O que é a classificação de texto?
Definição de classificação de texto
A classificação de texto é um tipo de machine learning que categoriza documentos de texto ou frases em classes ou categorias predefinidas. Ela analisa o conteúdo e o significado do texto e, em seguida, atribui a ele o rótulo mais apropriado.
Como exemplos de aplicações reais de classificação de texto, podemos citar a análise de sentimentos (que determina que os sentimentos são positivos ou negativos em avaliações), a detecção de spam (como a identificação de emails indesejados) e a categorização de tópicos (como a organização de artigos de notícias em tópicos relevantes). A classificação de texto desempenha um papel importante no processamento de linguagem natural (PLN), permitindo que os computadores entendam e organizem grandes quantidades de texto não estruturado. Isso simplifica tarefas como filtragem de conteúdo, sistemas de recomendação e análise de feedback do cliente.
Tipos de classificação de texto
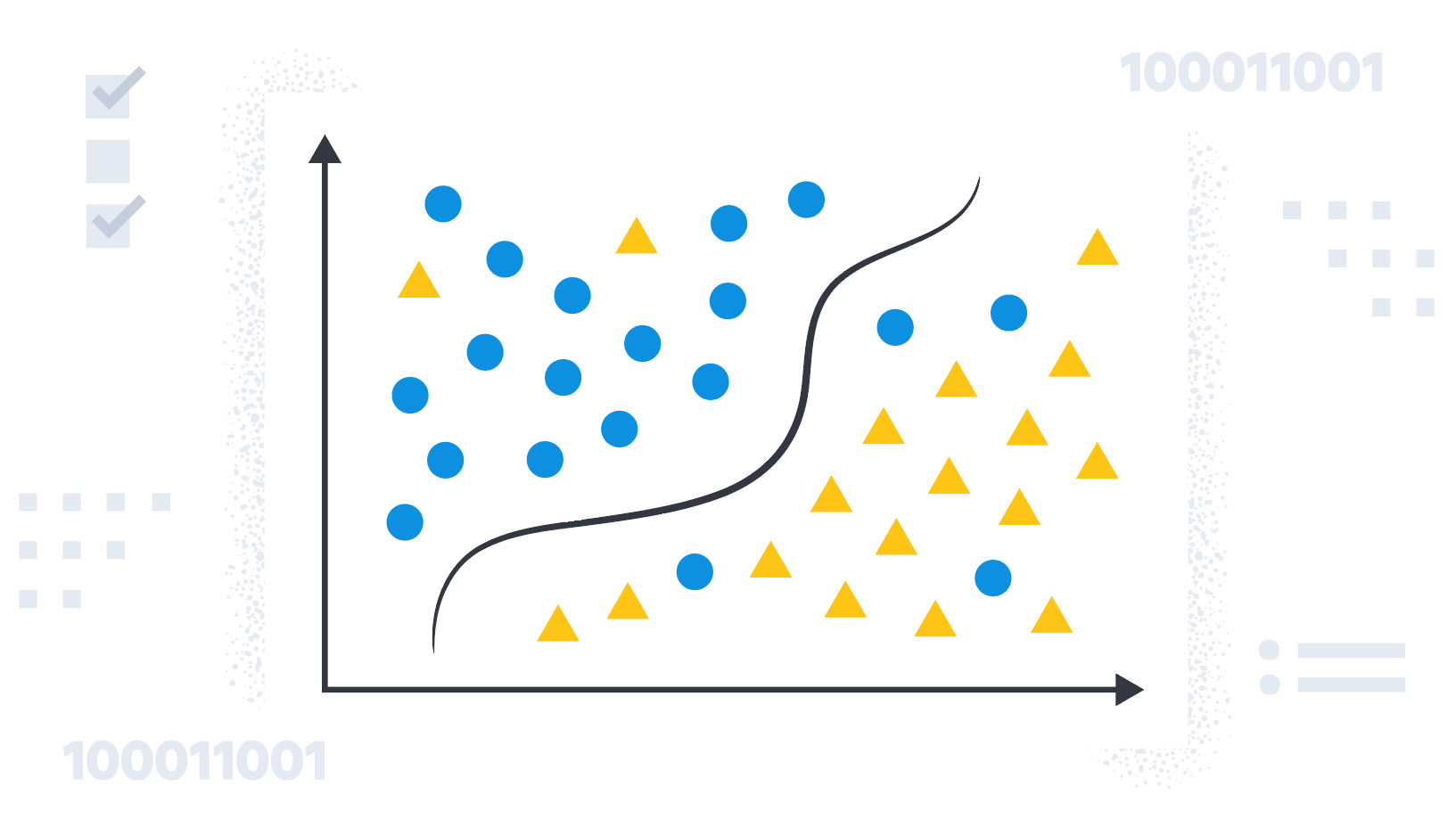
Estes são alguns dos tipos de classificação de texto que você pode encontrar:
A análise de sentimentos do texto determina o sentimento ou a emoção expressos em um texto, geralmente categorizando-o como positivo, negativo ou neutro. É usada para analisar avaliações de produtos, publicações em redes sociais e feedback de clientes.
A detecção de toxicidade, relacionada à análise de sentimentos do texto, identifica linguagem ofensiva ou prejudicial online. Ela ajuda os moderadores de comunidades online a manter um ambiente digital respeitoso em discussões, comentários ou publicações em redes sociais.
O reconhecimento de intenção é outro subconjunto da análise de sentimentos do texto usado para entender o propósito (ou intenção) por trás da entrada de texto de um usuário. Chatbots e assistentes virtuais costumam usar o reconhecimento de intenção para responder às consultas dos usuários.
A classificação binária categoriza o texto em uma de duas classes ou categorias. Um exemplo comum é a detecção de spam, que classifica textos (emails ou mensagens) como spam ou categorias legítimas para filtrar automaticamente conteúdo não solicitado e potencialmente prejudicial.
A classificação multiclasse categoriza o texto em três ou mais classes ou categorias distintas. Isso torna mais fácil organizar e recuperar informações de conteúdos como artigos de notícias, posts de blogs ou trabalhos de pesquisa.
A categorização de tópicos, relacionada à classificação multiclasse, agrupa documentos ou artigos em tópicos ou temas predefinidos. Por exemplo, artigos de notícias podem ser categorizados em tópicos como política, esportes e entretenimento.
A identificação do idioma determina o idioma no qual um texto está escrito. Isso é útil em contextos multilíngues e aplicações baseadas em idiomas.
O reconhecimento de entidades nomeadas concentra-se na identificação e classificação de entidades nomeadas em um texto, como nomes de pessoas, organizações, locais e datas.
A classificação de perguntas trata da categorização de perguntas com base no tipo de resposta esperado, o que pode ser útil para mecanismos de busca e sistemas de resposta a perguntas.
O processo de classificação de texto
O processo de classificação de texto envolve diversas etapas, desde a coleta de dados até a implantação do modelo. Aqui está uma rápida visão geral de como ele funciona:
Etapa 1: coleta de dados
Colete um conjunto de documentos de texto com suas categorias correspondentes para o processo de rotulagem de texto.
Etapa 2: pré-processamento dos dados
Limpe e prepare os dados de texto removendo símbolos desnecessários, convertendo em letras minúsculas e manipulando caracteres especiais, como pontuação.
Etapa 3: tokenização
Divida o texto em tokens, que são pequenas unidades como palavras. Os tokens ajudam a encontrar correspondências e conexões criando partes buscáveis individualmente. Essa etapa é especialmente útil para a busca vetorial e a busca semântica, que fornecem resultados com base na intenção do usuário.
Etapa 4: extração de recursos
Converta o texto em representações numéricas que os modelos de machine learning possam compreender. Alguns métodos comuns incluem contar as ocorrências de palavras (também conhecido como Bag-of-Words) ou usar embeddings de palavras para capturar o significado delas.
Etapa 5: treinamento de modelo
Agora que os dados estão limpos e pré-processados, você pode usá-los para treinar um modelo de machine learning. O modelo aprenderá padrões e associações entre as características do texto e suas categorias. Isso o ajuda a compreender as convenções de rotulagem de texto usando os exemplos pré-rotulados.
Etapa 6: rotulagem de texto
Crie um conjunto de dados novo e separado para iniciar a rotulagem e a classificação de um texto novo. No processo de rotulagem de texto, o modelo separa o texto em categorias pré-determinadas na etapa de coleta de dados.
Etapa 7: avaliação do modelo
Observe atentamente o desempenho do modelo treinado no processo de rotulagem de texto para ver como ele consegue classificar o texto não visto.
Etapa 8: ajuste de hiperparâmetros
Dependendo de como for a avaliação do modelo, talvez você queira ajustar as configurações do modelo para otimizar seu desempenho.
Etapa 9: implantação do modelo
Use o modelo treinado e ajustado para classificar novos dados de texto em suas categorias apropriadas.
Por que a classificação de texto é importante?
A classificação de texto é importante porque permite que os computadores categorizem e compreendam automaticamente grandes volumes de dados de texto. Em nosso mundo digital, encontramos quantidades gigantescas de informações textuais o tempo todo. São emails, redes sociais, avaliações e muito mais. A classificação de texto permite que as máquinas organizem esses dados não estruturados em grupos significativos usando rotulagem de texto. Ao dar sentido ao conteúdo impenetrável, a classificação de texto melhora a eficiência, facilita a tomada de decisões e melhora a experiência do usuário.
Casos de uso de classificação de texto
Os casos de uso de classificação de texto abrangem uma variedade de ambientes profissionais. Aqui estão alguns casos de uso do mundo real que você pode encontrar:
- Automatizar e categorizar tíquetes de suporte ao cliente, priorizando-os e encaminhando-os para as equipes certas para resolução.
- Analisar feedback de clientes, respostas de pesquisas e discussões online para identificar tendências de mercado e preferências do consumidor.
- Acompanhar menções em redes sociais e avaliações online para monitorar a reputação da sua marca e o sentimento.
- Organizar e marcar conteúdo em sites e plataformas de e-commerce usando rotulagem de texto ou tags para facilitar a descoberta do conteúdo, o que melhora a experiência dos seus clientes.
- Identificar possíveis leads de vendas em redes sociais e outras fontes online com base em palavras-chave e critérios específicos.
- Analisar as avaliações e feedback do seu concorrente para obter insights sobre seus pontos fortes e fracos.
- Segmentar seus clientes com base em suas interações e feedback usando rotulagem de texto para adaptar estratégias e campanhas de marketing a eles.
- Detectar atividades e transações fraudulentas nos seus sistemas financeiros com base em padrões e anomalias de rotulagem de texto (também conhecido como detecção de anomalia).
Técnicas e algoritmos para classificação de texto
Aqui estão algumas técnicas e algoritmos usados para classificação de texto:
- Bag-of-Words (BoW) é uma técnica simples que conta ocorrências de palavras sem considerar sua ordem.
- Os embeddings de palavras utilizam diversas técnicas que convertem palavras em representações numéricas organizadas em um espaço multidimensional, capturando assim as complexas relações entre as palavras.
- As árvores de decisão são algoritmos de machine learning que criam uma estrutura semelhante a uma árvore com nós e folhas de decisão. Cada nó testa a presença de uma palavra, o que ajuda a árvore a aprender padrões nos dados de texto.
- A floresta aleatória é um método que combina várias árvores de decisão para melhorar a acurácia na classificação de texto.
- O BERT (Bidirectional Encoder Representations from Transformers) é um sofisticado modelo de classificação baseado em transformador que consegue compreender o contexto das palavras.
- O Naive Bayes calcula a probabilidade de um determinado documento pertencer a uma classe específica com base na ocorrência de palavras no documento. Ele estima a probabilidade de cada palavra aparecer em cada classe e combina essas probabilidades usando o teorema de Bayes (um teorema fundamental na teoria das probabilidades) para fazer previsões.
- O SVM (Support Vector Machine) é um algoritmo de machine learning usado para tarefas de classificação binária e multiclasse. O SVM procura o hiperplano que melhor separa os pontos de dados de diferentes classes em um espaço de características de alta dimensão. Isso ajuda a fazer previsões precisas sobre dados de texto novos e não vistos.
- O TF-IDF (Term Frequency-Inverse Document Frequency) é um método que mede a importância das palavras em um documento em comparação com o conjunto de dados inteiro.
Métricas de avaliação na classificação de texto
As métricas de avaliação na classificação de texto são usadas para medir o desempenho do modelo de diferentes maneiras. Estas são algumas métricas de avaliação comuns:
Acurácia
A proporção de amostras de texto classificadas corretamente em relação ao total de amostras. Ela fornece uma medida geral da correção do modelo.
Precisão
A proporção de amostras positivas previstas corretamente em relação a todas as amostras positivas previstas. Indica quantas das instâncias positivas previstas estavam realmente corretas.
Recall (ou sensibilidade)
A proporção de amostras positivas previstas corretamente em relação a todas as amostras positivas reais. Ele mede como o modelo identifica instâncias positivas.
Pontuação F1
Uma medida equilibrada que combina precisão e recall, proporcionando uma avaliação geral do desempenho do modelo quando ele encontra classes desequilibradas.
Área sob a curva característica de operação do receptor (AUC-ROC)
Uma representação gráfica da capacidade do modelo de distinguir entre diferentes classes. É especialmente útil na classificação binária.
Matriz de confusão
Uma tabela que mostra o número de verdadeiros positivos, verdadeiros negativos, falsos positivos e falsos negativos. Fornece uma análise detalhada do desempenho do seu modelo.
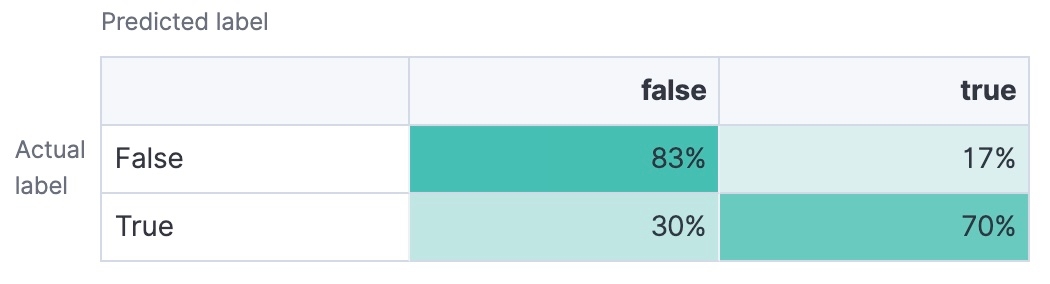
No final, seu objetivo deve ser escolher um modelo de classificação de texto com alta acurácia, precisão, recall e pontuação F1, dependendo das suas necessidades específicas. O AUC-ROC e a matriz de confusão também podem oferecer insights úteis sobre a capacidade do seu modelo de lidar com diferentes limites de classificação e fornecer uma melhor compreensão do seu desempenho.
Tendências futuras na classificação de texto
As tendências futuras na classificação de texto vão desde IA aberta até ferramentas específicas do setor. Conforme a tecnologia de machine learning for se expandindo, aumentarão também as funcionalidades de classificação de texto. Por exemplo, à medida que as ferramentas e a tecnologia de ponta se tornam mais acessíveis, também precisam se tornar mais diversificadas. Em breve veremos a classificação de texto multilíngue surgir para dar suporte à crescente necessidade de suporte multilíngue em aplicações globais, analisando de forma eficaz vários idiomas no mesmo conjunto de dados. A classificação de texto específica do domínio também deverá decolar à medida que os modelos forem treinados para fornecer classificações mais específicas e, portanto, mais precisas, adaptadas a setores como jurídico, médico ou financeiro.
É claro que as tendências de classificação de texto contribuirão para as novas funcionalidades de IA. Conforme as aplicações de IA se tornam mais predominantes, há uma necessidade crescente de modelos de classificação de texto transparentes e interpretáveis. A IA explicável envolve a incorporação de métodos de explicabilidade para entender o raciocínio por trás das previsões do modelo.
Os modelos de aprendizado profundo — como CNNs (redes neurais convolucionais) e RNNs (redes neurais recorrentes) — e os modelos híbridos são arquiteturas de redes neurais que estão sendo aplicadas à classificação de texto. As CNNs são usadas principalmente para tarefas de processamento de imagens, e as RNNs são projetadas para lidar com dados sequenciais, mas ambas demonstraram a capacidade de compreender padrões de texto com sucesso. Os modelos híbridos combinam múltiplas arquiteturas (como CNNs, RNNs e modelos baseados em transformadores como o BERT) para aproveitar os pontos fortes das diferentes abordagens para uma melhor classificação de texto.
Pesquisas futuras também podem explorar técnicas que permitem que modelos de classificação de texto aprendam com menos exemplos rotulados (aprendizado com poucos disparos) ou até mesmo realizar classificação de texto em classes não vistas durante o treinamento (aprendizado zero-shot). Ambos têm o potencial de reduzir significativamente a dependência de grandes conjuntos de dados rotulados, tornando a classificação de texto mais escalável e adaptável a novas tarefas.
Classificação de texto com a Elastic
A classificação de texto é um dos muitos recursos de processamento de linguagem natural que você encontrará nas soluções do Elastic Search. Com o Elasticsearch, você pode classificar seu texto não estruturado, extrair informações dele e aplicá-lo às necessidades dos seus negócios de forma rápida e fácil.
Quer você precise dela para busca, observabilidade ou segurança, a Elastic possibilita que você aproveite a classificação de texto para extrair e organizar informações com mais eficiência para seus negócios.