From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into sample notebooks on GitHub to try something new. You can also start your free trial or run Elasticsearch locally today.
This is Part 1 of our exploration into Advanced RAG Techniques. Click here for Part 2!
The recent paper Searching for Best Practices in Retrieval-Augmented Generation empirically assesses the efficacy of various RAG enhancing techniques, with the goal of converging on a set of best-practices for RAG.
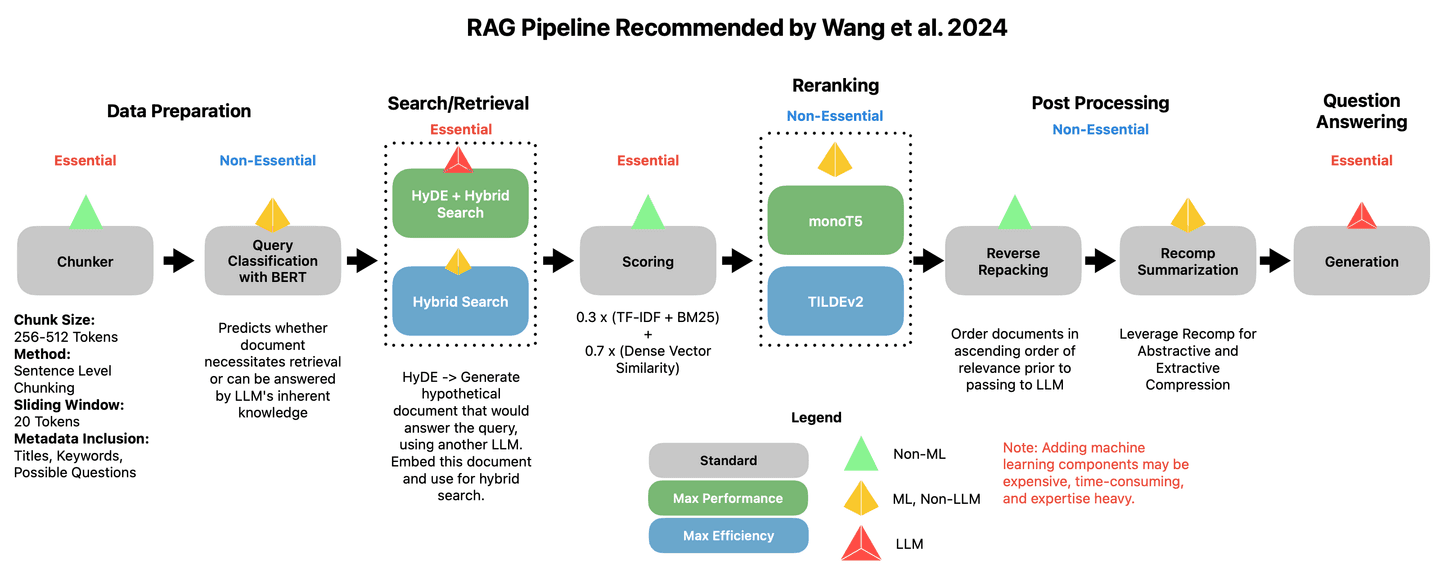
The RAG pipeline recommended by Wang and colleagues.
We'll implement a few of these proposed best-practices, namely the ones which aim to improve the quality of search (Sentence Chunking, HyDE, Reverse Packing).
For brevity, we will omit those techniques focused on improving efficiency (Query Classification and Summarization).
We will also implement a few techniques that were not covered, but which I personally find useful and interesting (Metadata Inclusion, Composite Multi-Field Embeddings, Query Enrichment).
Finally, we'll run a short test to see if the quality of our search results and generated answers has improved versus the baseline. Let's get to it!
RAG overview
RAG aims to enhance LLMs by retrieving information from external knowledge bases to enrich generated answers. By providing domain-specific information, LLMs can be quickly adapted for use cases outside the scope of their training data; significantly cheaper than fine-tuning, and easier to keep up-to-date.
Measures to improve the quality of RAG typically focus on two tracks:
- Enhancing the quality and clarity of the knowledge base.
- Improving the coverage and specificity of search queries.
These two measures will achieve the goal of improving the odds that the LLM has access to relevant facts and information, and is thus less likely to hallucinate or draw upon its own knowledge - which may be outdated or irrelevant.
The diversity of methods is difficult to clarify in just a few sentences. Let's go straight to implementation to make things clearer.

Figure 1: The RAG pipeline used by the author.
Table of contents
Set-up
All code may be found in the Searchlabs repo.
First things first. You will need the following:
- An Elastic Cloud Deployment
- An LLM API - We are using a GPT-4o deployment on Azure OpenAI in this notebook
- Python Version 3.12.4 or later
We will be running all the code from the main.ipynb notebook.
Go ahead and git clone the repo, navigate to supporting-blog-content/advanced-rag-techniques, then run the following commands:
Once that's done, create a .env file and fill out the following fields (Referenced in .env.example). Credits to my co-author, Claude-3.5, for the helpful comments.
Next, we'll choose the document to ingest, and place it in the documents folder. For this article, we'll be using the Elastic N.V. Annual Report 2023. It's a pretty challenging and dense document, perfect for stress testing our RAG techniques.

Elastic Annual Report 2023
Now we're all set, let's go to ingestion. Open main.ipynb and execute the first two cells to import all packages and intialize all services.
Ingesting, processing, and embedding documents
Data ingestion
- Personal note: I am stunned by LlamaIndex's convenience. In the olden days before LLMs and LlamaIndex, ingesting documents of various formats was a painful process of collecting esoteric packages from all over. Now it's reduced to a single function call. Wild.
The SimpleDirectoryReader will load every document in the directory_path. For .pdf files, it returns a list of document objects, which I convert to Python dictionaries because I find them easier to work with.
Each dictionary contains the key content in the text field. It also contains useful metadata such as page number, filename, file size, and type.
Sentence-level, token-wise chunking
The first thing to do is reduce our documents to chunks of a standard length (to ensure consistency and manageability). Embedding models have unique token limits (maximum input size they can process). Tokens are the basic units of text that models process. To prevent information loss (truncation or omission of content), we should provide text that does not exceed those limits (by splitting longer texts into smaller segments).
Chunking has a significant impact on performance. Ideally, each chunk would represent a self-contained piece of information, capturing contextual information about a single topic. Chunking methods include word-level chunking, where documents are split by word count, and semantic chunking which uses an LLM to identify logical breakpoints.
Word-level chunking is cheap, fast, and easy, but runs a risk of splitting sentences and thus breaking context. Semantic chunking gets slow and expensive, especially if you're dealing with documents like the 116-page Elastic Annual Report.
Let's choose a middleground approach. Sentence level chunking is still simple, but can preserve context more effectively than word-level chunking while being significantly cheaper and faster. Additionally, we'll implement a sliding window to capture some of the surrounding context, and alleviate the impact of splitting paragraphs.
The Chunker class takes in the embedding model's tokenizer to encode and decode text. We'll now build chunks of 512 tokens each, with an overlap of 20 tokens. To do this, we'll split the text into sentences, tokenize those sentences, and then add the tokenized sentences to our current chunk until we cannot add more without breaching our token limit.
Finally, decode the sentences back to the original text for embedding, storing it in a field called original_text. Chunks are stored in a field called chunk. To reduce noise (aka useless documents), we will discard any documents smaller than 50 tokens in length.
Let's run it over our documents:
And get back chunks of text that look like this:
Metadata inclusion and generation
We've chunked our documents. Now it's time to enrich the data. I want to generate or extract additional metadata. This additional metadata can be used to influence and enhance search performance.
We'll define a DocumentEnricher class, whose role is to take in a list of documents (Python dictionaries), and a list of processor functions. These functions will run over the documents' original_text column, and store their outputs in new fields.
First, we extract keyphrases using TextRank. TextRank is a graph-based algorithm that extracts key phrases and sentences from text by ranking their importance based on the relationships between words.
Next, we'll generate potential_questions using GPT-4o.
Finally, we'll extract entities using Spacy.
Since the code for each of these is quite lengthy and involved, I will refrain from reproducing it here. If you are interested, the files are marked in the code samples below.
Let's run the data enrichment:
And take a look at the results:
Keyphrases extracted by TextRank
These keyphrases are a stand-in for the chunk's core topics. If a query has to do with cybersecurity, this chunk's score will be boosted.
Potential questions generated by GPT-4o
These potential questions may directly match with user queries, offering a boost in score. We prompt GPT-4o to generate questions which can be answered using the information found in the current chunk.
Entities extracted by Spacy
These entities serve a similar purpose to the keyphrases, but capture organizations' and individuals' names, which keyphrase extraction may miss.
Composite multi-field embeddings
Now that we have enriched our documents with additional metadata, we can leverage this information to create more robust and context-aware embeddings.
Let's review our current point in the process. We've got four fields of interest in each document.
Each field represents a different perspective on the document's context, potentially highlighting a key area for the LLM to focus on.
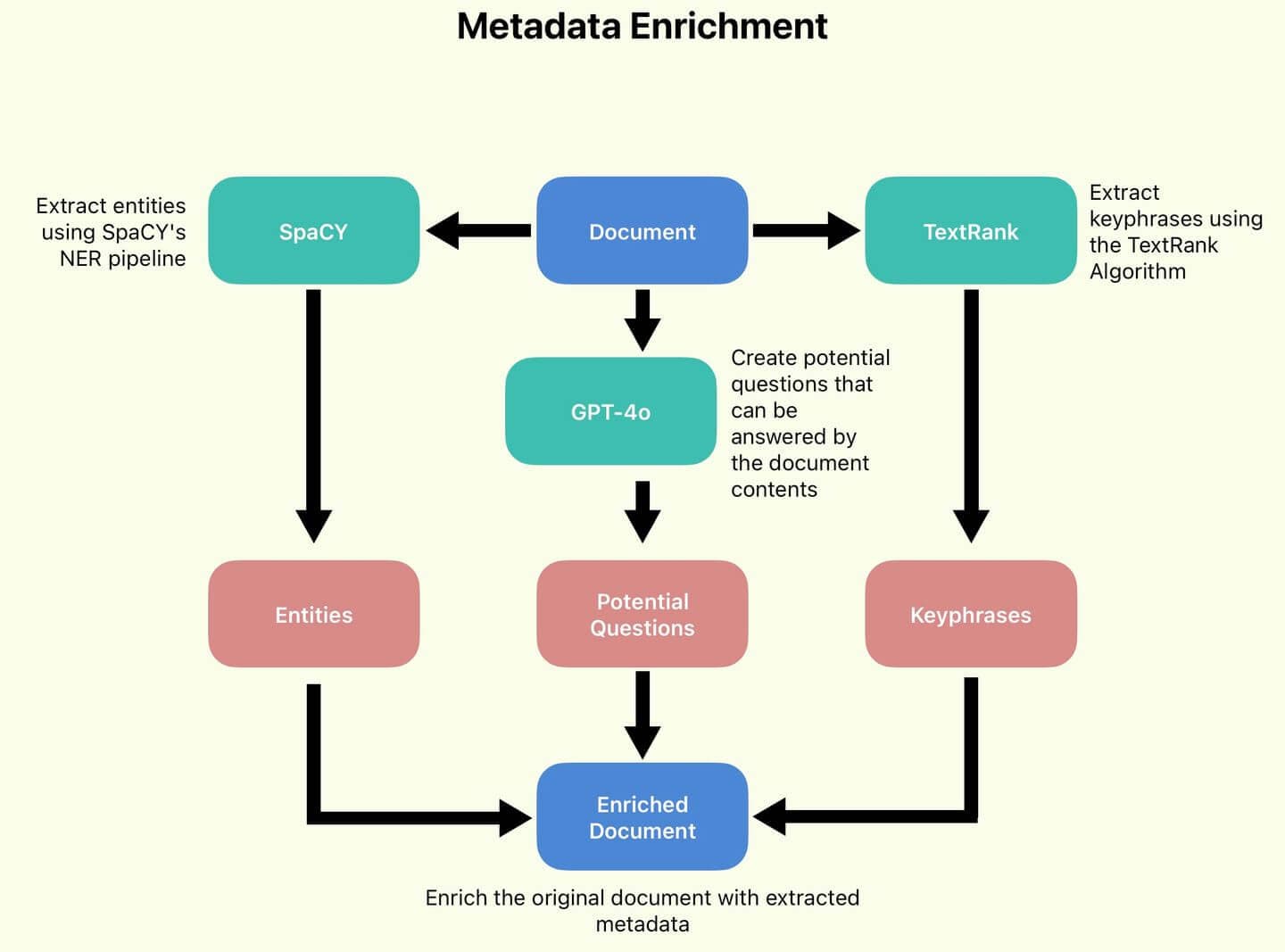
Metadata Enrichment Pipeline
The plan is to embed each of these fields, and then create a weighted sum of the embeddings, known as a Composite Embedding.
With luck, this Composite Embedding will allow the system to become more context aware, in addition to introducing another tunable hyperparameter from controlling the search behavior.
First, let's embed each field and update each document in place, using our locally defined embedding model imported at the beginning of the main.ipynb notebook.
Each embedding function returns the embedding's field, which is just the original input field with an _embedding postfix.
Let's now define the weightings of our composite embedding:
The weightings allow you to assign priorities to each component, based on your usecase and the quality of your data. Intuitively, the size of these weightings is dependent on the semantic value of each component. Since the chunk text itself is by far the richest, I assign a weighting of 70%. Since the entities are the smallest, being just a list of org or person names, I assign it a weighting of 5%. The precise setting for these values has to be determined empirically, on a use-case by use-case basis.
Finally, let's write a function to apply the weightings, and create our composite embedding. We'll delete all the component embeddings as well to save space.
With this, we've completed our document processing. We now have a list of document objects which look like this:
Indexing to Elastic
Let's bulk upload our documents to Elastic Search. For this purpose, I long-ago defined a set of Elastic Helper functions in elastic_helpers.py. It is a very lengthy piece of code so let's sticking to looking at the function calls.
es_bulk_indexer.bulk_upload_documents works with any list of dictionary objects, taking advantage of Elasticsearch's convenient dynamic mappings.
Head on over to Kibana and verify that all documents have been indexed. There should be 224 of them. Not bad for such a large document!
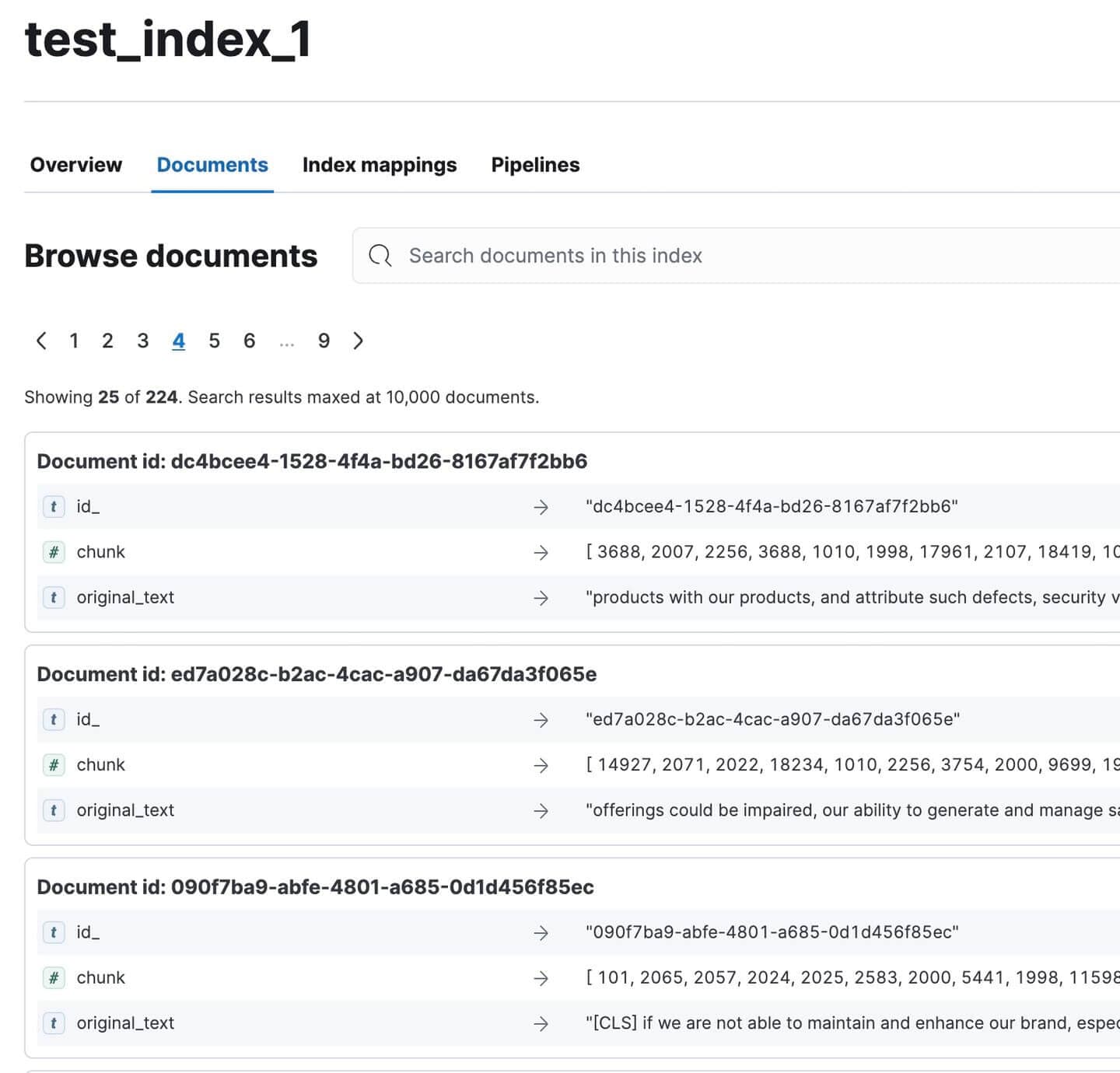
Indexed Annual Report Documents in Kibana
Cat break
Let's take a break, article's a little heavy, I know. Check out my cat:

look at how furious she is
Adorable. The hat went missing and I half suspect she stole and hid it somewhere :(
Congrats on making it this far :)
Join me in Part 2 for testing and evaluation of our RAG pipeline!
Appendix
Definitions
1. Sentence Chunking
- A preprocessing technique used in RAG systems to divide text into smaller, meaningful units.
- Process:
- Input: Large block of text (e.g., document, paragraph)
- Output: Smaller text segments (typically sentences or small groups of sentences)
- Purpose:
- Creates granular, context-specific text segments
- Allows for more precise indexing and retrieval
- Improves the relevance of retrieved information in RAG systems
- Characteristics:
- Segments are semantically meaningful
- Can be independently indexed and retrieved
- Often preserves some context to ensure standalone comprehensibility
- Benefits:
- Enhances retrieval precision
- Enables more focused augmentation in RAG pipelines
2. HyDE (Hypothetical Document Embedding)
- A technique that uses an LLM to generate a hypothetical document for query expansion in RAG systems.
- Process:
- Input query to an LLM
- LLM generates a hypothetical document answering the query
- Embed the generated document
- Use the embedding for vector search
- Key difference:
- Traditional RAG: Matches query to documents
- HyDE: Matches documents to documents
- Purpose:
- Improve retrieval performance, especially for complex or ambiguous queries
- Capture richer semantic context than a short query
- Benefits:
- Leverages LLM's knowledge to expand queries
- Can potentially improve relevance of retrieved documents
- Challenges:
- Requires additional LLM inference, increasing latency and cost
- Performance depends on quality of generated hypothetical document
3. Reverse Packing
- A technique used in RAG systems to reorder search results before passing them to the LLM.
- Process:
- Search engine (e.g., Elasticsearch) returns documents in descending order of relevance.
- The order is reversed, placing the most relevant document last.
- Purpose:
- Exploits the recency bias of LLMs, which tend to focus more on the latest information in their context.
- Ensures the most relevant information is "freshest" in the LLM's context window.
- Example: Original order: [Most Relevant, Second Most, Third Most, ...] Reversed order: [..., Third Most, Second Most, Most Relevant]
4. Query Classification
- A technique to optimize RAG system efficiency by determining whether a query requires RAG or can be answered directly by the LLM.
- Process:
- Develop a custom dataset specific to the LLM in use
- Train a specialized classification model
- Use the model to categorize incoming queries
- Purpose:
- Improve system efficiency by avoiding unnecessary RAG processing
- Direct queries to the most appropriate response mechanism
- Requirements:
- LLM-specific dataset and model
- Ongoing refinement to maintain accuracy
- Benefits:
- Reduces computational overhead for simple queries
- Potentially improves response time for non-RAG queries
5. Summarization
- A technique to condense retrieved documents in RAG systems.
- Process:
- Retrieve relevant documents
- Generate concise summaries of each document
- Use summaries instead of full documents in the RAG pipeline
- Purpose:
- Improve RAG performance by focusing on essential information
- Reduce noise and interference from less relevant content
- Benefits:
- Potentially improves relevance of LLM responses
- Allows for inclusion of more documents within context limits
- Challenges:
- Risk of losing important details in summarization
- Additional computational overhead for summary generation
6. Metadata Inclusion
- A technique to enrich documents with additional contextual information.
- Types of metadata:
- Keyphrases
- Titles
- Dates
- Authorship details
- Blurbs
- Purpose:
- Increase contextual information available to the RAG system
- Provide LLMs with clearer understanding of document content and relevance
- Benefits:
- Potentially improves retrieval accuracy
- Enhances LLM's ability to assess document usefulness
- Implementation:
- Can be done during document preprocessing
- May require additional data extraction or generation steps
7. Composite Multi-Field Embeddings
- An advanced embedding technique for RAG systems that creates separate embeddings for different document components.
- Process:
- Identify relevant fields (e.g., title, keyphrases, blurb, main content)
- Generate separate embeddings for each field
- Combine or store these embeddings for use in retrieval
- Difference from standard approach:
- Traditional: Single embedding for entire document
- Composite: Multiple embeddings for different document aspects
- Purpose:
- Create more nuanced and context-aware document representations
- Capture information from a wider variety of sources within a document
- Benefits:
- Potentially improves performance on ambiguous or multi-faceted queries
- Allows for more flexible weighting of different document aspects in retrieval
- Challenges:
- Increased complexity in embedding storage and retrieval processes
- May require more sophisticated matching algorithms
8. Query Enrichment
- A technique to expand the original query with related terms to improve search coverage.
- Process:
- Analyze the original query
- Generate synonyms and semantically related phrases
- Augment the query with these additional terms
- Purpose:
- Increase the range of potential matches in the document corpus
- Improve retrieval performance for queries with specific or technical language
- Benefits:
- Potentially retrieves relevant documents that don't exactly match the original query terms
- Can help overcome vocabulary mismatch between queries and documents
- Challenges:
- Risk of query drift if not carefully implemented
- May increase computational overhead in the retrieval process
Related Content
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
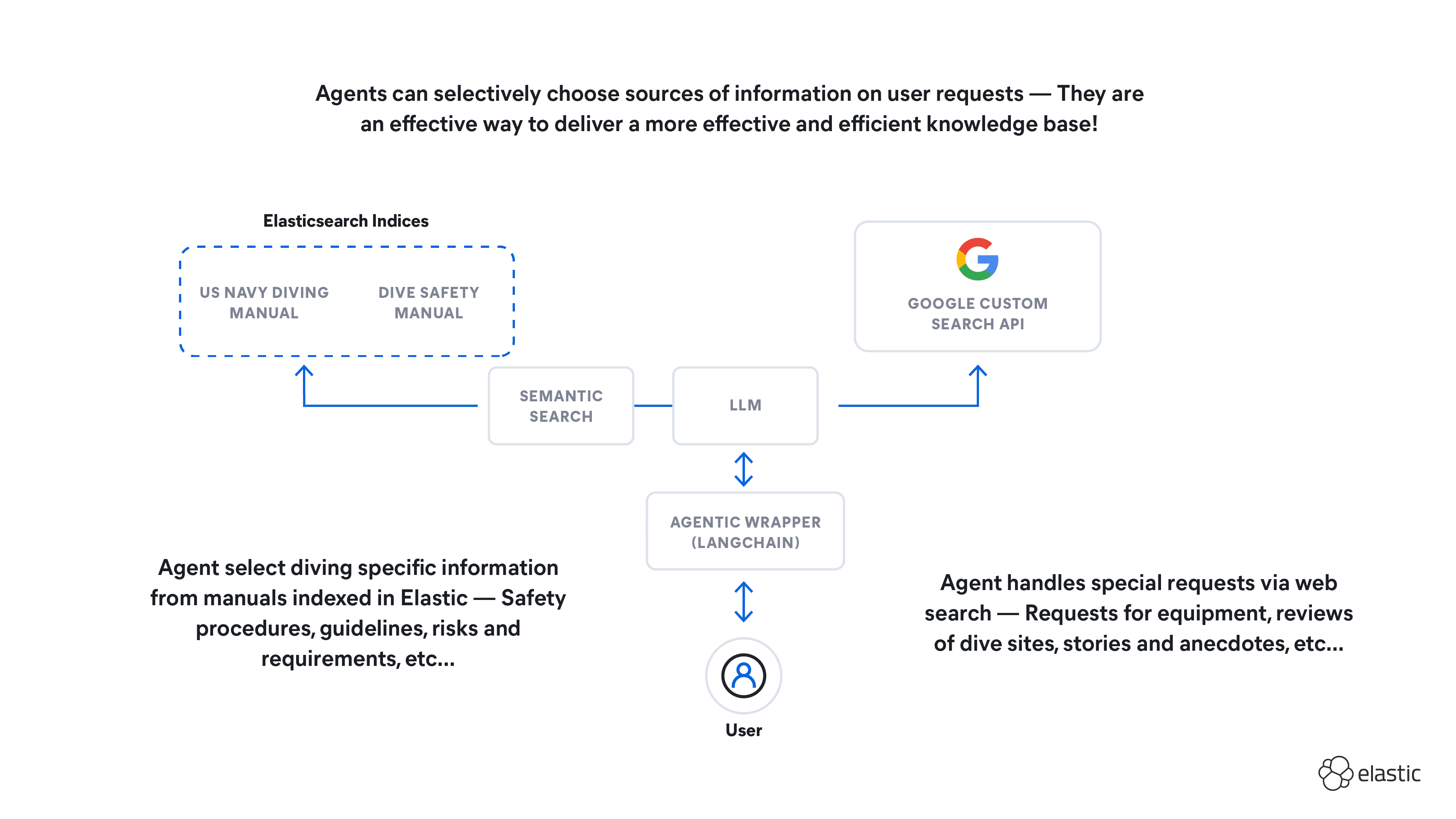
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.

December 29, 2025
Creating reliable agents with structured outputs in Elasticsearch
Explore what structured outputs are and how to leverage them in Elasticsearch to ground agents in the most relevant context for data contracts.
December 23, 2025
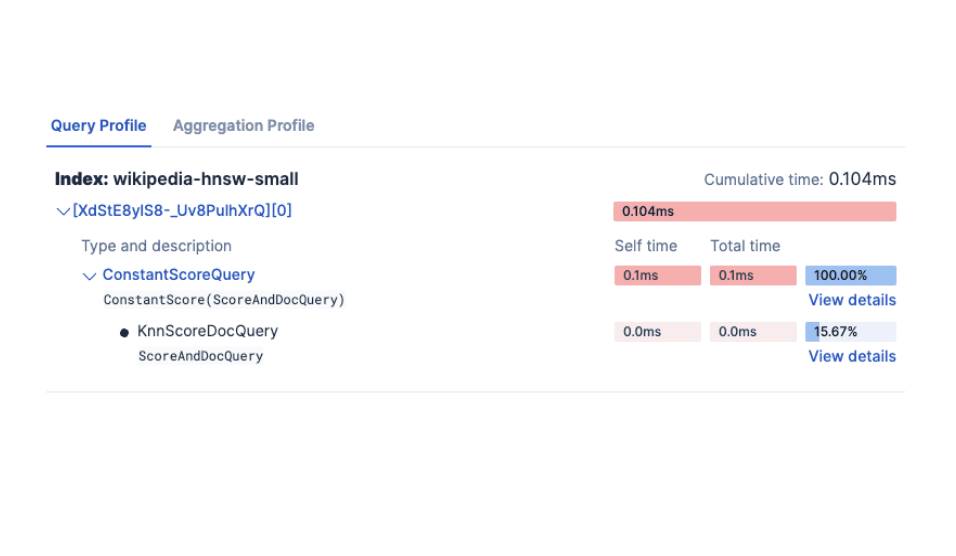
Comparing dense vector search performance with the Profile API in Elasticsearch
Learn how to use the Profile API in Elasticsearch to compare dense vector configurations and tune kNN performance with visual data from Kibana.
December 15, 2025
Getting started with Elastic Agent Builder and Strands Agents SDK
Learn how to create an agent with Elastic Agent Builder and then explore how to use the agent via the A2A protocol orchestrated with the Strands Agents SDK.