Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running! You can start a free cloud trial or try Elastic on your local machine now.
Our Better Binary Quantization (BBQ) indices are now even better(er). Recall improvements across the board (in extreme cases up to 20%) and unlocking the future of quantizing vectors to any bit size. As of Elasticsearch 8.18, BBQ indices are now backed by our state of the art optimized scalar quantization algorithm.
Scalar quantization history
Introduced in Elasticsearch 8.12, scalar quantization was initially a simple min/max quantization scheme. Per lucene segment, we would find the global quantile values for a given confidence interval. These quantiles are then used as the minimum and maximum to quantize all the vectors. While this naive quantization is powerful, it only really works for whole byte quantization.
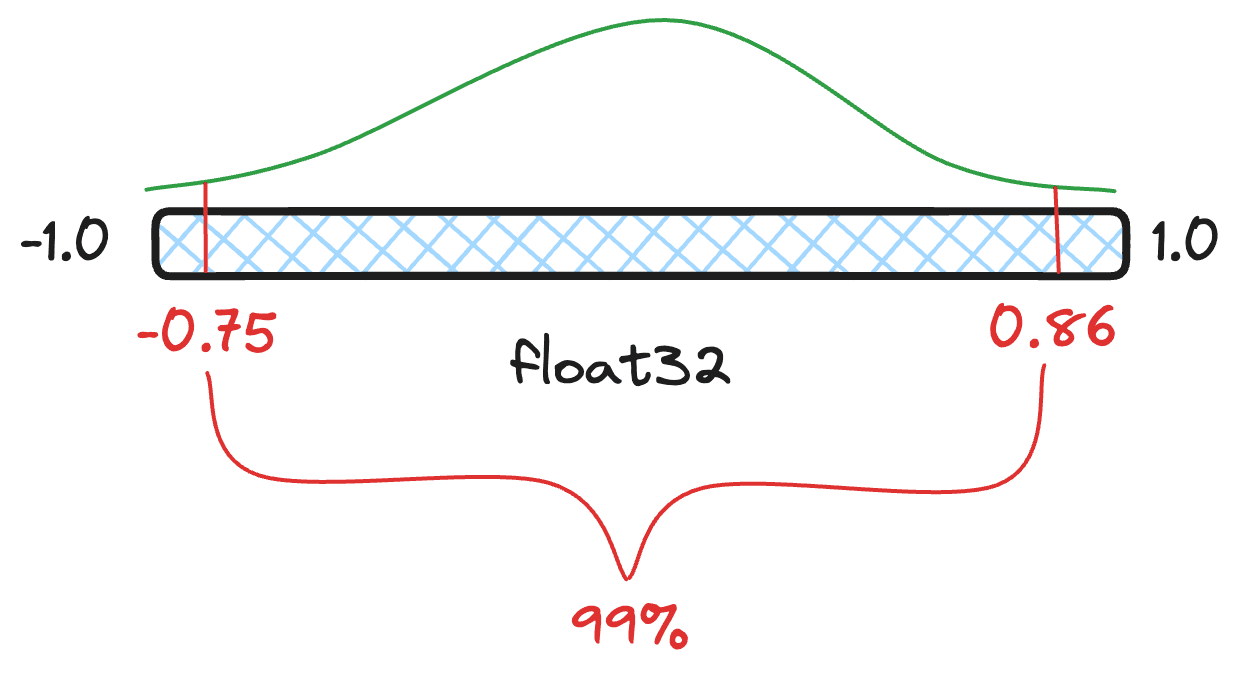
Static confidence intervals mean static quantiles. This is calculated once for all vectors in a given segment and works well for higher bit values.
In Elasticsearch 8.15, we added half-byte, or int4, quantization. To achieve this with high recall, we added an optimization step, allowing for the best quantiles to be calculated dynamically. Meaning, no more static confidence intervals. Lucene will calculate the best global upper and lower quantiles for each segment. Achieving 8x reduction in memory utilization over float32 vectors.
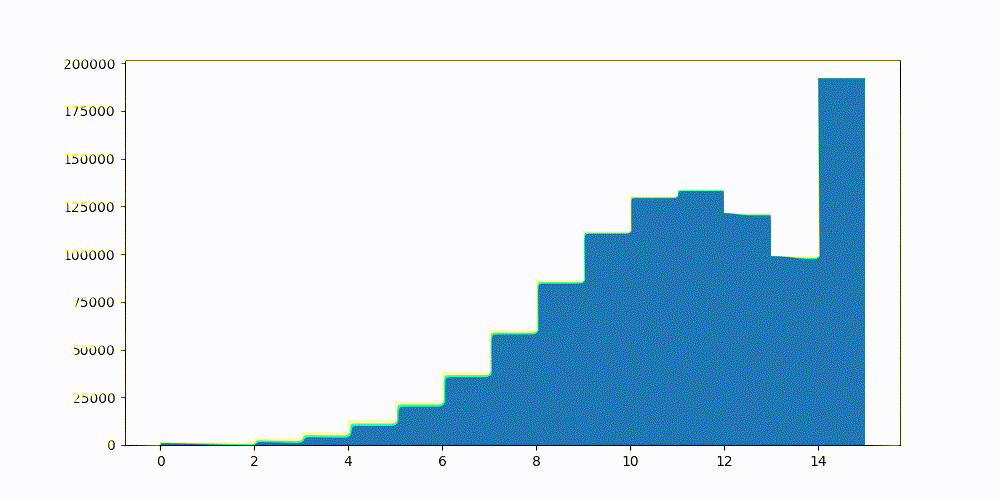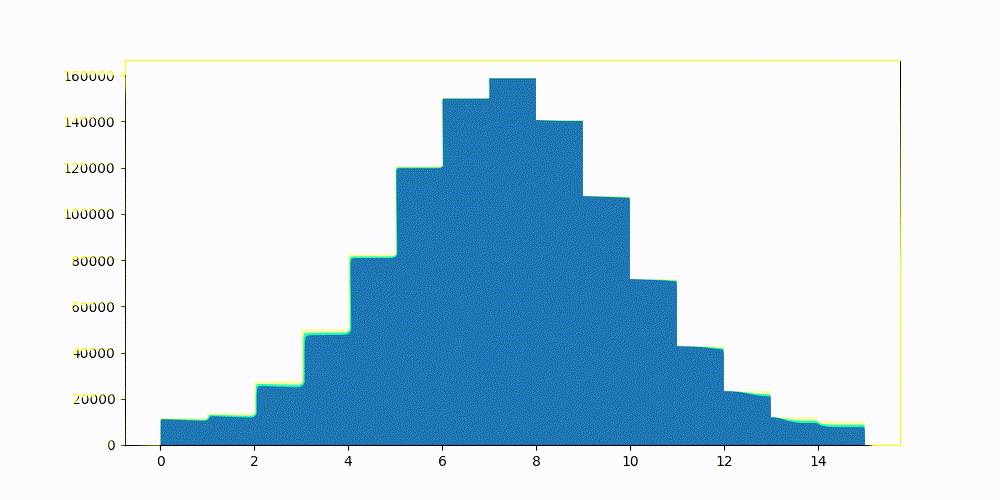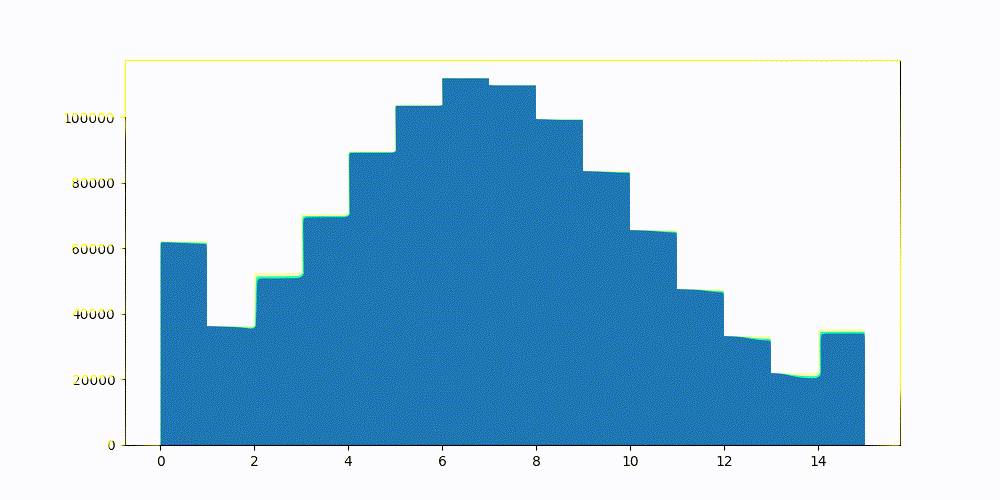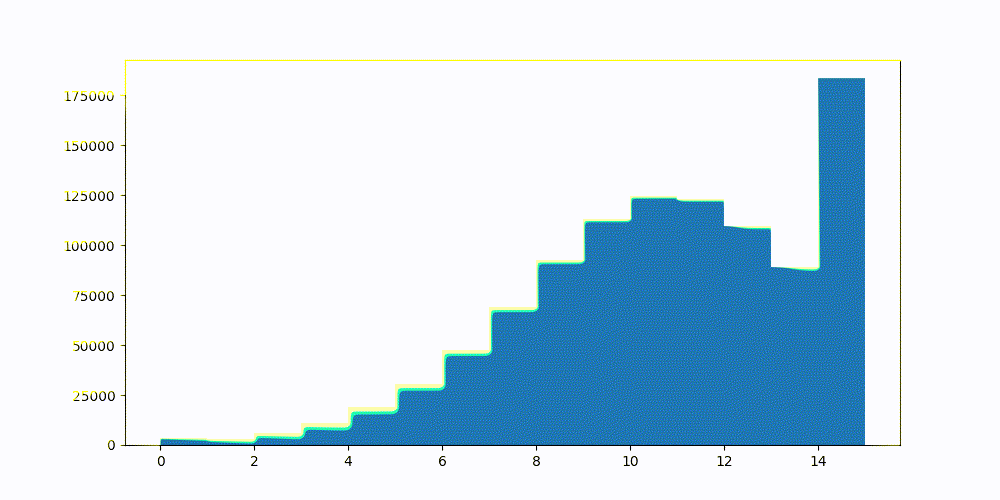
Dynamically searching for the best quantiles to reduce the vector similarity error. This was done once, globally, over a sample set of the vectors and applied to all.
Finally, now in 8.18, we have added locally optimized scalar quantization. It optimizes quantiles per individual vector. Allowing for exceptional recall at any bit size, even single bit quantization.
What is Optimized Scalar Quantization?
For an in-depth explanation of the math and intuition behind optimized scalar quantization, check out our blog post on Optimized Scalar Quantization. There are three main takeaways from this work:
- Each vector, is centered on the Apache Lucene segment's centroid. This allows us to make better use of the possible quantized vectors to represent the dataset as a whole.
- Every vector is individually quantized with a unique set of optimized quantiles.
- Asymmetric quantization is used allowing for higher recall with the same memory footprint.
In short, when quantizing each vector:
- We center the vector on the centroid
- Compute a limited number of iterations to find the optimal quantiles. Stopping early if the quantiles are unchanged or the error (loss) increases
- Pack the resulting quantized vectors
- Store the packed vector, its quantiles, the sum of its components, and an extra error correction term
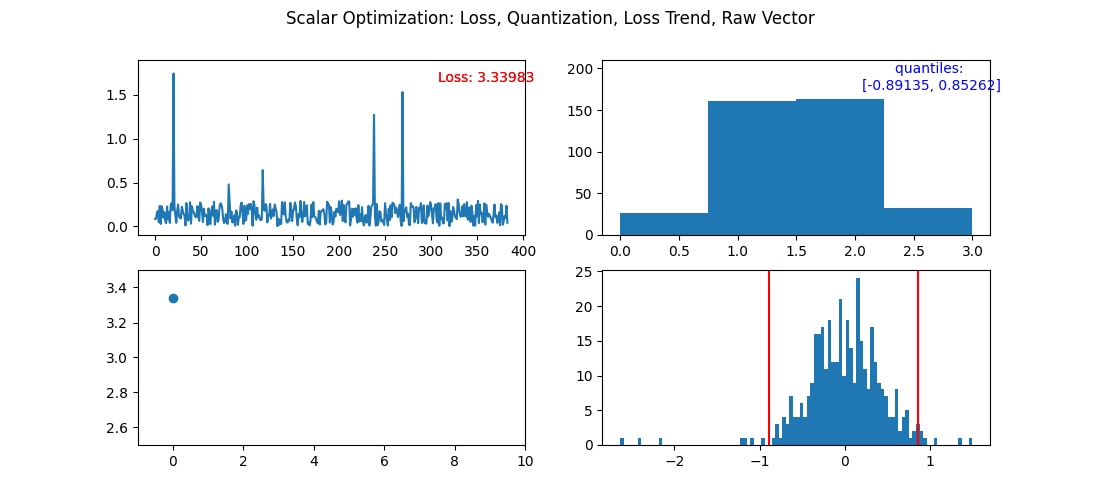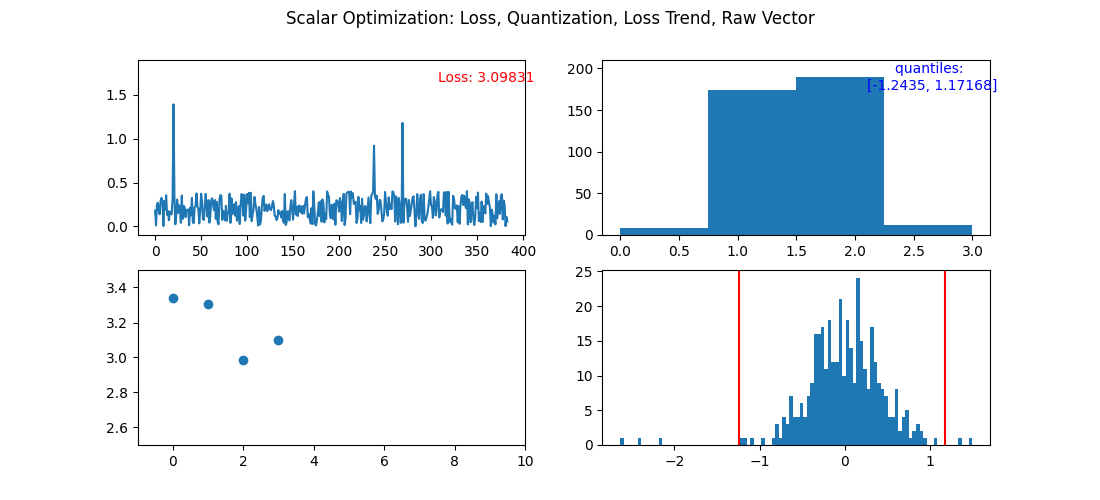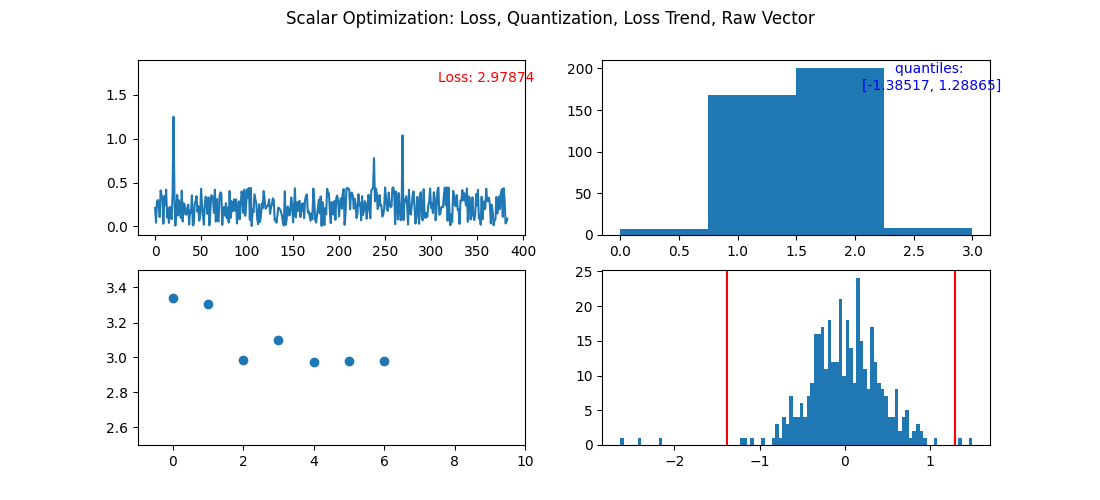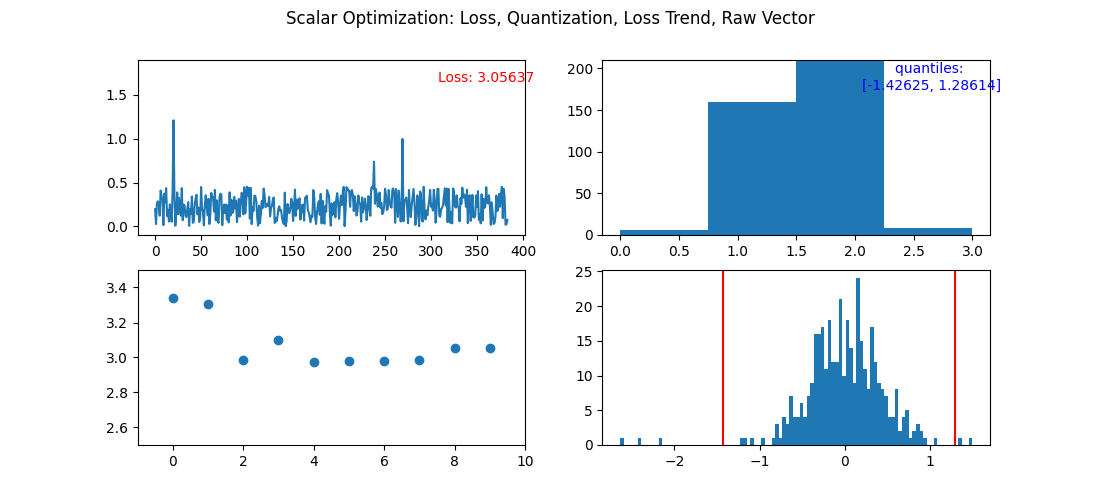
Here is a step by step view of optimizing 2 bit vectors. After the fourth iteration, we would normally stop the optimization process as the error (loss) increased. The first cell is each individual components error. The second is the distribution of 2 bit quantized vectors. Third is how the overall error is changing. Fourth is current step's quantiles overlayed of the raw vector being quantized.
Storage and retrieval of optimized scalar quantization
The storage and retrieval of optimized scalar quantization vectors are similar to BBQ. The main difference is the particular values we store.

Stored for every binary quantized vector: dims/8 bytes, upper and lower quantiles, an additional correction term, the sum of the quantized components.
One piece of nuance is the correction term. For Euclidean distance, we store the squared norm of the centered vector. For dot product we store the dot product between the centroid and the uncentered vector.
Performance
Enough talk. Here are the results from four datasets.
- Cohere's 768 dimensioned multi-lingual embeddings. This is a well distributed inner-product dataset.
- Cohere's 1024 dimensioned multi-lingual embeddings. This embedding model is well optimized for quantization.
- E5-Small-v2 quantized over the quora dataset. This model typically does poorly with binary quantization.
- GIST-1M dataset. This scientific dataset opens some interesting edge cases for inner-product and quantization.
Here are the results for Recall@10|50
| Dataset | BBQ | BBQ with OSQ | Improvement |
|---|---|---|---|
| Cohere 768 | 0.933 | 0.938 | 0.5% |
| Cohere 1024 | 0.932 | 0.945 | 1.3% |
| E5-Small-v2 | 0.972 | 0.975 | 0.3% |
| GIST-1M | 0.740 | 0.989 | 24.9% |
Across the board, we see that BBQ backed by our new optimized scalar quantization improves recall, and dramatically so for the GIST-1M dataset.
But, what about indexing times? Surely all this per vector optimizations must add up. The answer is no.
Here are the indexing times for the same datasets.
| Dataset | BBQ | BBQ with OSQ | Difference |
|---|---|---|---|
| Cohere 768 | 368.62s | 372.95s | +1% |
| Cohere 1024 | 307.09s | 314.08s | +2% |
| E5-Small-v2 | 227.37s | 229.83s | < +1% |
| GIST-1M | 1300.03s* | 297.13s | -300% |
- Since the quantization methodology works so poorly over GIST-1M when using inner-product, it takes an exceptionally long time to build the HNSW graph as the vector distances are not well distinguished.
Conclusion
Not only does this new, state of the art quantization methodology improve recall for our BBQ indices, it unlocks future optimizations. We can now quantize vectors to any bit size and we want to explore how to provide 2 bit quantization, striking a balance between memory utilization and recall with no reranking.
Frequently Asked Questions
What is optized scalar quantization in Lucene?
Optimized scalar quantization in Lucene is a technique that reduces the memory footprint of vectors by quantizing them into smaller values.
What is optimized scalar quantization?
Optimized scalar quantization optimizes quantiles per individual vector. Allowing for exceptional recall at any bit size, even single bit quantization.
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.
December 23, 2025
Comparing dense vector search performance with the Profile API in Elasticsearch
Learn how to use the Profile API in Elasticsearch to compare dense vector configurations and tune kNN performance with visual data from Kibana.

December 3, 2025
Up to 12x Faster Vector Indexing in Elasticsearch with NVIDIA cuVS: GPU-acceleration Chapter 2
Discover how Elasticsearch achieves nearly 12x higher indexing throughput with GPU-accelerated vector indexing and NVIDIA cuVS.

November 4, 2025
Multimodal search for mountain peaks with Elasticsearch and SigLIP-2
Learn how to implement text-to-image and image-to-image multimodal search using SigLIP-2 embeddings and Elasticsearch kNN vector search. Project focus: finding Mount Ama Dablam peak photos from an Everest trek.

November 3, 2025
Improving multilingual embedding model relevancy with hybrid search reranking
Learn how to improve the relevancy of E5 multilingual embedding model search results using Cohere's reranker and hybrid search in Elasticsearch.