Elasticsearch allows you to index data quickly and in a flexible manner. Try it free in the cloud or run it locally to see how easy indexing can be.
What is Apache Airflow?
Apache Airflow is a platform designed to create, schedule, and monitor workflows. It is used to orchestrate ETL processes, data pipelines, and other complex workflows, offering flexibility and scalability. Its visual interface and real-time monitoring capabilities make pipeline management more accessible and efficient, allowing you to track the progress and results of your executions. Below are its four main pillars:
- Dynamic: Pipelines are defined in Python, allowing for dynamic and flexible workflow generation.
- Extensible: Airflow can be integrated with a variety of environments, custom operators can be created, and specific code can be executed as needed.
- Elegant: Pipelines are written in a clean and explicit manner.
- Scalable: Its modular architecture uses a message queue to orchestrate an arbitrary number of workers.
In practice, Airflow can be used in scenarios such as:
- Data import: Orchestrate the daily ingestion of data into a database such as Elasticsearch.
- Log monitoring: Manage the collection and processing of log files, which are then analyzed in Elasticsearch to identify errors or anomalies.
- Integration of multiple data sources: Combine information from different systems (APIs, databases, files) into a single layer in Elasticsearch, simplifying search and reporting.
Understanding DAG (Directed Acyclic Graphs) in Airflow
In Airflow, workflows are represented by DAGs (Directed Acyclic Graphs). A DAG is a structure that defines the sequence in which tasks will be executed. The main characteristics of DAGs are:
- Composition by independent tasks: Each task represents a unit of work and is designed to be executed independently.
- Sequencing: The sequence in which tasks are executed is explicitly defined in the DAG.
- Reusability: DAGs are designed to be executed repeatedly, facilitating process automation.
Airflow components
The Airflow ecosystem is composed of several components that work together to orchestrate tasks:
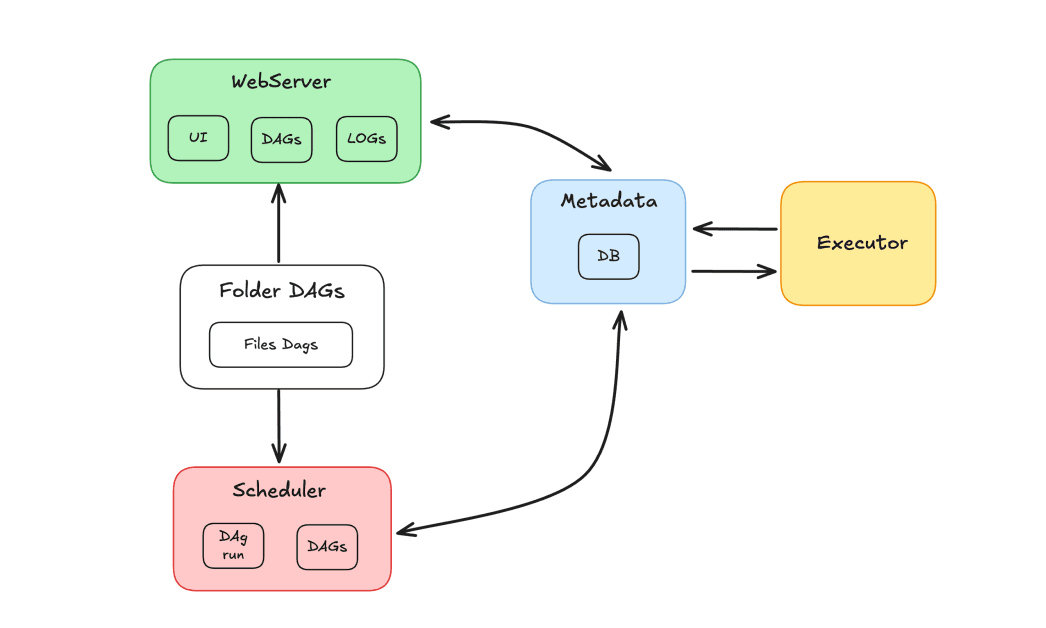
- Scheduler: Responsible for scheduling DAGs and sending tasks for execution by workers.
- Executor: Manages the execution of tasks, delegating them to workers.
- Web Server: Provides a graphical interface for interacting with DAGs and tasks.
- Dags Folder: Folder where we store DAGs written in Python.
- Metadata: Database that serves as a repository for the tool, used by the scheduler and executor to store execution status.
Apache Airflow and Elasticsearch
We will demonstrate the use of Apache Airflow and Elasticsearch to orchestrate tasks and index results in Elasticsearch. The goal of this demonstration is to create a pipeline of tasks to update records in an Elasticsearch index. This index contains a database of movies, where users can rate and assign ratings. Imagining a scenario with hundreds of daily ratings, it is necessary to keep the ratings record updated. To do this, a DAG will be developed that will be executed daily, responsible for retrieving the new consolidated ratings and updating the records in the index.
In the DAG flow, we will have a task to fetch the ratings, followed by a task to validate the results. If the data does not exist, the DAG will be directed to a failure task. Otherwise, the data will be indexed in Elasticsearch. The goal is to update the rating field of movies in an index by retrieving the ratings through a method with the mechanism responsible for calculating the scores.
Using Apache Airflow and Elasticsearch with Docker
To create a containerized environment, we will use Apache Airflow with Docker. Follow the instructions in the "Running Airflow in Docker" guide to set up Airflow practically.
As for Elasticsearch, I will use a cluster on Elastic Cloud, but if you prefer, you can also configure Elasticsearch with Docker. An index has already been created containing a movie catalog, with the movie data indexed. The 'rating' field of these movies will be updated.
Creating the DAG
After installing via Docker, a folder structure will be created, including the dags folder, where we must place our DAG files for Airflow to recognize them.
Before that, we need to ensure the necessary dependencies are installed. Here are the dependencies for this project:
We will create the file update_ratings_movies.py and start coding the tasks.
Now, let's import the necessary libraries:
We will use the ElasticsearchPythonHook, a component that simplifies the integration between Airflow and an Elasticsearch cluster by abstracting the connection and the use of external APIs.
Next, we define the DAG, specifying its main arguments:
dag_id: the name of the DAG.start_date: when the DAG will start.schedule: defines the periodicity (daily in our case).doc_md: documentation that will be imported and displayed in the Airflow interface.
Defining the Tasks
Now, let's define the DAG's tasks. The first task will be responsible for retrieving the movie rating data. We will use the PythonOperator with the task_id set to 'get_movie_ratings'. The python_callable parameter will call the function responsible for fetching the ratings.
Next, we need to validate whether the results are valid. For this, we will use a conditional with a BranchPythonOperator. The task_id will be 'validate_result', and the python_callable will call the validation function. The op_args parameter will be used to pass the result of the previous task, 'get_movie_ratings', to the validation function.
If the validation is successful, we will take the data from the 'get_movie_ratings' task and index it into Elasticsearch. To achieve this, we will create a new task, 'index_movie_ratings', which will use the PythonOperator. The op_args parameter will pass the results of the 'get_movie_ratings' task to the indexing function.
If the validation indicates a failure, the DAG will proceed to a failure notification task. In this example, we simply print a message, but in a real-world scenario, we could configure alerts to notify about the failures.
Finally, we define the task dependencies, ensuring they execute in the correct order:
Now follows the complete code of our DAG:
Visualizing the DAG execution
In the Apache Airflow interface, we can visualize the execution of the DAGs. Simply go to the "DAGs" tab and locate the DAG you created.
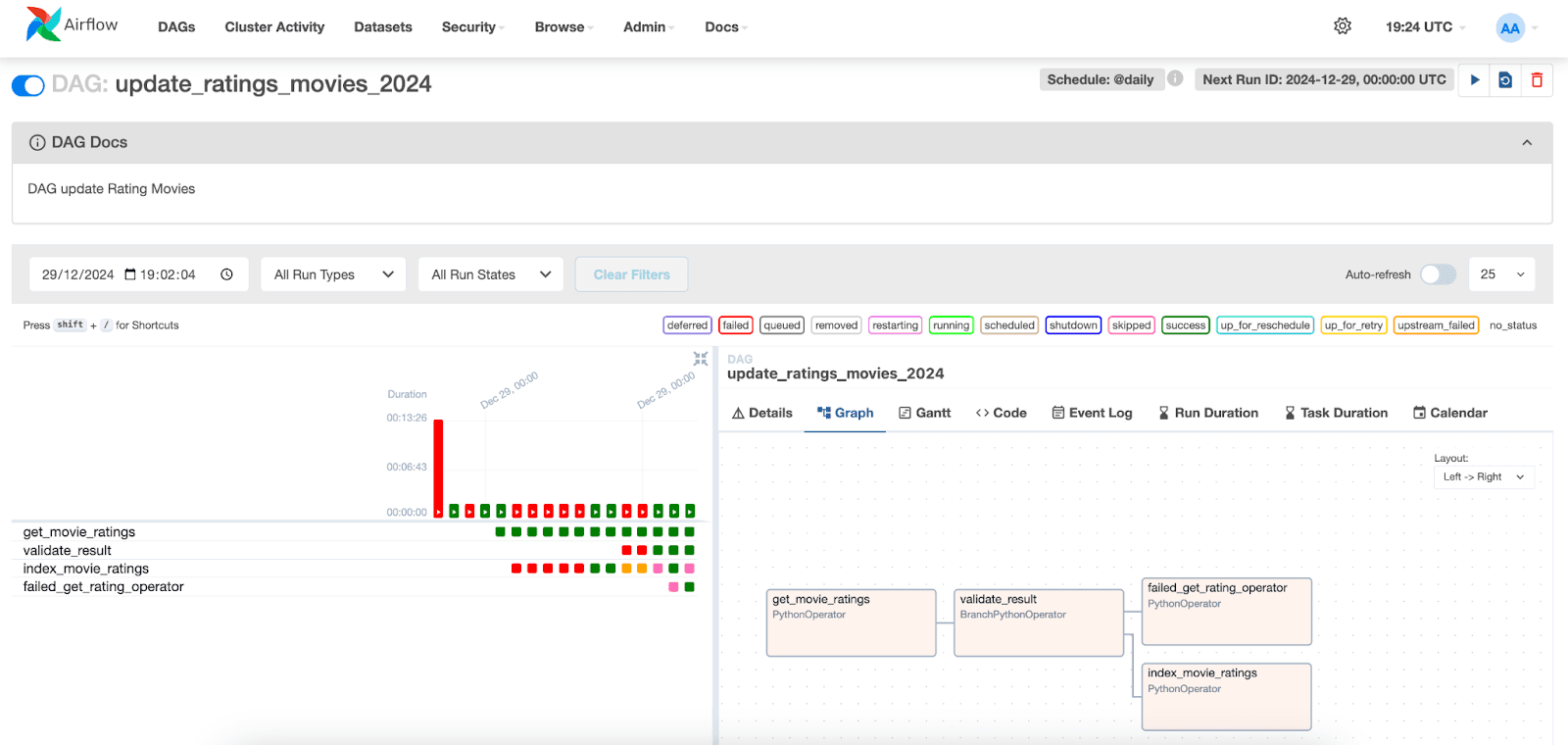
Below, we can visualize the executions of the tasks and their respective statuses. By selecting an execution for a specific date, we can access the logs of each task. Note that in the index_movie_ratings task, we can see the indexing results in the index, and that it was successfully completed.
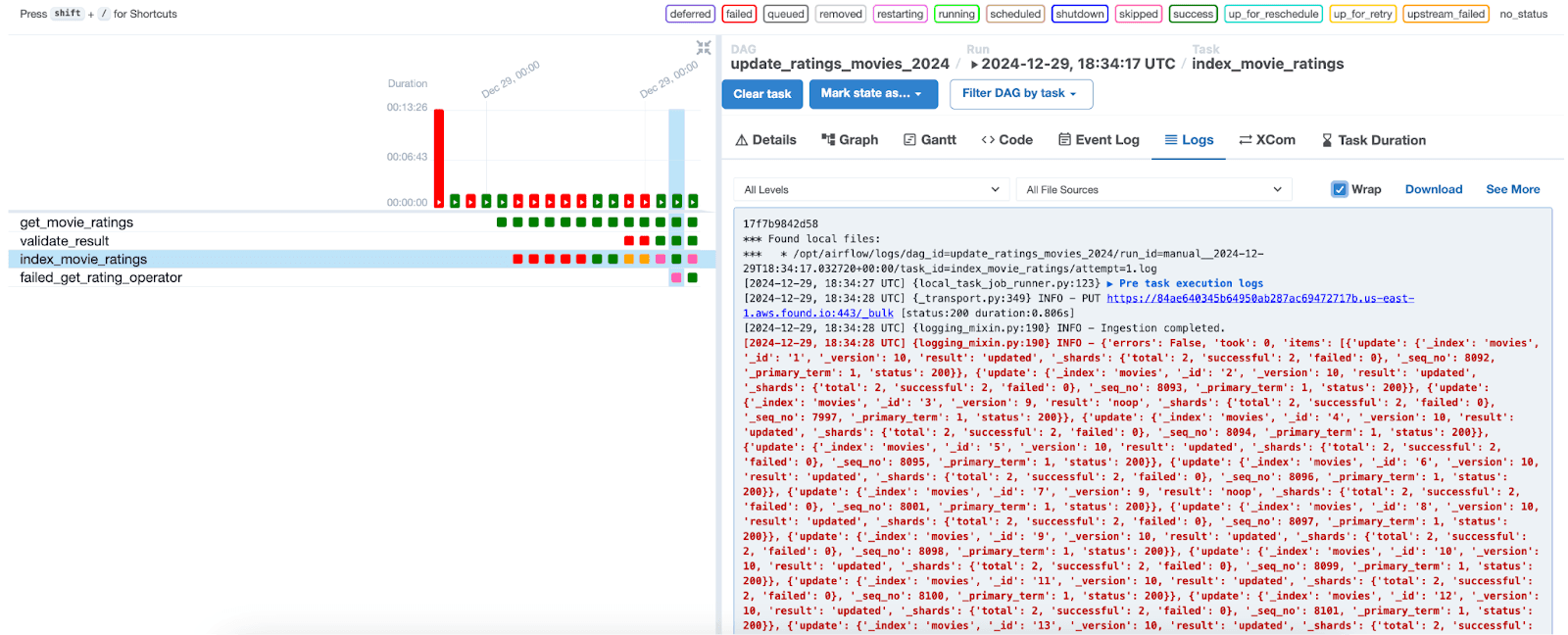
In the other tabs, it is possible to access additional information about the tasks and the DAG, assisting in the analysis and resolution of potential issues.
Conclusion
In this article, we demonstrated how to integrate Apache Airflow with Elasticsearch to create a data ingestion solution. We showed how to configure the DAG, define the tasks responsible for retrieving, validating, and indexing movie data, as well as monitor and visualize the execution of these tasks in the Airflow interface.
This approach can be easily adapted to different types of data and workflows, making Airflow a useful tool for orchestrating data pipelines in various scenarios.
References
Apache AirFlow
Install Apache Airflow with Docker
https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html
Elasticsearch Python Hook
Python Operator
https://airflow.apache.org/docs/apache-airflow/stable/howto/operator/python.html
Frequently Asked Questions
What is Apache Airflow?
Apache Airflow is a platform designed to create, schedule, and monitor workflows.
What is What is Apache Airflow used for?
Apache Airflow is used to orchestrate ETL processes, data pipelines, and other complex workflows, offering flexibility and scalability.
What are the main components of Apache Airflow?
The main components of Airflow are: Scheduler, Executor, Web Server, Dags Folder, and Metadata.
Can Apache Airflow be integrated with Elasticsearch?
Yes, Apache Airflow can be integrated with Elasticsearch, for example you can use Apache Airflow to orchestrate tasks and index results in Elasticsearch.
What is a DAG in Apache Airflow?
In Airflow, workflows are represented by DAGs (Directed Acyclic Graphs). A DAG is a structure that defines the sequence in which tasks will be executed.
Related Content
December 16, 2025
Reducing Elasticsearch frozen tier costs with Deepfreeze S3 Glacier archival
Learn how to leverage Deepfreeze in Elasticsearch to automate searchable snapshot repository rotation, retaining historical data and aging it into lower cost S3 Glacier tiers after index deletion.

September 22, 2025
Elastic Open Web Crawler as a code
Learn how to use GitHub Actions to manage Elastic Open Crawler configurations, so every time we push changes to the repository, the changes are automatically applied to the deployed instance of the crawler.

August 6, 2025
How to display fields of an Elasticsearch index
Learn how to display fields of an Elasticsearch index using the _mapping and _search APIs, sub-fields, synthetic _source, and runtime fields.

July 14, 2025
Run Elastic Open Crawler in Windows with Docker
Learn how to use Docker to get Open Crawler working in a Windows environment.

June 24, 2025
Ruby scripting in Logstash
Learn about the Logstash Ruby filter plugin for advanced data transformation in your Logstash pipeline.