Free yourself from operations with Elastic Cloud Serverless. Scale automatically, handle load spikes, and focus on building—start a 14-day free trial to test it out yourself!
You can follow these guides to build an AI-Powered search experience or search across business systems and software.
Recently, we’ve launched the Elastic Cloud Serverless offering that aims to provide a seamless experience to run search workloads in the cloud. To launch this, we’ve rearchitected Elasticsearch to decouple storage from compute, where data is stored in a cloud blob store that provides virtually infinite storage and scalability. In this blog post, we’ll dive into how we removed a strong relationship between the number of indices and the number of object store calls, allowing us to improve UX and reduce costs at the same time.
Before we dive into the changes we made, it’s essential to first understand the interplay between Elasticsearch and Lucene.
Elasticsearch uses Lucene, a high-performance, open-source library written in Java, for full text indexing and search. When a document is indexed into Elasticsearch, it isn't immediately written to disk by Lucene. Instead, Lucene updates its internal in-memory data structures. Once enough data accumulates or a refresh is triggered, these documents are then written to disk, creating a new set of immutable files known as segments in Lucene terminology. The indexed documents are not available for search until the segments are written to disk. That’s the reason why refresh is such an important concept in Elasticsearch. You might be wondering how durability is ensured when documents are kept in memory until a refresh is triggered. This is achieved through the Translog, which stores durably every operation to guarantee data persistence and recovery in case of failure.
Now that we know what Lucene segments are and why refreshes are needed in Elasticsearch, we can explore how refresh behavior differs between stateful Elasticsearch and serverless Elasticsearch.
Refreshes in stateful Elasticsearch
In Elasticsearch, indices are divided into multiple shards, each consisting of a primary shard and potentially multiple replica shards. In stateful Elasticsearch, when a document is indexed, it is first routed to the primary shard, where Lucene processes and indexes it. After indexing on the primary shard, the document is then routed to the replica shards, where it is indexed by these copies.
As mentioned earlier, a refresh is needed to make these indexed documents searchable. In stateful Elasticsearch, a refresh writes the Lucene in-memory data structures to disk without performing an fsync. Refreshes are scheduled periodically, with each node executing them at different times. This process will create distinct Lucene segment files on each node, all containing the same set of documents.
Refreshes in serverless Elasticsearch
In contrast, serverless Elasticsearch employs a segment-based replication model. In this approach, one node per shard handles document indexing and generates Lucene segments. These segments are uploaded to the blob store once a refresh is initiated. Subsequently, search nodes are informed about these new Lucene segments, which they can read directly from the blob store.
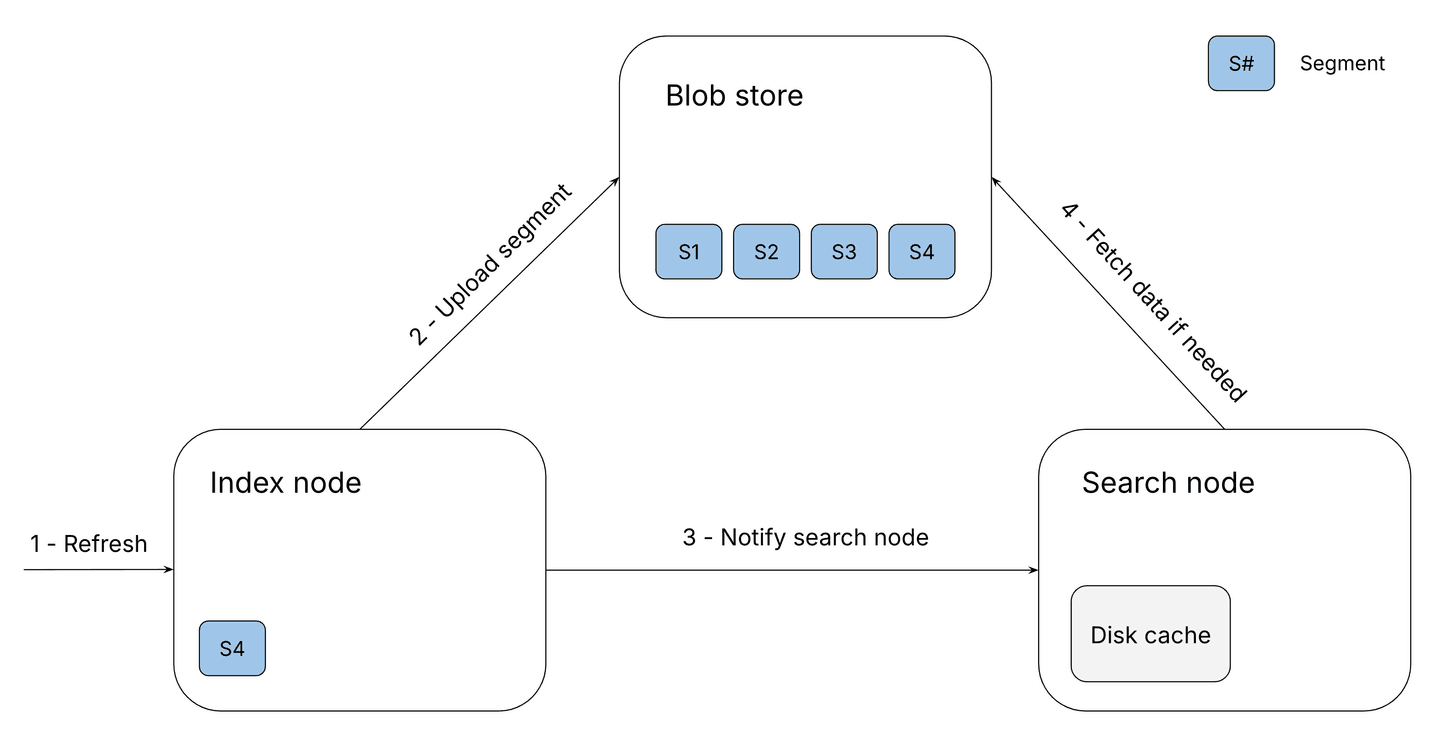
The illustration above demonstrates how a refresh works in serverless Elasticsearch:
- The indexing node, where all the documents were indexed, receives the refresh request and Lucene writes the in-memory data structures to disk, similar to how a stateful refresh operates.
- The segment files are uploaded to the blob store as a single file (known as a stateless compound commit). In the illustration, S4 is uploaded.
- Once the segment files are uploaded to the blob store, the indexing node sends a message to each search node, notifying them of the new segment files so they can perform searches on the newly indexed documents.
- The search nodes fetch the necessary data from the blob store when executing searches.
This model offers the advantage of lightweight nodes, as data is stored in the blob store. This makes scaling or reallocating workloads between nodes more cost-effective compared to stateful Elasticsearch, where data must be transferred to the new node containing the new shard.
One aspect worth considering is the additional object store request costs associated with each refresh in serverless Elasticsearch. Every refresh operation created a new object in the object store, resulting in an object store PUT request that incurs associated costs. This led to a linear relationship between the number of indices and the number of object store PUT requests. With enough refreshes, object store costs could surpass the cost of the hardware itself. To address this, we initially implemented refresh throttling measures to manage costs effectively and mitigate potential issues over time. This blog post describes the next step in that effort, which allowed us to refresh faster and at a manageable cost.
Refresh cost optimizations in serverless Elasticsearch
As previously mentioned, the serverless Elasticsearch architecture provides numerous benefits. However, to manage refresh costs effectively, we made decisions that occasionally impacted user experience. One such decision was enforcing a default refresh interval of 15 seconds, meaning that in some cases, newly indexed data won't become searchable until 15 seconds have passed. Despite our efforts, scenarios arose where object store expenses became prohibitive, prompting us to reassess our approach. In this section, we will delve into how we successfully decoupled refresh operations from object store calls to address these challenges without compromising user experience.
After evaluating various solutions—from temporary storage of segments in distributed file systems like NFS to direct pushing of segments into search nodes—we settled on an approach relying on serving segment data from indexing nodes directly to search nodes.
Rather than letting refresh immediately upload new Lucene segments to the blob store, index nodes now accumulate segments from refreshes and upload them as a single blob later. This enables index nodes to serve reads from search nodes in a manner akin to a blob store, delaying segment uploads until sufficient data accumulates or a predetermined time interval elapses.
This strategy grants us complete control over the size of the blobs uploaded to the blob store, enabling us to determine when request costs become negligible in comparison to hardware costs.
Batched compound commits
We aimed to implement this enhancement incrementally and ensure backward compatibility with existing data stored in the blob store. Therefore, we opted to maintain the same file format for storing Lucene segments in the blob store. For context, Lucene segments comprise multiple files, each serving a distinct role. To streamline the upload process and minimize PUT requests, we introduced compound commits: single blobs containing all segment files consecutively, accompanied by a metadata header, including a directory of the files in the compound commit.
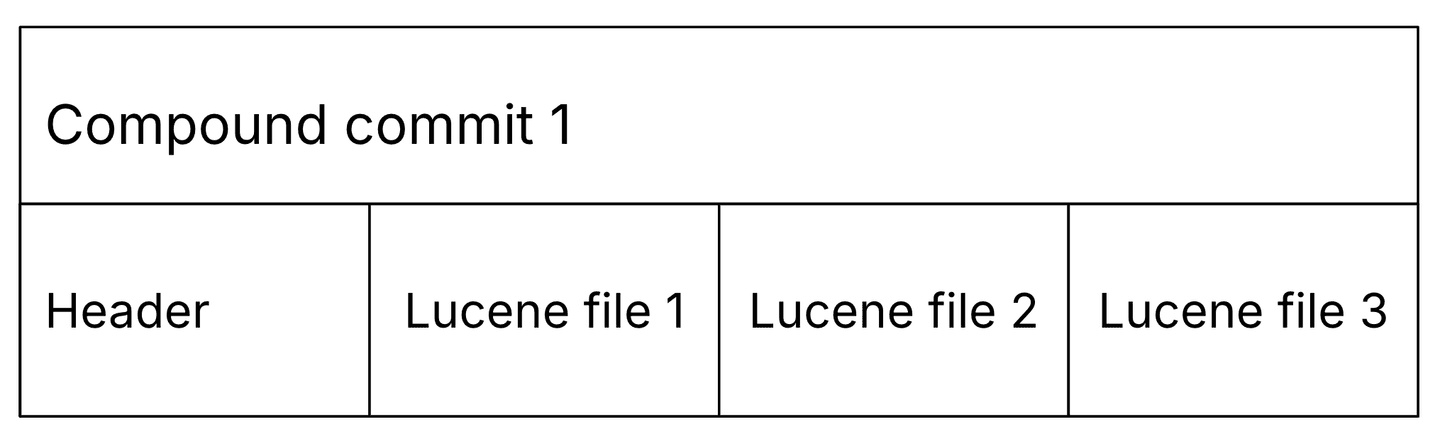
When retrieving a compound commit from the blob store, such as during shard relocation, our primary focus is typically on the compound commit header. This header is crucial as it contains the essential data needed to promptly populate internal data structures. With this in mind, we realized we could maintain the existing file format but streamline it so that each blob would sequentially append one compound commit after another. We denominated this new file format, batched compound commit.

Since each compound commit's size is stored in its header, retrieving the headers of all compound commits within a batched compound commit is straightforward; we can sequentially read each header by simply seeking the next entry. When handling blobs in the old format, they are treated as singleton batched compound commits. Another critical aspect of our file format is maintaining fixed offsets for each Lucene segment file once it's appended into a batched compound commit. This ensures consistency whether the file is served from the index node or the blob store. It also prevents the need to evict cached entries on search nodes when the batched compound commit is eventually uploaded to the blob store.
New refresh lifecycle
Index nodes will now accumulate Lucene segments from refreshes until enough data is gathered to upload them as a single blob. Let us explore how index and search nodes coordinate to determine where to access this data from.
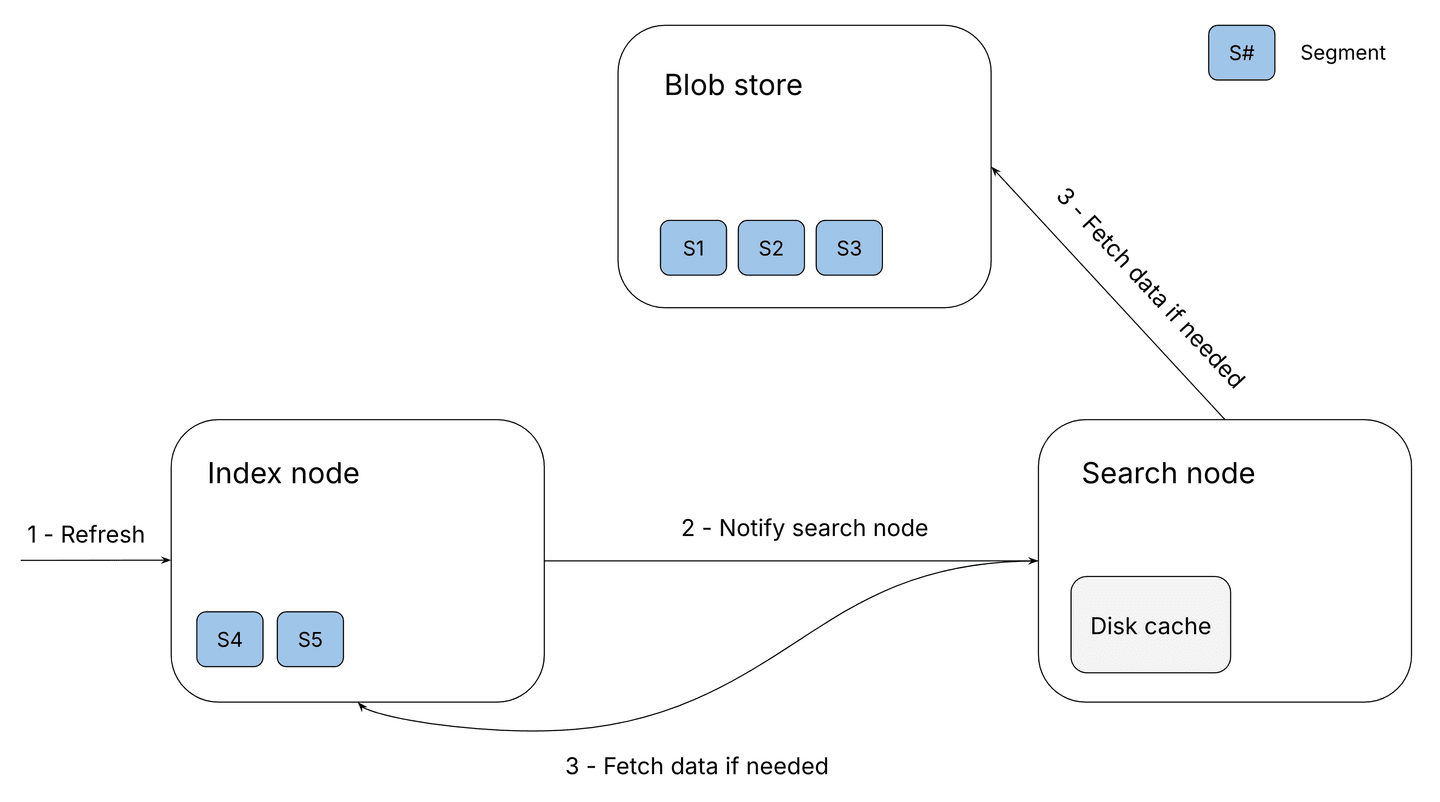
As shown in the illustration above, the following steps occur during the optimized refresh process in serverless Elasticsearch:
- The index node receives a refresh request, writes a new set of Lucene segments to its local disk, and adds these segments to the pending batched compound commit for eventual upload.
- The index node notifies the search node about these new segments, providing details about the involved segments and their locations (blob store or index node).
- When a search node needs a segment to fulfill a query, it decides whether to get it from the blob store or the index node and caches the data locally.
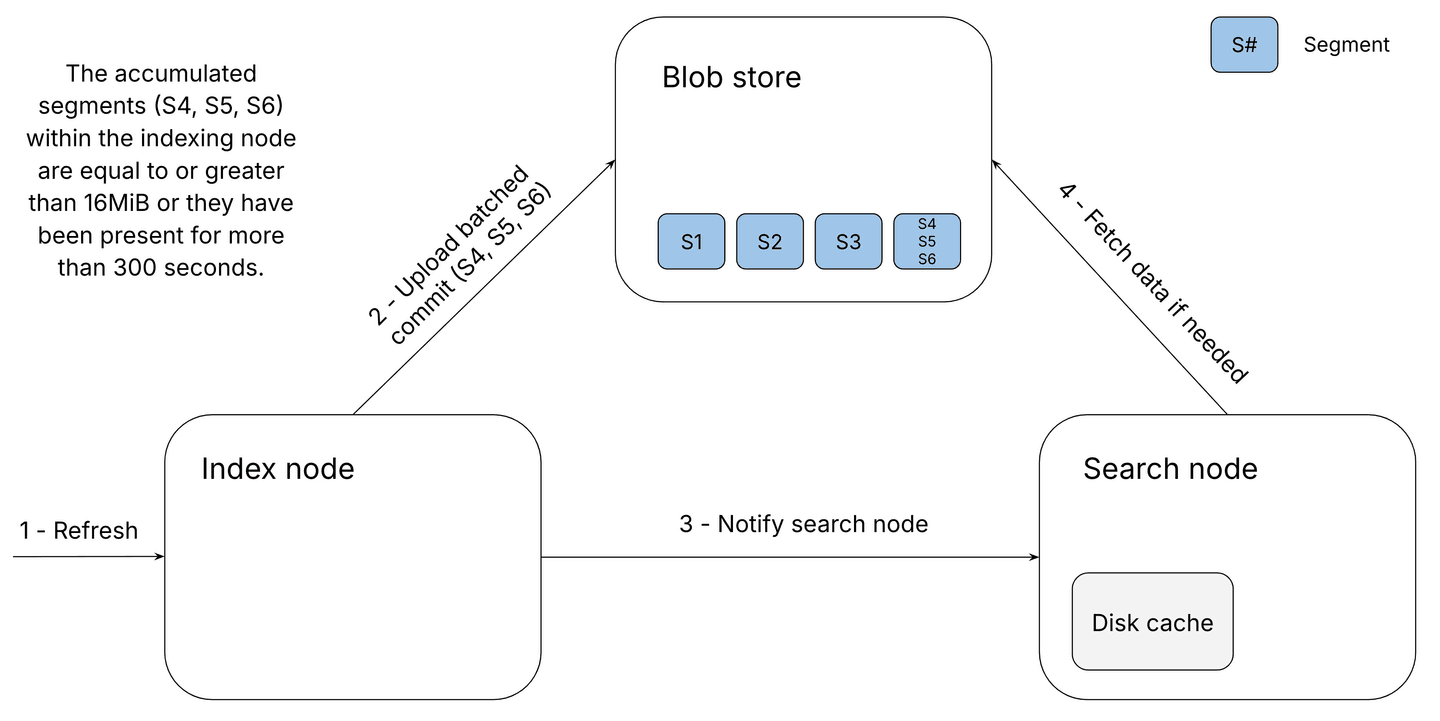
The image above illustrates the process of uploading data to the blob store in serverless Elasticsearch once enough segments have accumulated in the indexing nodes or after a specified amount of time has elapsed.
- A refresh adds a new segment to the batched compound commit and the accumulated data reaches 16 MB, or a certain amount of time has passed since the last refresh, from this point onwards new segments are accumulated into a new batched compound commit.
- The indexing node begins uploading the accumulated segments as a single blob to the object store.
- The indexing node notifies the search node replicas of the latest segment uploaded to the object store, instructing them to fetch data from these segments from the blob store going forward.
- If a search requires data that isn't cached locally, it will retrieve the necessary information from the blob store, while any previously fetched data from the indexing node remains valid even after the upload.
Considerations and tradeoffs
The approach chosen blurs the clear separation between storage and compute, requiring index nodes to handle storage requests until Lucene segments are eventually uploaded to the blob store. However, the overhead from these storage requests is minimal and we have not observed impact on indexing throughput.
We'll note that we keep translog entries until corresponding data has been uploaded to the blob store, hence the approach maintains existing data safety guarantees. Recovery times after a crash may be slightly longer, but we consider this an acceptable trade-off.
Conclusions
This blog post has explored our transition towards a more cloud-native approach, emphasizing its many benefits alongside the critical cost consideration. We traced our evolution from a model where each new Lucene segment generated a distinct object in the object store. This led to cost and user experience challenges in specific serverless workloads compared to stateful Elasticsearch. Batching object store uploads enabled us to minimize the number of object store requests and enhance the cost efficiency of our serverless offering.
Acknowledgments
We would like to acknowledge the contributions of Iraklis Psaroudakis, Tanguy Leroux, and Yang Wang. Their efforts were instrumental in the success of this project.
Related Content
January 22, 2026
Agent Builder now GA: Ship context-driven agents in minutes
Agent Builder is now GA. Learn how it allows you to quickly develop context-driven AI agents.

January 14, 2026
Higher throughput and lower latency: Elastic Cloud Serverless on AWS gets a significant performance boost
We've upgraded the AWS infrastructure for Elasticsearch Serverless to newer, faster hardware. Learn how this massive performance boost delivers faster queries, better scaling, and lower costs.

March 4, 2025
The AI Agent to manage Elasticsearch Serverless projects
A natural language-powered AI agent that effortlessly manages Elasticsearch Serverless projects—enabling project creation, deletion, and status checks.

December 10, 2024
Autosharding of data streams in Elasticsearch Serverless
In Elastic Cloud Serverless we spare our users from the need to fiddle with sharding by automatically configuring the optimal number of shards for data streams based on the indexing load.

December 2, 2024
Elasticsearch Serverless is now generally available
Elasticsearch Serverless, built on a new stateless architecture, is generally available. It’s fully managed so you can get projects started quickly without operations or upgrades, and you can access the latest vector search and generative AI capabilities.