Test Elastic's leading-edge, out-of-the-box capabilities. Dive into our sample notebooks, start a free cloud trial, or try Elastic on your local machine now.
This blog series reveals how our Field Engineering team used the Elastic stack with generative AI to develop a lovable and effective customer support chatbot. If you missed other installments in the series, be sure to check out part one, part two, part three, the launch blog, and part five.
Welcome to part 4 of our blog series on integrating generative AI in Elastic's customer support. This installment dives deep into the role of Retrieval-Augmented Generation (RAG) in enhancing our AI-driven Technical Support Assistant. Here, we address the challenges, solutions, and outcomes of refining search effectiveness, providing action items to further improve its capabilities using the toolset provided in the Elastic Stack version 8.11.
Implied by those actions, we have achieved a ~75% increase in top-3 results relevance and gained over 300,000 AI-generated summaries that we can leverage for all kinds of future applications. If you're new to this series, be sure to review the earlier posts that introduce the core technology and architectural setup. If you missed the last blog of the series, you can find it here.
RAG tuning: A search problem
Perfecting RAG (Retrieval-Augmented Generation) is fundamentally about hitting the bullseye in search accuracy 🎯:
- Like an archer carefully aiming to hit the center of the target, we want to focus on accuracy for each hit.
- Not only that, we also want to ensure that we have the best targets to hit – or high-quality data.
Without both together, there's the potential risk that large language models (LLMs) might hallucinate and generate misleading responses. Such mistakes can definitely shake users' trust in our system, leading to a deflecting usage and poor return on investment.
To avoid those negative implications, we've encountered several challenges that have helped us refine our search accuracy and data quality over the course of our journey. These challenges have been instrumental in shaping our approach to tuning RAG for relevance, and we're excited to share our insights with you.
That said: let's dive into the details!
Our first approach
We started with a lean, effective solution that could quickly get us a valuable RAG-powered chatbot in production. This meant focusing on key functional aspects that would bring it to operational readiness with optimal search capabilities. To get us into context, we'll make a quick walkthrough around four key vital components of the Support AI Assistant: data, querying, generation, and feedback.
Data
As showcased in the 2nd blog article of this series, our journey began with an extensive database that included over 300,000 documents consisting of Technical Support Knowledge Articles and various pages crawled from our website, such as Elastic's Product Documentation and Blogs. This rich dataset served as the foundation for our search queries, ensuring a broad spectrum of information about Elastic products was available for precise retrieval. To this end, we leveraged Elasticsearch to store and search our data.
Query
Having great data to search by, it's time to talk about our querying component. We adopted a standard Hybrid-Search strategy, which combines the traditional strengths of BM25, Keyword-based Search, with the capabilities of Semantic Search, powered by ELSER.
For the semantic search component, we used text_expansion queries against both title and summary embeddings. On the other hand, for broad keyword relevance we search multiple fields using cross_fields, with a minimum_should_match parameter tuned to better perform with longer queries. Phrase matches, which often signal greater relevance, receive a higher boost. Here’s our initial setup:
Generation
After search, we build up the system prompt with different sets of instructions, also contemplating the top 3 search results as context to be used. Finally, we feed the conversation alongside the built context into the LLM, generating a response. Here's the pseudocode showing the described behavior:
The reason for not including more than 3 search results was the limited quantity of tokens available to work within our dedicated Azure OpenAI's GPT4 deployment (PTU), allied with a relatively large user base.
Feedback
We used a third-party tool to capture client-side events, connecting to Big Query for storage and making the JSON-encoded events accessible for comprehensive analysis by everyone on the team. Here's a glance into the Big Query syntax that builds up our feedback view. The
JSON_VALUE function is a means to extract fields from the event payload:
We also took advantage of valuable direct feedback from internal users regarding the chatbot experience, enabling us to quickly identify areas where our search results did not match the user intent. Incorporating both would be instrumental in the discovery process that enabled us to refine our RAG implementation, as we're going to observe throughout the next section.
Challenges
With usage, interesting patterns started to emerge from feedback. Some user queries, like those involving specific CVEs or Product Versions for instance, were yielding suboptimal results, indicating a disconnect between the user's intent and the GenAI responses. Let's take a closer look at the specific challenges identified, and how we solved them.
#1: CVEs (Common Vulnerabilities and Exposures)
Our customers frequently encounter alerts regarding lists of open CVEs that could impact their systems, often resulting in support cases. To address questions about those effectively, our dedicated internal teams meticulously maintain CVE-type Knowledge Articles. These articles provide standardized, official descriptions from Elastic, including detailed statements on the implications, and list the artifacts affected by each CVE.
Recognizing the potential of our chatbot to streamline access to this crucial information, our internal InfoSec and Support Engineering teams began exploring its capabilities with questions like this:
For such questions, one of the key advantages of using RAG – and also the main functional goal of adopting this design – is that we can pull up-to-date information, including it as context to the LLM and thus making it available instantly to produce awesome responses. That naturally will save us time and resources over fine-tuned LLM alternatives.
However, the produced responses wouldn't perform as expected. Essential to answer those questions, the search results often lacked relevance, a fact which we can confirm by looking closely at the search results for the example:
With just one relevant hit (CVE-2019-10172), we left the LLM without the necessary context to generate proper answers:
The observed behavior prompted us with an interesting question:
How could we use the fact that users often include close-to-exact CVE codes in their queries to enhance the accuracy of our search results?
To solve this, we approached the issue as a search challenge. We hypothesized that by emphasizing the title field matching for such articles, which directly contain the CVE codes, we could significantly improve the precision of our search results. This led to a strategic decision to conditionally boost the weighting of title matches in our search algorithm. By implementing this focused adjustment, we refined our query strategy as follows:
As a result, we experienced much better hits for CVE-related use cases, ensuring that CVE-2016-1837, CVE-2019-11756 and CVE-2014-6439 are top 3:
And thus generating a much better response by the LLM:
Lovely! By tuning our Hybrid Search approach, we significantly improved our performance with a pretty simple, but mostly effective Bob's Your Uncle solution (like some folks would say)! This improvement underscores that while semantic search is a powerful tool, understanding and leveraging user intent is crucial for optimizing search results and overall chat experience in your business reality. With that in mind, let's dive into the next challenge!
#2: Product versions
As we delved deeper into the challenges, another significant issue emerged with queries related to specific versions. Users frequently inquire about features, migration guides, or version comparisons, but our initial search responses were not meeting expectations. For instance, let's take the following question:
Our initial query approach would return the following top 3:
- Elasticsearch for Apache Hadoop version 8.14.1 | Elasticsearch for Apache Hadoop [8.14] | Elastic;
- APM version 8.14 | Elastic Observability [8.14] | Elastic;
- Elasticsearch for Apache Hadoop version 8.14.3 | Elasticsearch for Apache Hadoop [8.14] | Elastic.
Corresponding to the following _search response:
Being irrevocably irrelevant, they ended up resulting in a completely uninformed answer from the chatbot, affecting the overall user experience and trust in the Support AI Assistant:
Further investigating the issue we collected valuable insights. By replaying the query and looking into the search results, we noticed three serious problems with our crawled Product Documentation data that were contributing to the overall bad performance:
- Inaccurate semantic matching: Semantically, we definitely missed the shot. Why would we match against such specific articles, including two specifically about Apache Hadoop, when the question was so much broader than Hadoop?
- Multiple versions, same articles: Going further down on the hits of the initially asked question, we often noticed multiple versions for the same articles, with close to exactly the same content. That often led to a top 3 cluttered with irrelevant matches!
- Wrong versions being returned: It's fair to expect that having both 8.14.1 and 8.14.2 versions of the Elasticsearch for Apache Hadoop article, we'd return the latter for our query – but that just wasn't happening consistently.
From the impact perspective, we had to stop and solve those – else, a considerable part of user queries would be affected. Let's dive into the approaches taken to solve both!
A. Inaccurate semantic matching
After some examination into our data, we've discovered that the root of our semantic matching issue lived in the fact that the summary field for Product Documentation-type articles generated upon ingestion by the crawler was just the first few characters of the body. This redundancy misled our semantic model, causing it to generate vector embeddings that did not accurately represent the document's content in relation to user queries.
As a data problem, we had to solve this problem in the data domain: by leveraging the use of GenAI and the GPT4 model, we made a team decision to craft a new AI Enrichment Service – introduced in the 2nd installment of this blog series. We decided to create our own tool for a few specific reasons:
- We had unused PTU resources available. Why not use them?
- We needed this data gap filled quickly, as this was probably the greatest relevance detractor.
- We wanted a fully customizable approach to make our own experiments.
Modeled to be generic, our usage for it boils down to generating four new fields for our data into a new index, using Enrich Processors to make them available to the respective documents on the target indices upon ingestion. Here's a quick view into the specification for each field to be generated:
After generating those fields and setting up the index Enrich Processors, the underlying RAG-search indices were enriched with a new ai_fields object, also making ELSER embeddings available under ai_fields.ml.inference:
Now, we can tune the query to use those fields, making for better overall semantic and keyword matching:
Single-handedly, that made us much more relevant. More than that – it also opened a lot of new possibilities to use the AI-generated data throughout our applications – matters of which we'll talk about in future blog posts.
Now, before retrying the query to check the results: what about the multiple versions problem?
B. Multiple versions, same articles
When duplicate content infiltrates these top positions, it diminishes the value of the data pool, thereby diluting the effectiveness of GenAI responses and leading to a suboptimal user experience. In this context, a significant challenge we encountered was the presence of multiple versions of the same article. This redundancy, while contributing to a rich collection of version-specific data, often cluttered the essential data feed to our LLM, reducing the diversity of it and therefore undermining the response quality.
To address the problem, we employed the
Elasticsearch API collapse parameter, sifting through the noise and prioritizing only the most relevant version of a single content. To do that, we computed a new slug field into our Product Documentation crawled documents to identify different versions of the same article, using it as the collapse field (or key).
Taking the Sort search results documentation page as an example, we have two versions of this article being crawled:
- Sort search results | Elasticsearch Guide [8.14] | Elastic
- Sort search results | Elasticsearch Guide [7.17] | Elastic
Those two will generate the following slug:
guide-en-elasticsearch-reference-sort-search-results
Taking advantage of that, we can now tune the query to use collapse:
As a result, we'll now only show the top-scored documentation in the search results, which will definitely contribute to increasing the diversity of knowledge being sent to the LLM.
C. Wrong versions being returned
Similar to the CVE matching problem, we can boost results based on the specific versions being mentioned, allied with the fact that version is a separate field in our index. To do that, we used the following simple regex-based function to pull off versions directly from the user question:
We then add one more query to the should clause, boosting the version field accordingly and getting the right versions to the top (whenever they're mentioned):
With A, B and C solved, we're probably ready to see some strong results!
Let's replay the question!
By replaying the previously tried question:
And therefore running the Elasticsearch query once again, we get dramatically better results consisting of the following articles:
- Elasticsearch version 8.14.3 | Elasticsearch Guide [master] | Elastic
- Elasticsearch version 8.14.2 | Elasticsearch Guide [master] | Elastic
- Release notes | Elasticsearch Guide [8.14] | Elastic
Consequently, we have a better answer generated by the LLM. More powerful than that – in the context of this conversation, the LLM is now conscious about versions of Elasticsearch that are newer than the model's cut-off date, crafting correct answers around those:
Exciting, right? But how can we quantify the improvements in our query at this point? Let's see the numbers together!
Measuring success
To assess the performance implied by our changes, we've compiled a test suite based on user behavior, each containing a question plus a curated list of results that are considered relevant to answer it. Those will cover a wide wide range of subjects and query styles, reflecting the diverse needs of our users. Here's a complete look into it:
But how do we turn those test cases into quantifiable success? To this end, we have employed Elasticsearch's Ranking Evaluation API alongside with the Precision at K (P@K) metric to determine how many relevant results are returned between the first K hits of a query. As we're interested in the top 3 results being fed into the LLM, we're making K = 3 here.
To automate the computation of this metric against our curated list of questions and effectively assess our performance gains, we used TypeScript/Node.js to create a simple script wrapping everything up. First, we define a function to make the corresponding Ranking Evaluation API calls:
After that, we need to define the search queries before and after the optimizations:
Then, we'll output the resulting metrics for each query:
Finally, by running the script against our development Elasticsearch instance, we can see the following output demonstrating the P@K or (P@3) values for each query, before and after the changes. That is – how many results on the top 3 are considered relevant to the response:
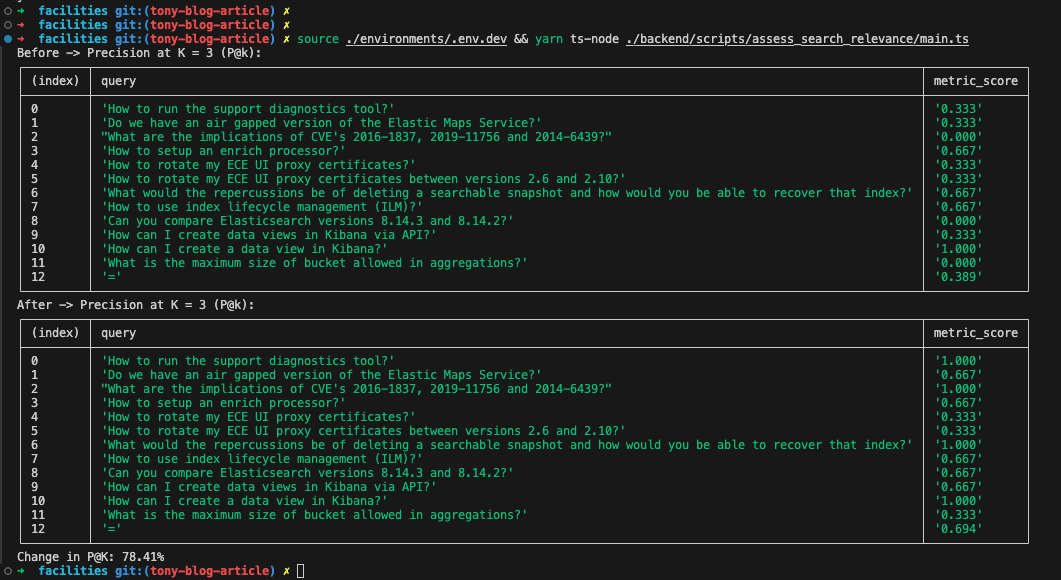
Improvements observed
As an archer carefully adjusts for a precise shot, our recent efforts into relevance have brought considerable improvements in precision over time. Each one of the previous enhancements, in sequence, were small steps towards achieving better accuracy in our RAG-search results, and overall user experience. Here's a look at how our efforts have improved performance across various queries:
Before and after –
Relevant results in the top 3:❌ = 0,🥉 = 1,🥈 = 2,🥇 = 3.
| Query Description | P@K Before | P@K After | Change |
|---|---|---|---|
| Support Diagnostics Tool | 0.333 🥉 | 1.000 🥇 | +200% |
| Air Gapped Maps Service | 0.333 🥉 | 0.667 🥈 | +100% |
| CVE Implications | 0.000 ❌ | 1.000 🥇 | ∞ |
| Enrich Processor Setup | 0.667 🥈 | 0.667 🥈 | 0% |
| Proxy Certificates Rotation | 0.333 🥉 | 0.333 🥉 | 0% |
| Proxy Certificates Version-specific Rotation | 0.333 🥉 | 0.333 🥉 | 0% |
| Searchable Snapshot Deletion | 0.667 🥈 | 1.000 🥇 | +50% |
| Index Lifecycle Management Usage | 0.667 🥈 | 0.667 🥈 | 0% |
| Creating Data Views via API in Kibana | 0.333 🥉 | 0.667 🥈 | +100% |
| Kibana Data View Creation | 1.000 🥇 | 1.000 🥇 | 0% |
| Comparing Elasticsearch Versions | 0.000 ❌ | 0.667 🥈 | ∞ |
| Maximum Bucket Size in Aggregations | 0.000 ❌ | 0.333 🥉 | ∞ |
Average P@K Improvement: +78.41% 🏆🎉. Let's summarize a few observations about our results:
Significant Improvements: With the measured overall +78.41% of relevance increase, the following queries – Support Diagnostics Tool, CVE implications, Searchable Snapshot Deletion, Comparing Elasticsearch Versions – showed substantial enhancements. These areas not only reached the podium of search relevance but did so with flying colors, significantly outpacing their initial performances!
Opportunities for Optimization: Certain queries like the Enrich Processor Setup, Kibana Data View Creation and Proxy Certificates Rotation have shown reliable performances, without regressions. These results underscore the effectiveness of our core search strategies. However, those remind us that precision in search is an ongoing effort. These static results highlight where we'll focus our efforts to sharpen our aim throughout the next iterations. As we continue, we'll also expand our test suite, incorporating more diverse and meticulously selected use cases to ensure our enhancements are both relevant and robust.
What's next? 🔎
The path ahead is marked by opportunities for further gains, and with each iteration, we aim to push the RAG implementation performance and overall experience even higher. With that, let's discuss areas that we're currently interested in!
- Our data can be futher optimized for search: Although we have a large base of sources, we observed that having semantically close search candidates often led to less effective chatbot responses. Some of the crawled pages aren't really valuable, and often generate noise that impacts relevance negatively. To solve that, we can curate and enhance our existing knowledge base by applying a plethora of techniques, making it lean and effective to ensure an optimal search experience.
- Chatbots must handle conversations – and so must RAG searches: It's common user behavior to ask follow-up questions to the chatbot. A question asking "How to configure Elasticsearch on a Linux machine?" followed by "What about Windows?" should query something like "How to configure Elasticsearch on a Linux machine?" (not the raw 2nd question). The RAG query approach should find the most relevant content regarding the entire context of the conversation.
- Conditional context inclusion: By extracting the semantic meaning of the user question, it would be possible to conditionally include pieces of data as context, saving token limits, making the generated content even more relevant, and potentially saving round trips for search and external services.
Conclusion
In this installment of our series on GenAI for Customer Support, we have thoroughly explored the enhancements to the Retrieval-Augmented Generation (RAG) search within Elastic's customer support systems. By refining the interaction between large language models and our search algorithms, we have successfully elevated the precision and effectiveness of the Support AI Assistant.
Looking ahead, we aim to further optimize our search capabilities and expand our understanding of user interactions. This continuous improvement will focus on refining our AI models and search algorithms to better serve user needs and enhance overall customer satisfaction.
Stay tuned for more insights and updates as we continue to push the boundaries of what's possible with AI in customer support, and don't forget to join us in our next discussion, where we'll explore how Observability plays a critical role in monitoring, diagnosing, and optimizing the performance and reliability of the Support AI Assistant as we scale!
Related Content
December 22, 2025
Influencing BM25 ranking with multiplicative boosting in Elasticsearch
Learn why additive boosting methods can destabilize BM25 rankings and how multiplicative scoring provides controlled, scalable ranking influence in Elasticsearch.

December 19, 2025
Elasticsearch Serverless pricing demystified: VCUs and ECUs explained
Learn how Elasticsearch Serverless pricing works for Elastic’s fully-managed deployment offering. We explain VCUs (Search, Ingest, ML) and ECUs, detailing how consumption is based on actual allocated resources, workload complexity, and Search Power.

December 17, 2025
Boosting e-commerce search by profit and popularity with the function score query in Elasticsearch
Discover how to optimize e-commerce search by blending BM25 relevance with profit margin and popularity signals in Elasticsearch using the function_score query.
December 16, 2025
Reducing Elasticsearch frozen tier costs with Deepfreeze S3 Glacier archival
Learn how to leverage Deepfreeze in Elasticsearch to automate searchable snapshot repository rotation, retaining historical data and aging it into lower cost S3 Glacier tiers after index deletion.
December 11, 2025
Evaluating search query relevance with judgment lists
Explore how to build judgment lists to objectively evaluate search query relevance and improve performance metrics such as recall, for scalable search testing in Elasticsearch.