Elasticsearch is packed with new features to help you build the best search solutions for your use case. Learn how to put them into action in our hands-on webinar on building a modern Search AI experience. You can also start a free cloud trial or try Elastic on your local machine now.
Elasticsearch’s semantic query is incredibly powerful, allowing users to perform semantic search over data configured in semantic_text fields. Much of this power lies in simplicity: just set up a semantic_text field with the inference endpoint you want to use, and then ingest content as if indexing content into a regular text field. The inference happens automatically and transparently, making it simple to set up and use a search index with semantic functionality.
This ease of use does come with some tradeoffs: we simplified semantic search with semantic_text by making judgments on default behavior that fit the majority of use cases. Unfortunately, this means that some customizations available for traditional vector search queries aren’t present in the semantic query. We didn’t want to add all of these options directly to the semantic query, as that would undermine the simplicity that we strive for. Instead, we expanded the queries that support the semantic_text field, leaving it up to you to choose the best query that meets your needs.
Let’s walk through these changes, starting with creating a simple index with a semantic_text field:
We made match happen in semantic search!

First and most importantly, the match query will now work with semantic_text fields!
This means that you can change your old semantic query:
Into a simple match query:
We can see the benefits of semantic search here because we’re searching for “song lyrics about love”, none of which appears in the indexed document. This is because of ELSER’s text expansion.
But wait, it gets better!
If you have multiple indices, and the same field name is semantic_text in one field and perhaps text in the other field, you can still run match queries against these fields. Let’s create another index, with the same field names, but different types (text instead of semantic_text). Here’s a simple example to illustrate:
Here, searching for “crazy” brings up both the lexical match that has “crazy” in the title, and the semantic lyric “lose my mind.”
There are some caveats to keep in mind when using the match functionality with semantic_text:
- The underlying
semantic_textfield has a limitation where you can’t use multiple inference IDs on the same field. This limitation extends tomatch—meaning that if you have two semantic_text fields with the same name, they need to have the same inference ID or you’ll get an error. You can work around this by creating different names and querying them in a boolean query or a compound retriever. - Depending on what model you use, the scores between lexical (text) matches and semantic matches will likely be very different. In order to get the best ranking of results, we recommend using second stage rerankers such as semantic reranking or RRF.
Semantic search using the match query is also available in ES|QL! Here’s the same example as above, but using ES|QL:
Expert-level semantic search with knn and sparse_vector
Match is great, but sometimes you want to specify more vector search options than the semantic query supports. Remember, the tradeoff of making the semantic query as simple as it is involved making some decisions on default behavior.
This means that if you want to take advantage of some of the more advanced vector search features, perhaps num_candidates or filter from the knn query or token pruning in the sparse_vector query, you won’t be able to do so using the semantic query.
In the past, we provided some workarounds to this, but they were convoluted and required knowing the inner workings and architecture of the semantic_text field and constructing a corresponding nested query. If you’re doing that workaround now, it will still work—however, we now support query DSL using knn or sparse_vector queries on semantic_text fields.
All about that dense (vector), no trouble

Here’s an example script that populates a text_embedding model and queries a semantic_text field using the knn query:
The knn query can be modified with extra options to enable more advanced queries against the semantic_text field. Here, we perform the same query but add a pre-filter against the semantic_text field:
Keepin’ it sparse (vector), keepin’ it real

Similarly, sparse embedding models can be queried more specifically using semantic_text fields as well. Here’s an example script that adds a few more documents and uses the sparse_vector query:
The sparse_vector query can be modified with extra options, to enable more advanced queries against the semantic_text field. Here, we perform the same query but add token pruning against a semantic_text field:
This example significantly decreases the token frequency ratio required to pruning, which helps us show differences with such a small dataset, though they’re probably more aggressive than you’d want to see in production (remember, token pruning is about pruning irrelevant tokens to improve performance, not drastically change recall or relevance). You can see in this example that the Avril Lavigne song is no longer returned, and the scores have changed due to the pruned tokens. (Note that this is an illustrative example, and we still recommend a rescore adding pruned tokens back into scoring for most use cases).
You’ll note that with all of these queries if you’re only querying a semantic_text field, you no longer need to specify the inference ID in knn’s query_vector_builder or in the sparse_vector query. This is because it will be inferred from the semantic_text field. You can specify it if you want to override with a different (compatible!) inference ID for some reason or if you’re searching combined indices that have both semantic_text and sparse_vector or dense_vector fields though.
Try it out yourself
We’re keeping the original semantic query simple, but expanding our semantic search capabilities to power more use cases and seamlessly integrate semantic search with existing workflows. These power-ups are native to Elasticsearch and are already available in Serverless. They’ll be available in stack-hosted Elasticsearch starting with version 8.18.
Try it out today!
Related Content
January 30, 2026
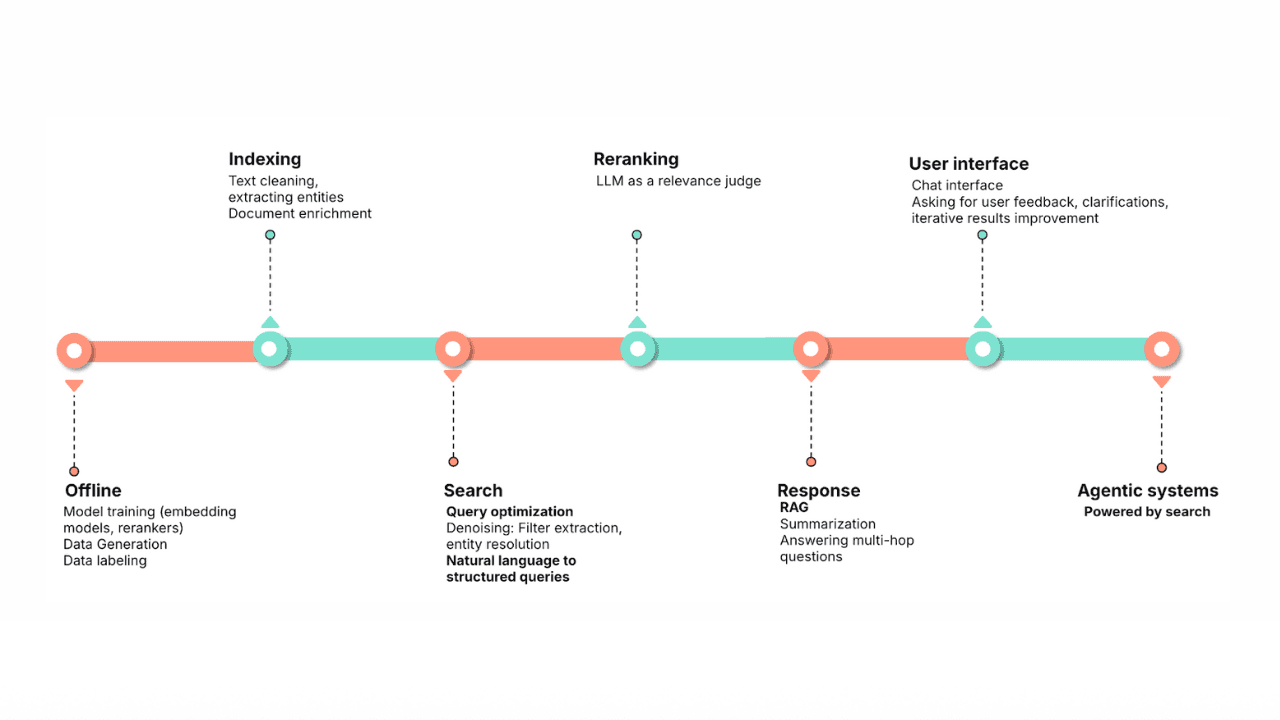
Query rewriting strategies for LLMs and search engines to improve results
Exploring query rewriting strategies and explaining how to use the LLM's output to boost the original query's results and maximize search relevance and recall.

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.