From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into sample notebooks on GitHub to try something new. You can also start your free trial or run Elasticsearch locally today.
In this blog, you'll learn about Playground and how to use it to experiment with Retrieval-Augmented Generation (RAG) applications using Elasticsearch.
Update: Try the new Playground app in the Elastic demo gallery.
What is Playground?
Elastic's playground experience is a low-code interface for developers to explore grounding LLMs of their choice with their own private data in minutes.
While prototyping conversational search, the ability to rapidly iterate on and experiment with key components of a RAG workflow (for example: hybrid search, or adding reranking) are important— to get accurate and hallucination-free responses from LLMs.
Elasticsearch vector database and the Search AI platform provides developers with a wide range of capabilities such as comprehensive hybrid search, and to use innovation from a growing list of LLM providers. Our approach in our playground experience allows you to use the power of those features, without added complexity.
A/B test LLMs and choose different inference providers
Playground’s intuitive interface allows you to A/B test different LLMs from model providers (like OpenAI and Anthropic) and refine your retrieval mechanism, to ground answers with your own data indexed into one or more Elasticsearch indices. The playground experience can leverage transformer models directly in Elasticsearch, but is also amplified with the Elasticsearch Open Inference API which integrates with a growing list of inference providers including Cohere and Azure AI Studio.
The best context window with retrievers and hybrid search
As Elasticsearch developers already know, the best context window is built with hybrid search. Your strategy for architecting towards this outcome requires access to many shapes of vectorized and plain text data, that can be chunked and spread across multiple indices.
We’re helping you simplify query construction with newly introduced query retrievers to Search All the Things! With three key retrievers (available now in 8.14 and Elastic Cloud Serverless) hybrid search with scores normalized with RRF is one unified query away. Using retrievers, the playground understands the shape of the selected data and will automatically generate a unified query on your behalf. Store vectorized data and explore a kNN retriever, or add metadata and context to generate a hybrid search query by selecting your data. Coming soon, semantic reranking can easily be incorporated into your generated query for even higher-quality recall.
Once you’ve tuned and configured your semantic search to production standards, you’re ready to export the code and either finalize the experience in your application with your Python Elasticsearch language client or LangChain Python integration.
Playground is accessible today on Elastic Cloud Serverless and available today in 8.14 on Elastic Cloud.
Using the Playground
Playground is accessible from within Kibana (the Elasticsearch UI) by navigating to “Playground” from within the side navigation.
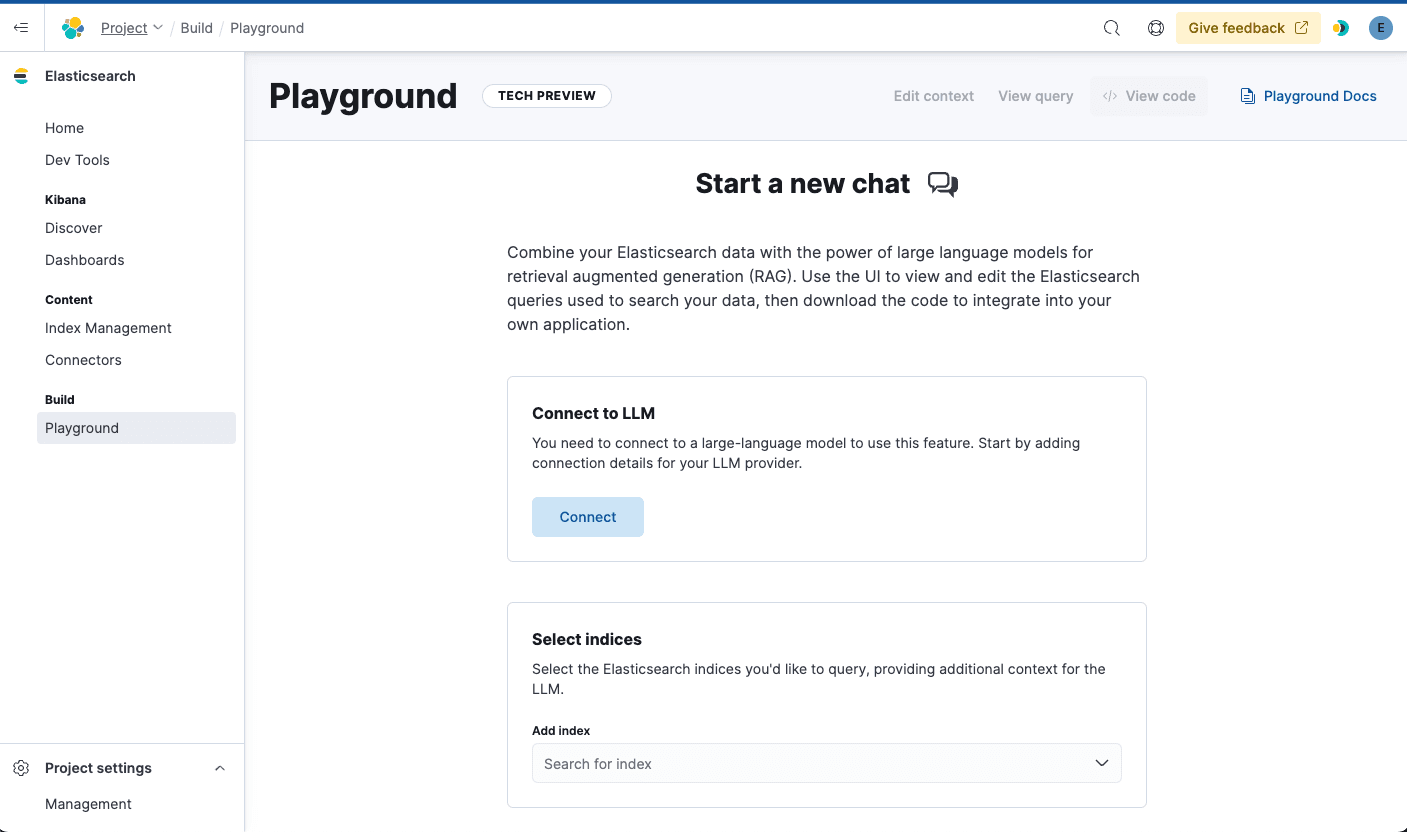
Connect to your LLM
Playground supports chat completion models such as GPT-4o from OpenAI, Azure OpenAI, or Anthropic through Amazon Bedrock. To start, you need to connect to either one of these model providers to bring your LLM of choice.
Chat with your data
Any data can be used, even BM25-based indices. Your data fields can optionally be transformed using text embedding models (like our zero-shot semantic search model ELSER), but this is not a requirement.Getting Started is extremely simple - just select the indices you want to use to ground your answers and start asking questions.In this example, we are going to use a PDF and start with using BM25, with each document representing a page of the PDF.
Indexing a PDF document with BM25 with Python
First, we install the dependencies. We use the pypdf library to read PDFs and request to retrieve them.
Then we read the file, creating an array of pages containing the text.
And we then import this into elasticsearch, under the my_pdf_index_bm25 index.
Chatting with your data with Playground
Once we have connected our LLM with a connector and chosen the index, we can start asking questions about the PDF. The LLM will now easily provide answers to your data.
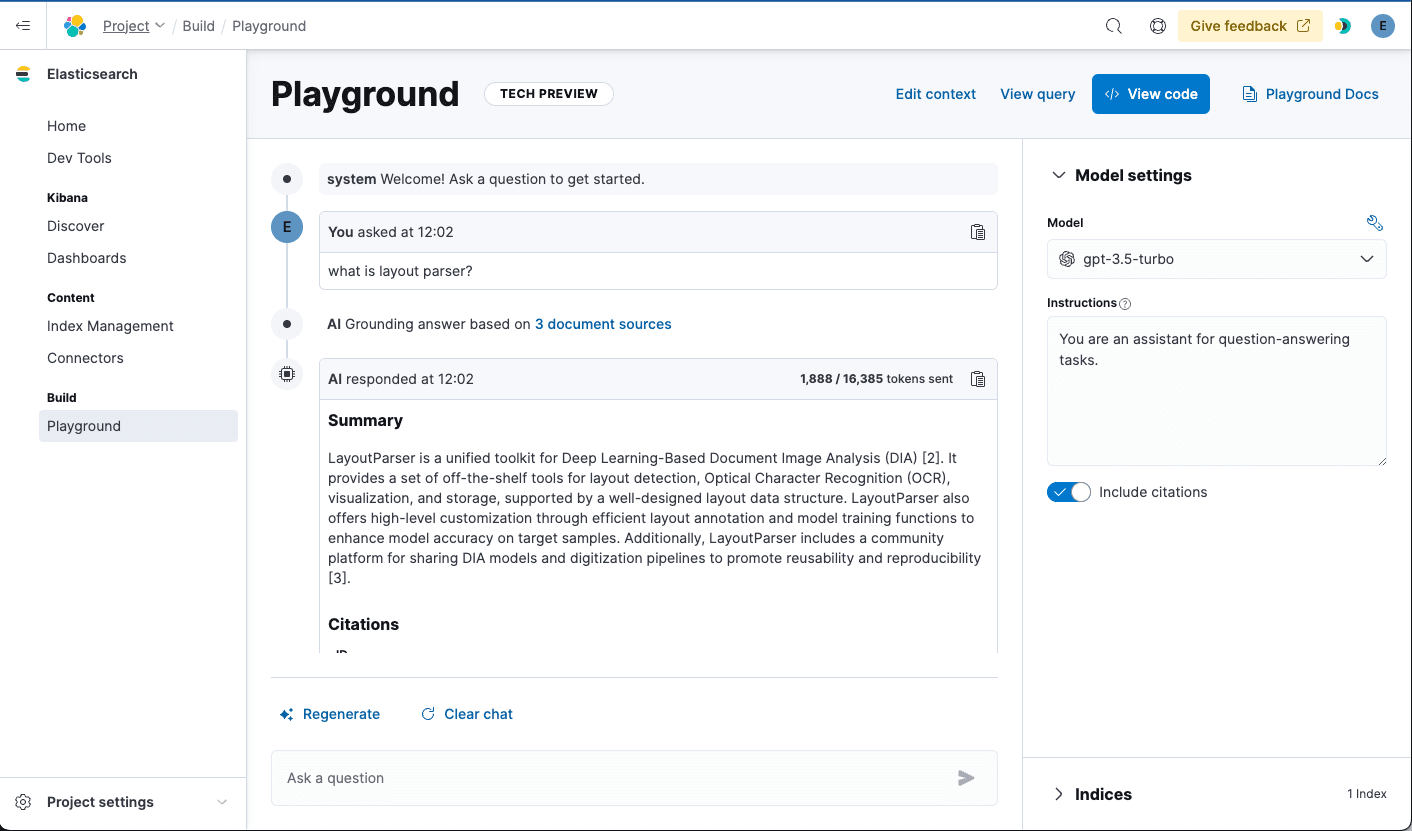
What happens behind the scenes?
When we choose an index, we automatically determine the best retrieval method. In this case, BM25 keyword search is only available, so we generate a multi-match type query to perform retrieval.
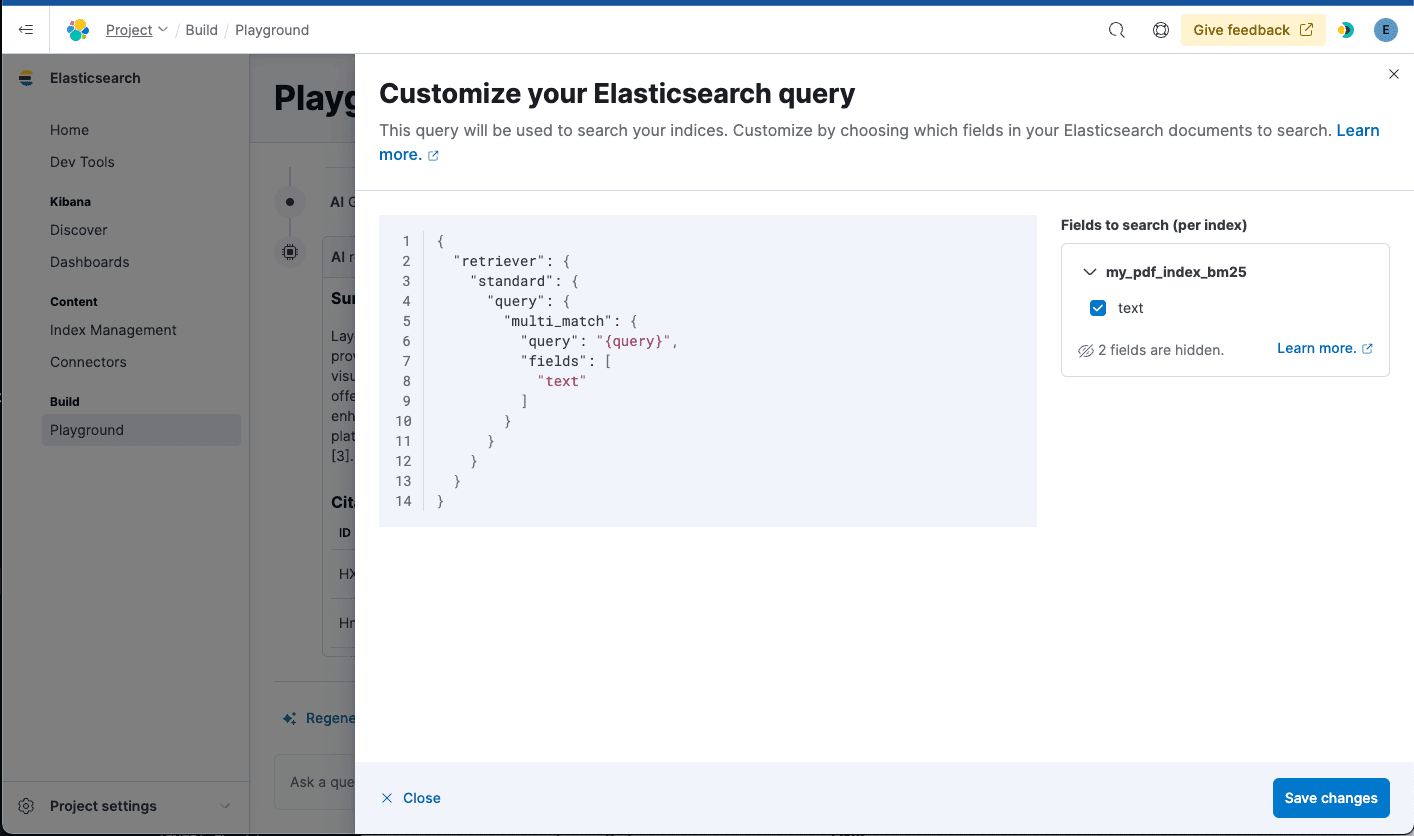
As we only have one field, we defaulted to searching for this. If you have more than one field, you can choose the fields you want to search to improve the retrieval of relevant documents.
Asking a question
When you ask a question, Playground will perform a retrieval using the query to find relevant documents matching your question. It will then use this as context and provide it with the prompt, grounding the answer that’s returned from your chosen LLM model.
We use a particular field from the document for the context. In this example, Playground has chosen the field named “text,” but this can be changed within the “edit context” action.
By default, we retrieve up to 3 documents for the context, but you can adjust the number from within the edit context flyout as well.
Asking a follow up question
Typically, the follow-up question is tied to a previous conversation. With that in mind, we ask the LLM to rewrite the follow-up question using the conversation into a standalone question, which is then used for retrieval. This allows us to retrieve better documents to use as context to help answer the question.
Context
When documents are found based on your question, we provide these documents to the LLM as context to ground the LLM’s knowledge when answering. We automatically choose a single index field we believe is best, but you can change this field by going to the edit context flyout.
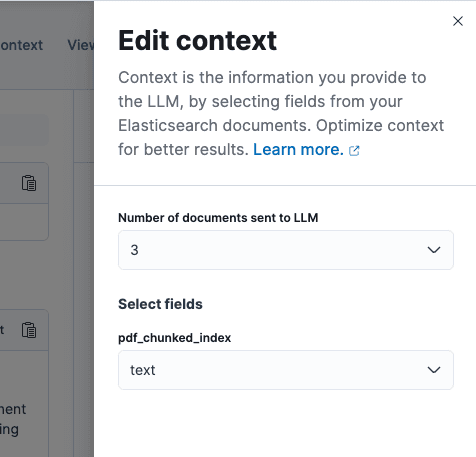
Improving retrieval with Semantic Search and Chunking
Since our query is in the form of a question, it is important for retrieval to be able to match based on semantic meaning. With BM25 we can only match documents that lexically match our question, so we’ll need to add semantic search too.
Sparse Vector Semantic search with ELSER
One simple way to start with semantic search is to use Elastic’s ELSER sparse embedding model with our data. Like many models of this size and architecture, ELSER has a typical 512-token limit and requires a design choice of an appropriate chunking strategy to accommodate it. In upcoming versions of Elasticsearch, we’ll chunk by default as part of the vectorization process, but in this version, we’ll follow a strategy to chunk by paragraphs as a starting point. The shape of your data may benefit from other chunking strategies, and we encourage experimentation to improve retrieval.
Chunking and ingesting the PDF with pyPDF and LangChain
To simplify the example, we will use LangChain tooling to load and split the pages into passages. LangChain is a popular tool for RAG development that can be integrated and used with the Elasticsearch vector database and semantic reranking capabilities with our updated integration.
Creating an ELSER inference endpoint
The following REST API calls can be executed to download, deploy, and check the model's running status. You can execute these using Dev Tools within Kibana.
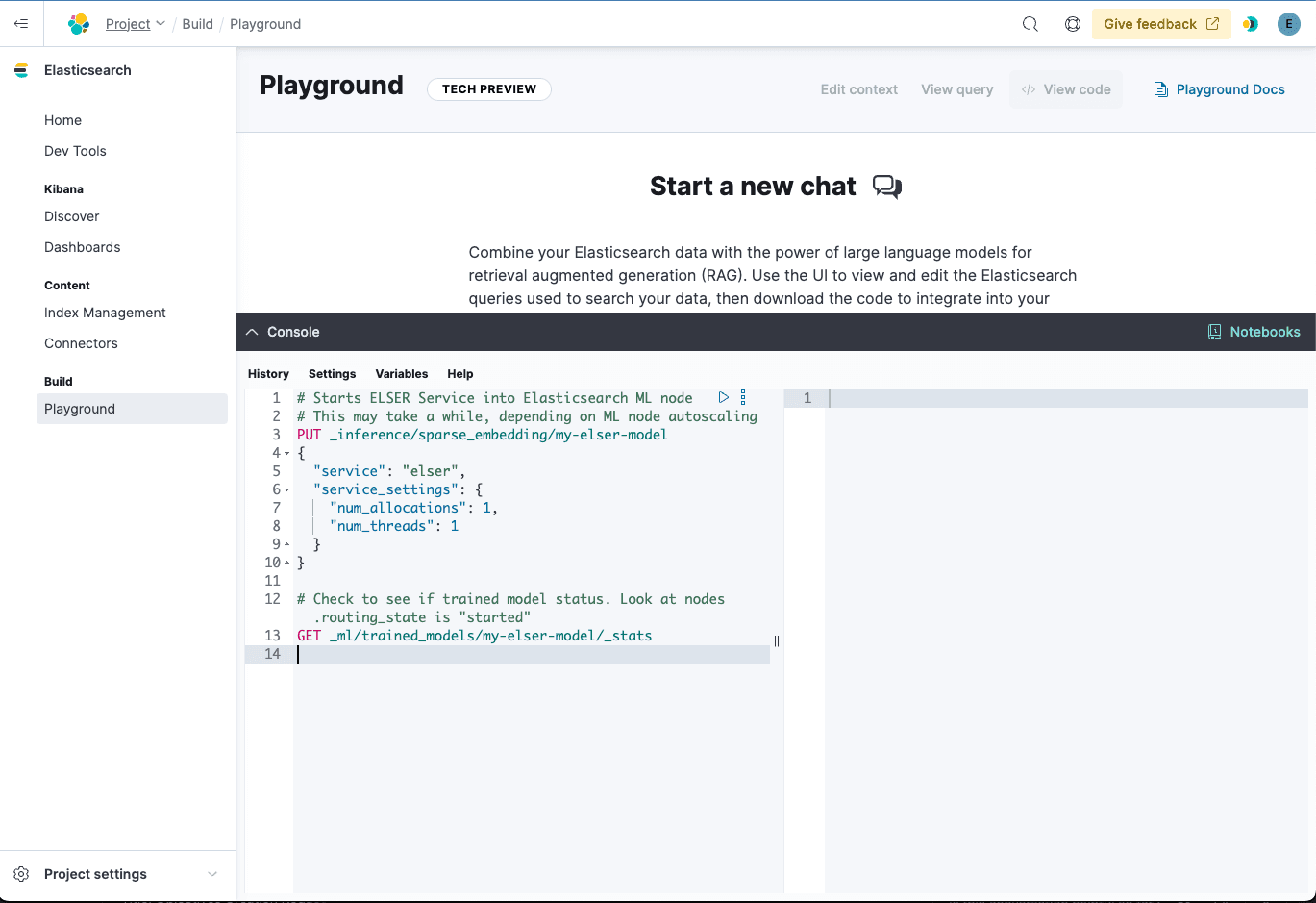
Ingesting into Elasticsearch
Next we will set up an index and attach a pipeline that will handle the inference for us.
Splitting pages into passages and ingesting into Elasticsearch
Now that the ELSER model has been deployed, we can start splitting the PDF pages into passages and ingesting them into Elasticsearch.
That’s it! We should have passages ingested into Elasticsearch that have been embedded with ELSER.
See it in action on Playground
Now when selecting the index, we generate an ELSER-based query using the deployment_id for embedding the query string.
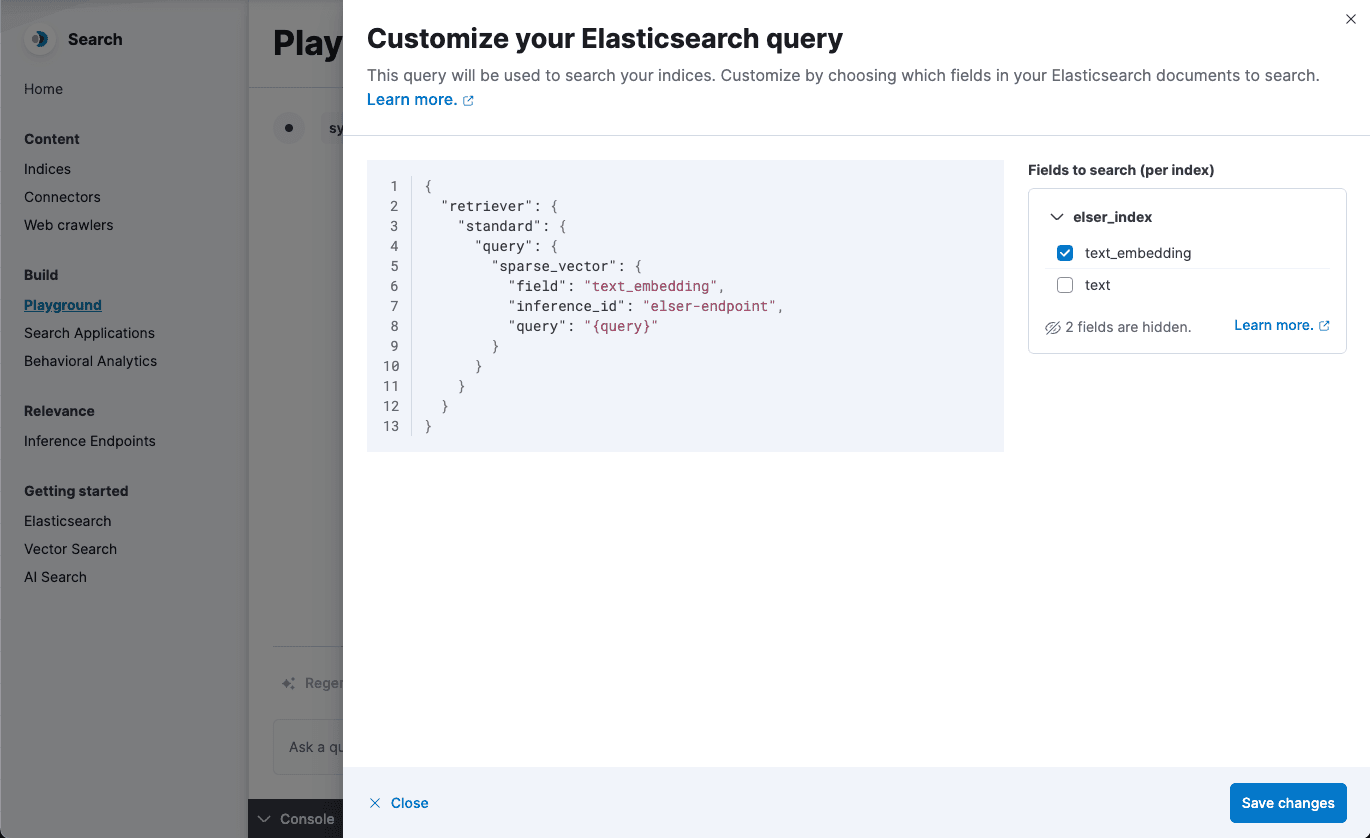
When asking a question, we now have a semantic search query that is used to retrieve documents that match the semantic meaning of the question.
Hybrid Search made simple
Enabling the text field can also enable hybrid search. When we retrieve documents, we now search for both keyword matches and semantic meaning and rank the two result sets with the RRF algorithm.
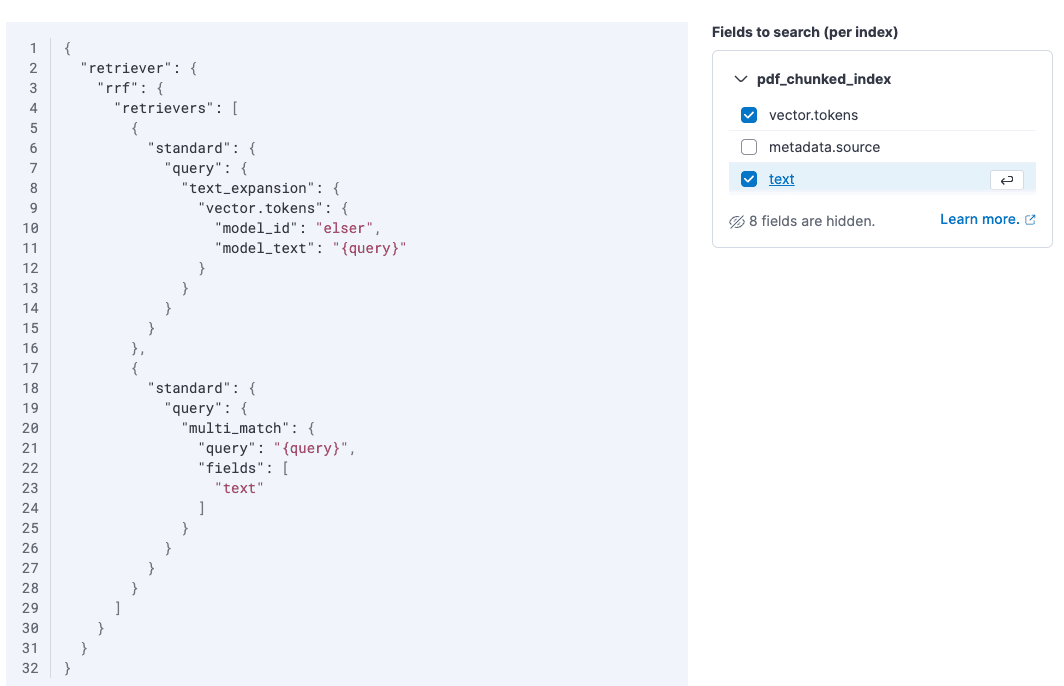
Improve the LLM’s answers
With Playground, you can adjust your prompt, tweak your retrieval, and create multiple indices (chunking strategy and embedding models) to improve and compare your responses.
In the future, we will provide hints on how to get the most out of your index, suggesting methods to optimize your retrieval strategy.
System prompt
By default, we provide a simple system prompt which you can change within model settings. This is used in conjunction with a wider system prompt. You can change the simple system prompt by just editing it.
Optimizing context
Good responses rely on great context. Using methods like chunking your content and optimizing your chunking strategy for your data is important. Along with chunking your data, you can improve retrieval by trying out different text embedding models to see what gives you the best results. In the above example, we have used Elastic’s own ELSER model, but the inference service supports a wide number of embedding models that may suit your needs better.
Other benefits of optimizing your context include better cost efficiency and speed: cost is calculated based on tokens (input and output). The more relevant documents we can provide, aided by chunking and Elasticsearch's powerful retrieval capabilities, the lower the cost and faster latency will be for your users.
If you notice, the input tokens we used in the BM25 example are larger than those in the ELSER example. This is because we effectively chunked our documents and only provided the LLM with the most relevant passages on the page.
Final Step! Integrate RAG into your application
Once you’re happy with the responses, you can integrate this experience into your application. View code offers example application code for how to do this within your own API.
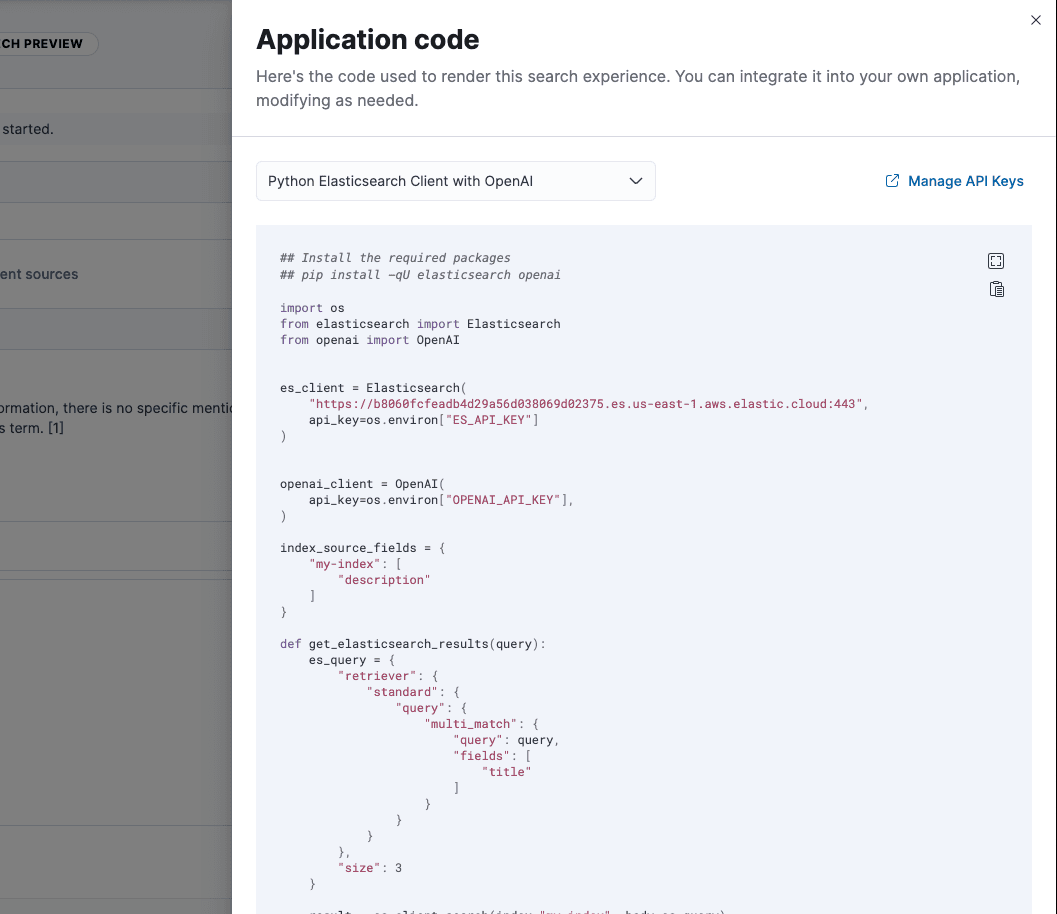
For now, we provide examples with OpenAI or LangChain, but the Elasticsearch query, the system prompt, and the general interaction between the model and Elasticsearch are relatively simple to adapt for your own use.
Conclusion
Conversational search experiences can be built with many approaches in mind, and the choices can be paralyzing, especially with the pace of innovation in new reranking and retrieval techniques, both of which apply to RAG applications.
With our playground, those choices are simplified and intuitive, even with the vast array of capabilities available to the developer. Our approach is unique in enabling hybrid search as a predominant pillar of the construction immediately, with an intuitive understanding of the shape of the selected and chunked data and amplified access across multiple external providers of LLMs.
Build, test, fun with playground
Try the Playground demo or head over to Playground docs to get started today! Explore Search Labs on GitHub for new cookbooks and integrations for providers such as Cohere, Anthropic, Azure OpenAI, and more.
Frequently Asked Questions
What is Elastic's Playground?
Playground is a low code interface for developers to explore grounding LLMs of their choice with their own private data, in minutes.
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
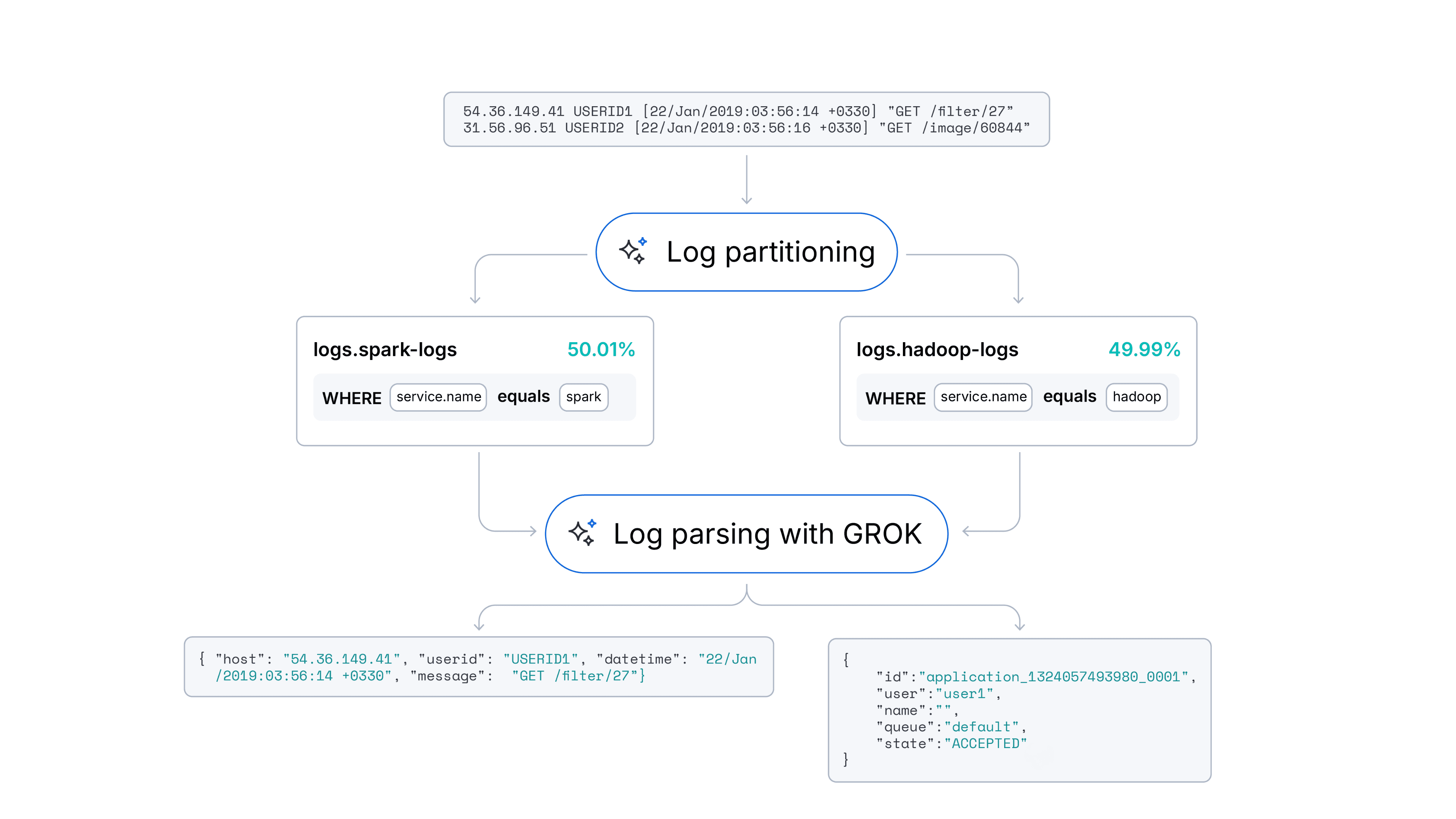
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
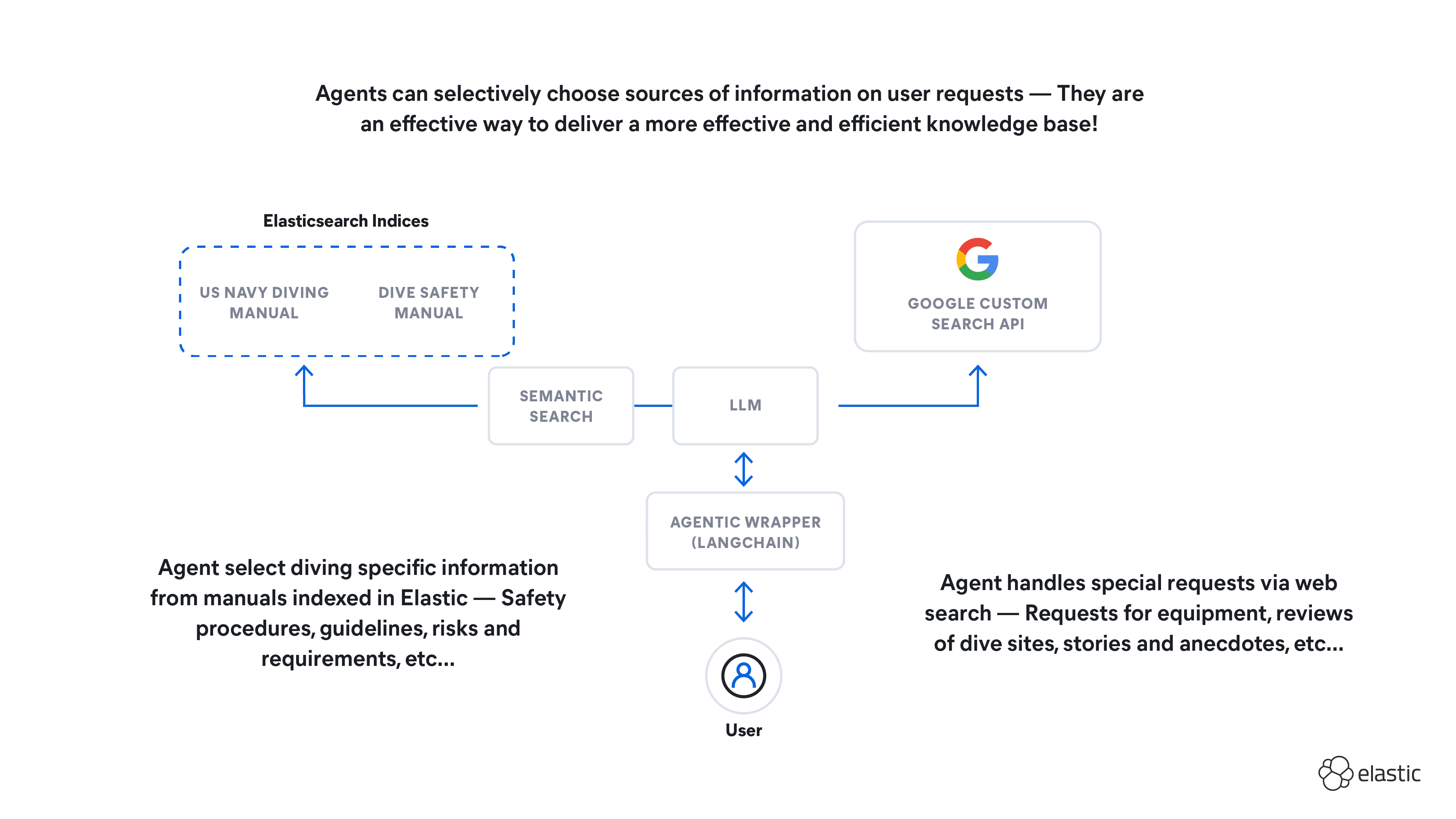
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.