUB_OWNER, GITHUB_REPO, GITHUB_BRANCH, ELASTIC_CLOUD_ID, ELASTIC_USER, ELASTIC_PASSWORD, ELASTIC_INDEX).
Here's one example of the .env file:
Usage
1. Index your data and create the embeddings by running:
2. Ask questions about your codebase by running:
Example:
Questions you might want to ask:
- Give me a detailed description of what are the main functionalities implemented in the code?
- How does the code handle errors and exceptions?
- Could you evaluate the test coverage of this codebase and also provide detailed insights into potential enhancements to improve test coverage significantly?
Evaluation
The evaluation.py code processes documents, generates evaluation questions based on the content, and then evaluates the responses for relevancy (Whether the response is relevant to the question) and faithfulness (Whether the response is faithful to the source content) using a LLM. Here’s a step-by-step guide on how to use the code:
You can run the code without any parameters, but the example above demonstrates how to use the parameters. Here's a breakdown of what each parameter does:
Document processing:
- --num_documents 5: The script will process a total of 5 documents.
- --skip_documents 2: The first 2 documents will be skipped, and the script will start processing from the 3rd document onward. So, it will process documents 3, 4, 5, 6, and 7.
Question generation:
After loading the documents, the script will generate a list of questions based on the content of these documents.
- --num_questions 3: Out of the generated questions, only 3 will be processed.
- --skip_questions 1: The script will skip the first question in the list and process questions starting from the 2nd question.
- --process_last_questions: Instead of processing the first 3 questions after skipping the first one, the script will take the last 3 questions in the list.
Now what?
Here are a few ways you can utilize this code:
- Gain insights into a specific GitHub repository by asking questions about the code, such as locating functions or understanding how parts of the code work.
- Build a multi-agent RAG system that ingests GitHub PRs and issues, enabling automatic responses to issues and feedback on PRs.
- Combine your logs and metrics with the GitHub code in Elasticsearch to create a Production Readiness Review using RAG, helping assess the maturity of your services.
Happy RAG!
Related Content

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.

December 29, 2025
Creating reliable agents with structured outputs in Elasticsearch
Explore what structured outputs are and how to leverage them in Elasticsearch to ground agents in the most relevant context for data contracts.