Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
In this blog, you'll learn how to build a multimodal RAG (Retrieval-Augmented Generation) pipeline using Elasticsearch. We'll explore how to leverage ImageBind to generate embeddings for various data types, including text, images, audio, and depth maps. You'll also discover how to efficiently store and retrieve these embeddings in Elasticsearch using dense_vector and k-NN search. Finally, we'll integrate a large language model (LLM) to analyze retrieved evidence and generate a comprehensive final report.
How does the multimodal RAG pipeline work?
- Collecting clues → Images, audio, texts, and depth maps from the crime scene in Gotham.
- Generating embeddings → Each file is converted into a vector using the ImageBind multimodal model.
- Indexing in Elasticsearch → The vectors are stored for efficient retrieval.
- Searching by similarity → Given a new clue, the most similar vectors are retrieved.
- The LLM analyzes the evidence → A GPT-4 model synthesizes the response and identifies the suspect!
Technologies used
- ImageBind → Generates unified embeddings for various modalities.
- Elasticsearch → Enables fast and efficient vector search.
- LLM (GPT-4, OpenAI) → Analyzes the evidence and generates a final report.
Who is this blog for?
- Elastic users interested in multimodal vector search.
- Developers looking to understand Multimodal RAG in practice.
- Anyone searching for scalable solutions for analyzing data from multiple sources.
Prerequisites for multimodal RAG: Setting up the environment
To solve the crime in Gotham City, you need to set up your technology environment. Follow this step-by-step guide:
1. Technical requirements
| Component | Specification |
|---|---|
| Sistem OS | Linux, macOS, or Windows |
| Python | 3.10 or later |
| RAM | Minimum 8GB (16GB recommended) |
| GPU | Optional but recommended for ImageBind |
2. Setting up the project
All investigation materials are available on GitHub, and we'll be using Jupyter Notebook (Google Colab) for this interactive crime-solving experience. Follow these steps to get started:
Setting up with Jupyter Notebook (Google Colab)
1. Access the notebook
- Open our ready-to-use Google Colab notebook: Multimodal RAG with Elasticsearch.
- This notebook contains all the code and explanations you need to follow along.
2. Clone the repository
3. Install dependencies
4. Configure credentials
Note: The ImageBind model (~2GB) will be downloaded automatically on the first run.
Now that everything is set up, let's dive into the details and solve the crime!
Introduction: The crime in Gotham City
On a rainy night in Gotham City, a shocking crime shakes the city. Commissioner Gordon needs your help to unravel the mystery. Clues are scattered across different formats: blurred images, mysterious audio, encrypted texts, and even depth maps. Are you ready to use the most advanced AI technology to solve the case?
In this blog, you will be guided step by step through building a Multimodal RAG (Retrieval-Augmented Generation) system that unifies different types of data (images, audio, texts, and depth maps) into a single search space. We will use ImageBind to generate multimodal embeddings, Elasticsearch to store and retrieve these embeddings, and a Large Language Model (LLM) to analyze the evidence and generate a final report.
Fundamentals: Multimodal RAG architecture
What is a Multimodal RAG?
The rise of Retrieval-Augmented Generation (RAG) Multimodal is revolutionizing the way we interact with AI models. Traditionally, RAG systems work exclusively with text, retrieving relevant information from databases before generating responses. However, the world is not limited to text—images, videos, and audio also carry valuable knowledge. This is why multimodal architectures are gaining prominence, allowing AI systems to combine information from different formats for richer and more precise responses.
Three main approaches for Multimodal RAG
To implement a Multimodal RAG, three strategies are commonly used. Each approach has its own advantages and limitations, depending on the use case:
1. Shared vector space
Data from different modalities are mapped into a common vector space using multimodal models like ImageBind. This allows text queries to retrieve images, videos, and audio without explicit format conversion.
Advantages:
- Enables cross-modal retrieval without requiring explicit format conversion.
- Provides a fluid integration between different modalities, allowing direct retrieval across text, image, audio, and video.
- Scalable for diverse data types, making it useful for large-scale retrieval applications.
Disadvantages:
- Training requires large multimodal datasets, which may not always be available.
- The shared embedding space may introduce semantic drift, where relationships between modalities are not perfectly preserved.
- Bias in multimodal models can impact retrieval accuracy, depending on the dataset distribution.
2. Single grounded modality
All modalities are converted to a single format, usually text, before retrieval. For example, images are described through automatically generated captions, and audio is transcribed into text.
Advantages:
- Simplifies retrieval, as everything is converted into a uniform text representation.
- Works well with existing text-based search engines, eliminating the need for specialized multimodal infrastructure.
- Can improve interpretability since retrieved results are in a human-readable format.
Disadvantages:
- Loss of information: Certain details (e.g., spatial relationships in images, tone in audio) may not be fully captured in text descriptions.
- Dependent on captioning/transcription quality: Errors in automatic annotations can reduce retrieval effectiveness.
- Not optimal for purely visual or auditory queries since the conversion process might remove essential context.
3. Separate retrieval
Maintains distinct models for each modality. The system performs separate searches for each data type and later merges the results.
Advantages:
- Allows custom optimization per modality, improving retrieval accuracy for each type of data.
- Less reliance on complex multimodal models, making it easier to integrate existing retrieval systems.
- Provides fine-grained control over ranking and re-ranking as results from different modalities can be combined dynamically.
Disadvantages:
- Requires fusion of results, making the retrieval and ranking process more complex.
- May generate inconsistent responses if different modalities return conflicting information.
- Higher computational cost since independent searches are performed for each modality, increasing processing time.
Our choice: Shared vector space with ImageBind
Among these approaches, we chose shared vector space, a strategy that aligns perfectly with the need for efficient multimodal searches. Our implementation is based on ImageBind, a model capable of representing multiple modalities (text, image, audio, and video) in a common vector space. This allows us to:
- Perform cross-modal searches between different media formats without needing to convert everything to text.
- Use highly expressive embeddings to capture relationships between different modalities.
- Ensure scalability and efficiency, storing optimized embeddings for fast retrieval in Elasticsearch.
By adopting this approach, we built a robust multimodal search pipeline, where a text query can directly retrieve images or audio without additional pre-processing. This method expands practical applications from intelligent search in large repositories to advanced multimodal recommendation systems.
The following figure illustrates the data flow within the Multimodal RAG pipeline, highlighting the indexing, retrieval, and response generation process based on multimodal data:
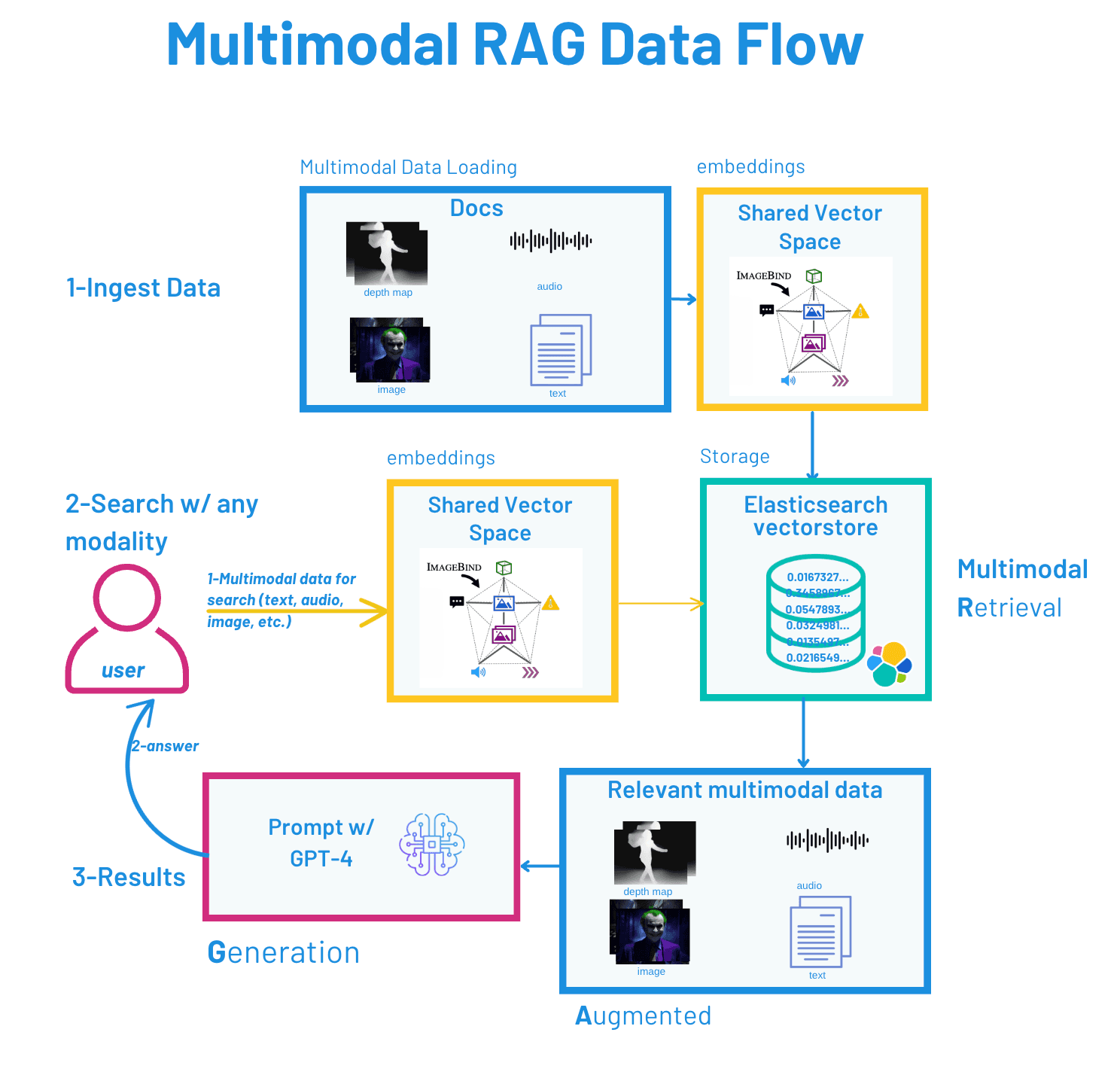
How does the embedding space work?
Traditionally, text embeddings come from language models (e.g., BERT, GPT). Now, with native multimodal models like Meta AI’s ImageBind, we have a backbone that generates vectors for multiple modalities:
- Text: Sentences and paragraphs are transformed into vectors of the same dimension.
- Images (vision): Pixels are mapped into the same dimensional space used for text.
- Audio: Sound signals are converted into embeddings comparable to images and text.
- Depth Maps: Depth data is processed and also results in vectors.
Thus, any clue (text, image, audio, depth) can be compared to any other using vector similarity metrics like cosine similarity. If a laughing audio sample and an image of a suspect's face are “close” in this space, we can infer some correlation (e.g., the same identity).
Stage 1 - Collecting crime scene clues
Before analyzing the evidence, we need to collect it. The crime in Gotham left traces that may be hidden in images, audio, texts, and even depth data. Let's organize these clues to feed into our system.
What do we have?
Commissioner Gordon sent us the following files containing evidence collected from the crime scene in four different modalities:
Track description and modality
a) Images (2 photos)
crime_scene1.jpg, crime_scene2.jpg→ Photos taken from the crime scene. Shows suspicious traces on the ground.suspect_spotted.jpg→ Security camera image showing a silhouette running away from the scene.



b) Audio (1 recording)
joker_laugh.wav→ A microphone near the crime scene captured a sinister laugh.
c) Text (1 message)
Riddle.txt, note2.txt→ Some mysterious notes were found at the location, possibly left by the criminal.

d) Depth (1 depth map)
depth_suspect.png→ A security camera with a depth sensor captured a suspect in a nearby alley.jdancing-depth.png→ A security camera with a depth sensor captured a suspect going down the subway station.


These pieces of evidence are in different formats and cannot be analyzed directly in the same way. We need to transform them into embeddings—numerical vectors that will allow cross-modal comparison.
File organization
Before starting processing, we need to ensure that all clues are properly organized in the data/ directory so the pipeline runs smoothly.
Expected directory structure:
Code to verify clue organization
Before proceeding, let's ensure that all required files are in the correct location.
Running the file
Expected output (if all files are correct):
Expected output (if any file is missing):
This script helps prevent errors before we start generating embeddings and indexing them into Elasticsearch.
Stage 2 - Organizing the evidence
Generating embeddings with ImageBind
To unify the clues, we need to transform them into embeddings—vector representations that capture the meaning of each modality. We will use ImageBind, a model by Meta AI that generates embeddings for different data types (images, audio, text, and depth maps) within a shared vector space.
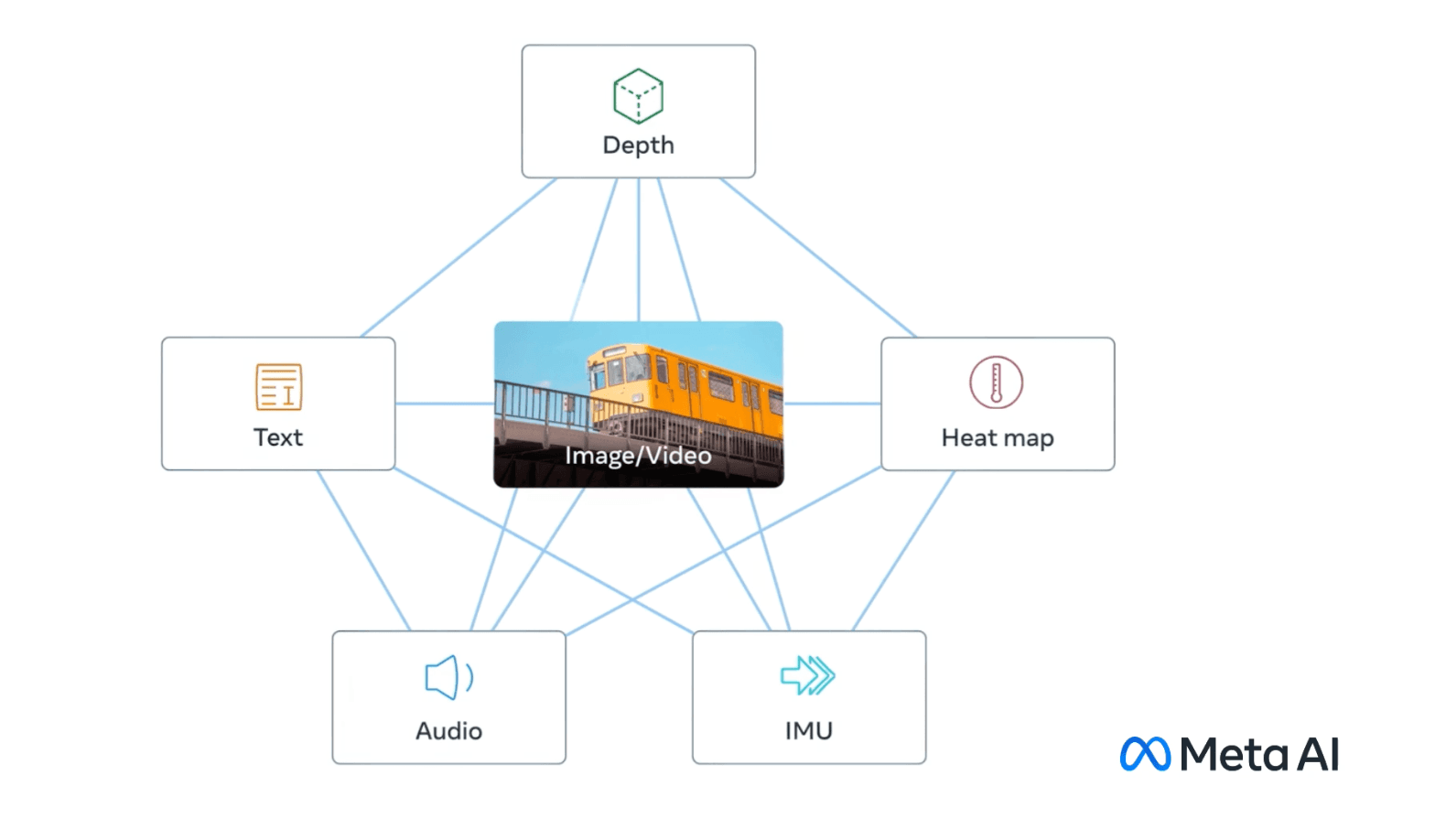
How does ImageBind work?
To compare different types of evidence (images, audio, text, and depth maps), we need to transform them into numerical vectors using ImageBind. This model allows any type of input to be converted into the same embedding format, enabling cross-modal searches between modalities.
Below is an optimized code (src/embedding_generator.py) to generate embeddings for any type of input using the appropriate processors for each modality:
A tensor is a fundamental data structure in machine learning and deep learning, especially when working with models like ImageBind. In our context:
Here, the tensor represents the input data (image, audio, or text) converted into a mathematical format that the model can process. Specifically:
- For images: The tensor represents the image as a multidimensional matrix of numerical values (pixels organized by height, width, and color channels).
- For audio: The tensor represents sound waves as a sequence of amplitudes over time.
- For text: The tensor represents words or tokens as numerical vectors.
Testing embedding generation:
Let's test our embedding generation with the following code. Save it in 02-stage/test_embedding_generation.py and execute it with this command:
Expected output:
Now, the image has been transformed into a 1024-dimensional vector.
Stage 3 - Storage and search in Elasticsearch
Now that we have generated the embeddings for the evidence, we need to store them in a vector database to enable efficient searches. For this, we will use Elasticsearch, which supports dense vectors (dense_vector) and allows similarity searches.
This step consists of two main processes:
- Indexing the embeddings → Stores the generated vectors in Elasticsearch.
- Similarity search → Retrieves the most similar records to a new piece of evidence.
Indexing the evidence in Elasticsearch
Each piece of evidence processed by ImageBind (image, audio, text, or depth) is converted into a 1024-dimensional vector. We need to store these vectors in Elasticsearch to enable future searches.
The following code (src/elastic_manager.py) creates an index in Elasticsearch and configures the mapping to store the embeddings.
Running the indexing
Now, let's index a piece of evidence to test the process.
Expected output in Elasticsearch (summary of the indexed document):
To index all multimodal evidence, please execute the following Python command:
Now, the evidence is stored in Elasticsearch and is ready to be retrieved when needed.
Verifying the indexing process
After running the indexing script, let's verify if all our evidence was correctly stored in Elasticsearch. You can use Kibana's Dev Tools to run some verification queries:
1. First, check if the index was created:
2. Then, verify the document count per modality:
3. Finally, examine the indexed document structure:
Expected results:
- An index named `multimodal_content` should exist.
- Around 7 documents distributed across different modalities (vision, audio, text, depth).
- Each document should contain: embedding, modality, description, metadata, and content_path fields.
This verification step ensures that our evidence database is properly set up before we proceed with the similarity searches.
Searching for similar evidence in Elasticsearch
Now that the evidence has been indexed, we can perform searches to find the most similar records to a new clue. This search uses vector similarity to return the closest records in the embedding space.
The following code performs this search.
Testing the search - Using audio as a query for multimodal results
Now, let's test the search for evidence using a suspicious audio file. We need to generate an embedding for the file in the same way and search for similar embeddings:
Expected output in the terminal:

Now, we can analyze the retrieved evidence and determine its relevance to the case.
Beyond audio - Exploring multimodal searches
Reversing the roles: Any modality can be a "question"
In our Multimodal RAG system, every modality is a potential search query. Let's go beyond the audio example and explore how other data types can initiate investigations.
1. Searching by text (deciphering the criminal’s note)
Scenario: You found an encrypted text message and want to find related evidence.
Expected results:
2. Image search (tracking the suspicious crime scene)
Scenario: A new crime scene (crime_scene2.jpg) needs to be compared with other evidence.
Output:
3. Depth map search (3D pursuit)
Scenario: A depth map (jdancing-depth.png) reveals image escape patterns.
Output

Why does this matter?
Each modality reveals unique connections:
- Text → Linguistic patterns of the suspect.
- Images → Recognition of locations and objects.
- Depth → 3D scene reconstruction.
Now, we have a structured evidence database in Elasticsearch, enabling us to store and retrieve multimodal evidence efficiently.
Summary of what we've done:
- Stored multimodal embeddings in Elasticsearch.
- Performed similarity searches, finding evidence related to new clues.
- Tested the search using a suspicious audio file, ensuring the system works correctly.
Next step: We will use an LLM (Large Language Model) to analyze the retrieved evidence and generate a final report.
Stage 4 - Connecting the dots with the LLM
Now that the evidence has been indexed in Elasticsearch and can be retrieved by similarity, we need a LLM (Large Language Model) to analyze it and generate a final report to send to Commissioner Gordon. The LLM will be responsible for identifying patterns, connecting clues, and suggesting a possible suspect based on the retrieved evidence.
For this task, we will use GPT-4 Turbo, formulating a detailed prompt so that the model can interpret the results efficiently.
LLM integration
To integrate the LLM into our system, we created the LLMAnalyzer class (src/llm_analyzer.py), which receives the retrieved evidence from Elasticsearch and generates a forensic report using this evidence as the prompt context.
Temperature setting in LLM analysis:
For our forensic analysis system, we use a moderate temperature of 0.5. This balanced setting was chosen because:
- It represents a middle ground between deterministic (too rigid) and highly random outputs;
- At 0.5, the model maintains enough structure to provide logical and justifiable forensic conclusions;
- This setting allows the model to identify patterns and make connections while staying within reasonable forensic analysis parameters;
- It balances the need for consistent, reliable outputs with the ability to generate insightful analysis.
This moderate temperature setting helps ensure our forensic analysis is both reliable and insightful, avoiding both overly rigid and overly speculative conclusions.
Running the evidence analysis
Now that we have the LLM integration, we need a script that connects all system components. This script will:
- Search for similar evidence in Elasticsearch.
- Analyze the retrieved evidence using the LLM to generate a final report.
Code: Evidence analysis script
Expected LLM output

Conclusion: Case solved
With all the clues gathered and analyzed, the Multimodal RAG system has identified a suspect: The Joker.
By combining images, audio, text, and depth maps into a shared vector space using ImageBind, the system was able to detect connections that would have been impossible to identify manually. Elasticsearch ensured fast and efficient searches, while the LLM synthesized the evidence into a clear and conclusive report.
However, the true power of this system goes beyond Gotham City. The Multimodal RAG architecture opens doors to numerous real-world applications:
- Urban surveillance: Identifying suspects based on images, audio, and sensor data.
- Forensic analysis: Correlating evidence from multiple sources to solve complex crimes.
- Multimedia recommendation: Creating recommendation systems that understand multimodal contexts (e.g., suggesting music based on images or text).
- Social media trends: Detecting trending topics across different data formats.
Now that you’ve learned how to build a Multimodal RAG system, why not test it with your own clues?
Share your discoveries with us and help the community advance in the field of multimodal AI!
Special thanks
I would like to thank Adrian Cole for his valuable contribution and review during the process of defining the deployment architecture of this code.
References
Frequently Asked Questions
What is a multimodal RAG?
Multimodal RAG is a method that allows AI systems to combine information from different formats (such as images, videos, and audio) for richer and more precise responses.
How to implement multimodal RAG?
To implement a Multimodal RAG, three strategies are commonly used: shared vector space, single grounded modality, and separate retrieval
Related Content
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
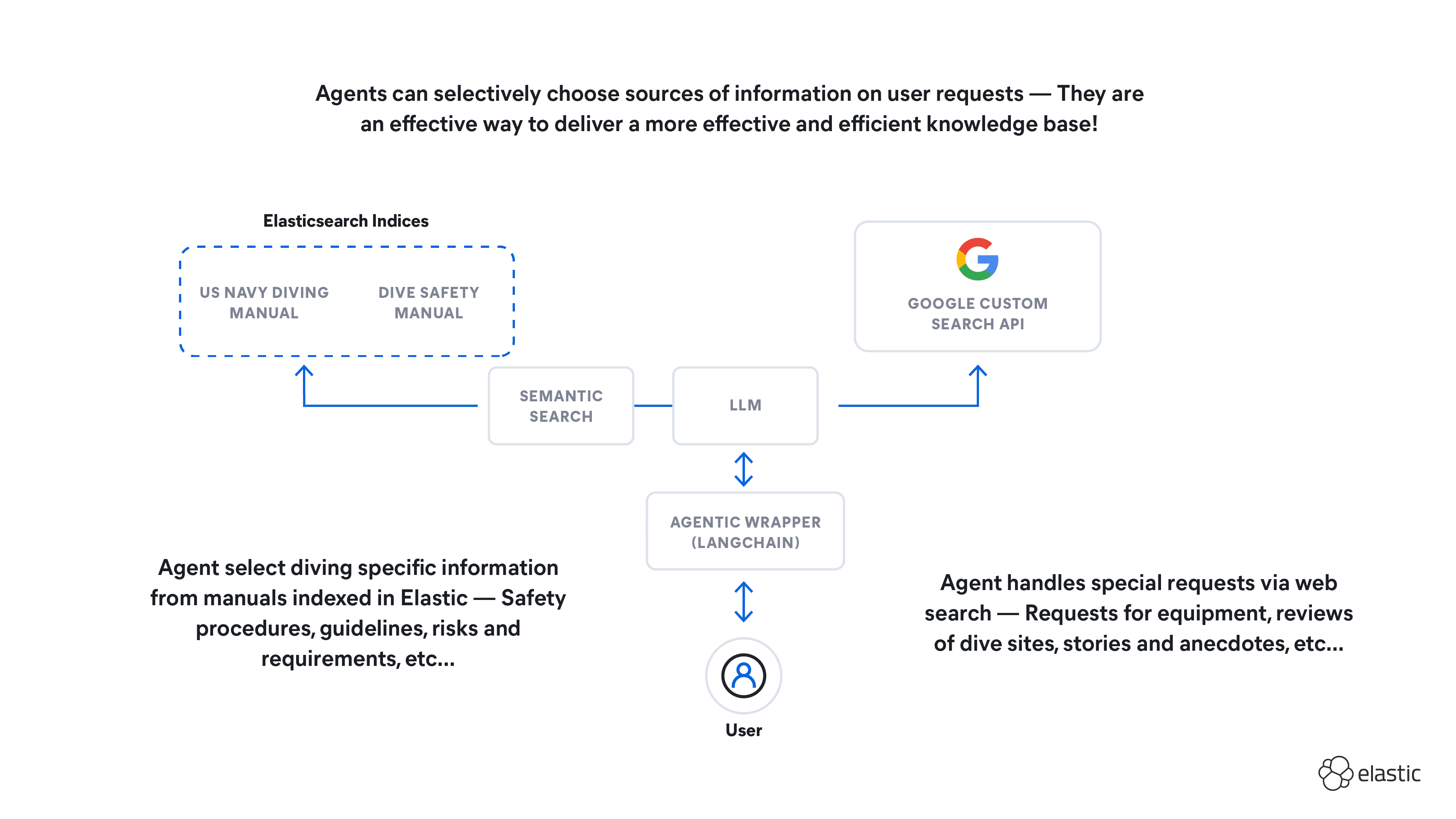
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.

December 29, 2025
Creating reliable agents with structured outputs in Elasticsearch
Explore what structured outputs are and how to leverage them in Elasticsearch to ground agents in the most relevant context for data contracts.
December 15, 2025
Getting started with Elastic Agent Builder and Strands Agents SDK
Learn how to create an agent with Elastic Agent Builder and then explore how to use the agent via the A2A protocol orchestrated with the Strands Agents SDK.

November 25, 2025
Top Elastic Agent Builder projects and learnings from Cal Hacks 12.0
Explore the top Elastic Agent Builder projects from Cal Hacks 12.0 and dive into our technical takeaways on Serverless, ES|QL, and agent architectures.