Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
Autocomplete is a crucial feature in search applications, enhancing user experience by providing real-time suggestions as users type. Traditionally, autocomplete in Elasticsearch is implemented using the completion suggester, which relies on predefined terms. This approach requires manual curation of suggestion terms and often lacks contextual relevance. By leveraging LLM-generated terms via OpenAI’s completion endpoint, we can build a more intelligent, scalable, and automated autocomplete feature.
Supercharge Elasticsearch autocomplete with LLMs
In this article, we’ll explore:
- Traditional method of implementing autocomplete in Elasticsearch.
- How integrating OpenAI’s LLM improves autocomplete suggestions.
- Scaling the solution using Ingest Pipeline and Inference Endpoint in Elastic Cloud.
Traditional Elasticsearch autocomplete
The conventional approach to building autocomplete in Elasticsearch involves defining a completion field in the index mapping. This allows Elasticsearch to provide suggestions based on predefined terms. This would be straightforward to implement, especially if you have already built a comprehensive suggestion list for a fairly static dataset.
Implementation steps
- Create an index with a
completionfield. - Manually curate suggestion terms and store them in the index.
- Query using a completion suggester to retrieve relevant suggestions.
Example: Traditional Elasticsearch autocomplete setup
First, create a new index named products_test. In this index, we define a field called suggest of type completion, which is optimized for fast autocomplete suggestions.
Insert a test document into the products_test index. The suggest field stores multiple completion suggestions.
Finally, we use the completion suggester query to search for suggestions starting with "MacB."
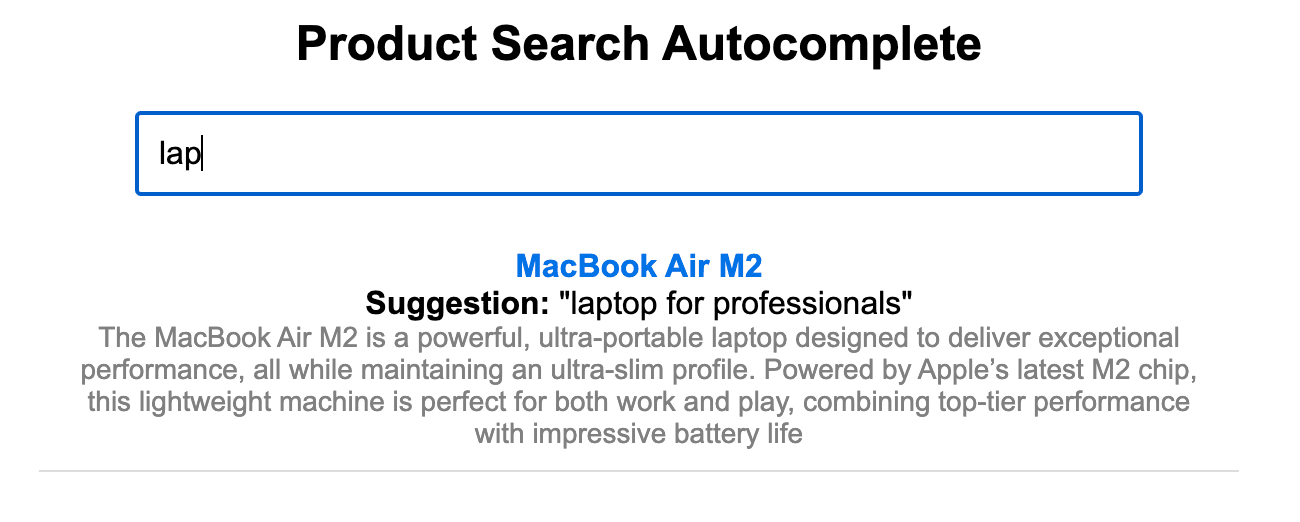
The prefix "MacB" will match "MacBook Air M2."
The suggest section contains matched suggestions. Options contain an array of matching suggestions, where "text": "MacBook Air M2" is the top suggestion.
While effective, this method requires manual curation, constant updates to suggestion terms and does not adapt dynamically to new products or descriptions.
Enhancing Elasticsearch autocomplete with OpenAI LLM
In some use cases, datasets change frequently, which requires you to continuously update a list of valid suggestions. If new products, names, or terms emerge, you have to manually add them to the suggestion list. This is where LLM steps in, as it can dynamically generate relevant completions based on real-world knowledge and live data.
By leveraging OpenAI’s completion endpoint, we can dynamically generate autocomplete suggestions based on product names and descriptions. This allows for:
- Automatic generation of synonyms and related terms.
- Context-aware suggestions derived from product descriptions.
- No need for manual curation, making the system more scalable.
Steps to implement LLM-powered autocomplete
- Create an inference endpoint using OpenAI’s completion API.
- Set up an Elasticsearch ingest pipeline that queries OpenAI for suggestions using a pre-defined prompt using a script processor
- Store the generated terms in an Elasticsearch index with a completion field.
- Use a search request to fetch dynamic autocomplete results.
All the steps above can be easily completed by copying and pasting the API requests step by step in the Kibana Dev tool. In this example, we will be using the gpt-4o-mini model. You will need to get your OpenAI API key for this step. Login to your OpenAI account and navigate to https://platform.openai.com/api-keys. Next, create a new secret key or use an existing key.
Creating an inference endpoint
First, we create an inference endpoint. This allows us to interact seamlessly with a machine learning model (in this case OpenAI) via API, while still working within Elastic’s interface.
Setting up the Elasticsearch ingest pipeline
By setting up an ingest pipeline, we can process data upon indexing. In this case, the pipeline is named autocomplete-LLM-pipeline and it contains:
- A script processor, which defines the prompt we are sending to OpenAI to get our suggestion list. Product name and product description are included as dynamic values in the prompt.
- An inference processor, which refers to our OpenAI inference endpoint. This processor takes a prompt from the script processor as input, sends it to the LLM model, and stores the result in an output field called
results. - A split processor, which splits the text output from LLM within the
resultsfield into a comma-separated array to fit the format of a completion type field ofsuggest. - 2 remove processors, which remove the
promptandresultsfield after thesuggestfield has been populated.
Indexing sample documents
For this example, we are using the documents API to manually index documents from the dev tool to a temporary index called ‘products’. This is not the autocomplete index we will be using.
Creating index with completion type mapping
Now, we are creating the actual autocomplete index which contains the completion type field called suggest.
Reindexing documents to a designated index via the ingest pipeline
In this step, we are reindexing data from our products index created previously to the actual autocomplete index products_with_suggestion, through our ingest pipeline autocomplete-LLM-Pipeline. The pipeline will process the sample documents from the original index and populate the autocomplete suggest field in the destination index.
Sample LLM autocomplete suggestions
As shown below, the new index (products_with_suggestion) now includes a new field called suggest, which contains an array of terms or synonyms generated by OpenAI LLM.
You can run the following request to check:
Results:
Take note that the generated terms from LLM are not always the same even if the same prompt was used. You can check the resulting terms and see if they are suitable for your search use case. Else, you have the option to modify the prompt in your script processor to get more predictable and consistent suggestion terms.
Testing the LLM autocomplete search
Now, we can test the autocomplete functionality using the completion suggester query. The example below also includes a fuzzy parameter to enhance the user experience by handling minor misspellings in the search query. You can execute the query below in the dev tool and check the suggestion results.
To visualize the autocomplete results, I have implemented a simple search bar that executes a query against the autocomplete index in Elastic Cloud using our client. The search returns result based on terms in the suggestion list generated by LLM as you type.

Scaling with OpenAI inference integration
By using OpenAI’s completion API as an inference endpoint within Elastic Cloud, we can scale this solution efficiently:
- Inference endpoint allows automated and scalable LLM suggestions without having to manually create and maintain your own list.
- Ingest pipeline ensures real-time enrichment of data during indexing.
- Script processor within the ingest pipeline allows easy editing of the prompt in case there is a need to customise the nature of the suggestion list in a more specific way.
- Pipeline execution can also be configured directly upon ingestion as an index template for further automation. This enables the suggestion list to be built on the fly as new products are added to the index.
In terms of cost efficiency, the model is only invoked during the ingestion process, meaning its usage scales with the number of documents processed rather than the search volume. This can result in significant cost savings compared to running the model at search time if you are expecting growth in users or search activity.
Conclusion
Traditionally, autocomplete relies on manually defined terms, which can be limiting and labour intensive. By leveraging OpenAI’s LLM-generated suggestions, we have the option to automate and enhance autocomplete functionality, improving search relevance and user experience. Furthermore, using Elastic’s ingest pipeline and inference endpoint integration ensures an automated, scalable autocomplete system.
Overall, if your search use case requires a very specific set of suggestions from a well maintained and curated list, ingesting the list in bulk via our API conventionally as described in the first part of this article would still be a great and performant option. If managing and updating a suggestion list is a pain point, an LLM-based completion system removes that burden by automatically generating contextually relevant suggestions—without any manual input.
Related Content

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 8, 2026
Hybrid search and multistage retrieval in ES|QL
Explore the multistage retrieval capabilities of ES|QL, using FORK and FUSE commands to integrate hybrid search with semantic reranking and native LLM completions.
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
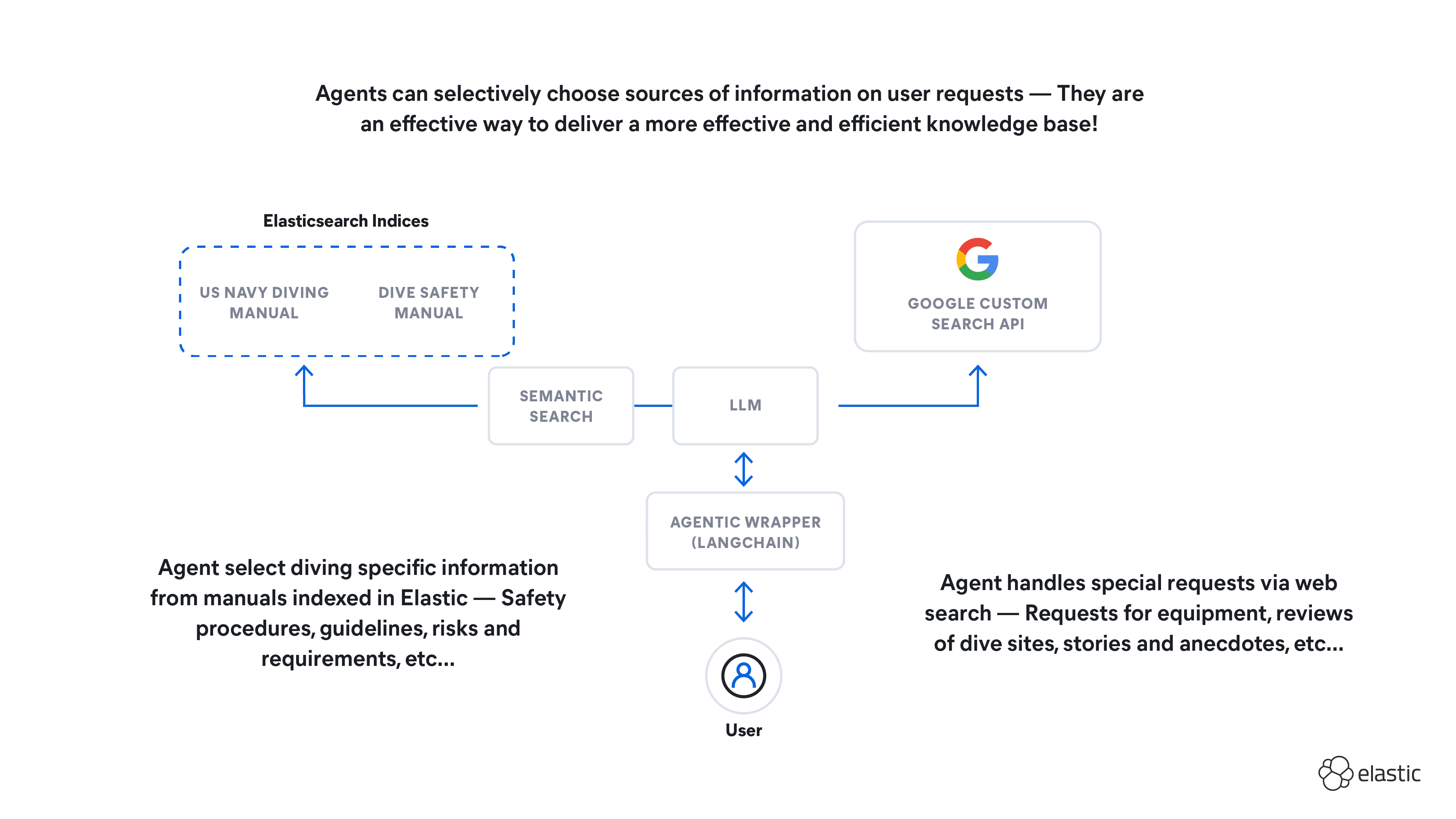
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.