Data processing with DISSECT and GROK
editData processing with DISSECT and GROK
editYour data may contain unstructured strings that you want to structure. This makes it easier to analyze the data. For example, log messages may contain IP addresses that you want to extract so you can find the most active IP addresses.
Elasticsearch can structure your data at index time or query time. At index time, you can
use the Dissect and Grok ingest
processors, or the Logstash Dissect and
Grok filters. At query time, you can
use the ES|QL DISSECT and GROK commands.
DISSECT or GROK? Or both?
editDISSECT works by breaking up a string using a delimiter-based pattern. GROK
works similarly, but uses regular expressions. This makes GROK more powerful,
but generally also slower. DISSECT works well when data is reliably repeated.
GROK is a better choice when you really need the power of regular expressions,
for example when the structure of your text varies from row to row.
You can use both DISSECT and GROK for hybrid use cases. For example when a
section of the line is reliably repeated, but the entire line is not. DISSECT
can deconstruct the section of the line that is repeated. GROK can process the
remaining field values using regular expressions.
Process data with DISSECT
editThe DISSECT processing command matches a string against a
delimiter-based pattern, and extracts the specified keys as columns.
For example, the following pattern:
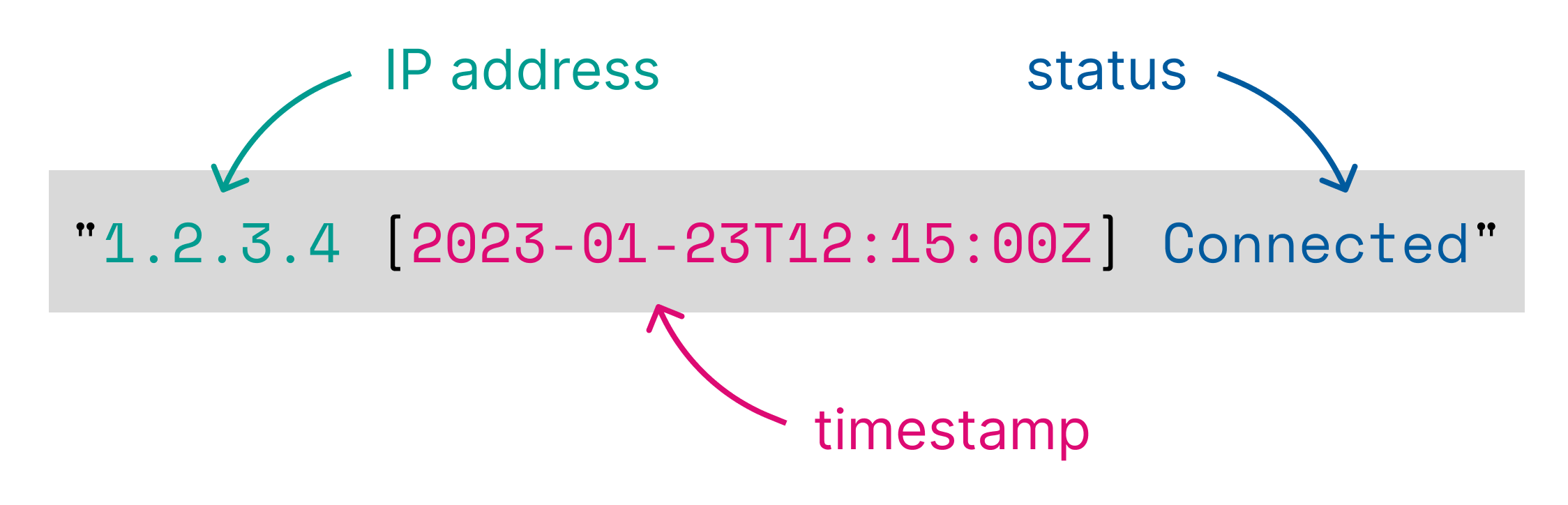
%{clientip} [%{@timestamp}] %{status}
matches a log line of this format:
1.2.3.4 [2023-01-23T12:15:00.000Z] Connected
and results in adding the following columns to the input table:
| clientip:keyword | @timestamp:keyword | status:keyword |
|---|---|---|
1.2.3.4 |
2023-01-23T12:15:00.000Z |
Connected |
Dissect patterns
editA dissect pattern is defined by the parts of the string that will be discarded. In the previous example, the first part
to be discarded is a single space. Dissect finds this space, then assigns the value of clientip everything up
until that space.
Next, dissect matches the [ and then ] and then assigns @timestamp to everything in-between [ and ].
Paying special attention to the parts of the string to discard will help build successful dissect patterns.
An empty key (%{}) or named skip key can be used to
match values, but exclude the value from the output.
All matched values are output as keyword string data types. Use the Type conversion functions to convert to another data type.
Dissect also supports key modifiers that can change dissect’s default behavior. For example, you can instruct dissect to ignore certain fields, append fields, skip over padding, etc.
Terminology
edit- dissect pattern
-
the set of fields and delimiters describing the textual
format. Also known as a dissection.
The dissection is described using a set of
%{}sections:%{a} - %{b} - %{c} - field
-
the text from
%{to}inclusive. - delimiter
-
the text between
}and the next%{characters. Any set of characters other than%{,'not }', or}is a delimiter. - key
-
the text between the
%{and}, exclusive of the?,+,&prefixes and the ordinal suffix.Examples:
-
%{?aaa}- the key isaaa -
%{+bbb/3}- the key isbbb -
%{&ccc}- the key isccc
-
Examples
editThe following example parses a string that contains a timestamp, some text, and an IP address:
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a """%{date} - %{msg} - %{ip}"""
| KEEP date, msg, ip
| date:keyword | msg:keyword | ip:keyword |
|---|---|---|
2023-01-23T12:15:00.000Z |
some text |
127.0.0.1 |
By default, DISSECT outputs keyword string columns. To convert to another
type, use Type conversion functions:
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a """%{date} - %{msg} - %{ip}"""
| KEEP date, msg, ip
| EVAL date = TO_DATETIME(date)
| msg:keyword | ip:keyword | date:date |
|---|---|---|
some text |
127.0.0.1 |
2023-01-23T12:15:00.000Z |
Dissect key modifiers
editKey modifiers can change the default behavior for dissection. Key modifiers may be found on the left or right
of the %{keyname} always inside the %{ and }. For example %{+keyname ->} has the append and right padding
modifiers.
Table 51. Dissect key modifiers
| Modifier | Name | Position | Example | Description | Details |
|---|---|---|---|---|---|
|
Skip right padding |
(far) right |
|
Skips any repeated characters to the right |
|
|
Append |
left |
|
Appends two or more fields together |
|
|
Append with order |
left and right |
|
Appends two or more fields together in the order specified |
|
|
Named skip key |
left |
|
Skips the matched value in the output. Same behavior as |
Right padding modifier (->)
editThe algorithm that performs the dissection is very strict in that it requires all characters in the pattern to match
the source string. For example, the pattern %{fookey} %{barkey} (1 space), will match the string "foo bar"
(1 space), but will not match the string "foo bar" (2 spaces) since the pattern has only 1 space and the
source string has 2 spaces.
The right padding modifier helps with this case. Adding the right padding modifier to the pattern %{fookey->} %{barkey},
It will now will match "foo bar" (1 space) and "foo bar" (2 spaces)
and even "foo bar" (10 spaces).
Use the right padding modifier to allow for repetition of the characters after a %{keyname->}.
The right padding modifier may be placed on any key with any other modifiers. It should always be the furthest right
modifier. For example: %{+keyname/1->} and %{->}
For example:
ROW message="1998-08-10T17:15:42 WARN"
| DISSECT message """%{ts->} %{level}"""
| message:keyword | ts:keyword | level:keyword |
|---|---|---|
1998-08-10T17:15:42 WARN |
1998-08-10T17:15:42 |
WARN |
The right padding modifier may be used with an empty key to help skip unwanted data. For example, the same input string, but wrapped with brackets requires the use of an empty right padded key to achieve the same result.
For example:
ROW message="[1998-08-10T17:15:42] [WARN]"
| DISSECT message """[%{ts}]%{->}[%{level}]"""
| message:keyword | ts:keyword | level:keyword |
|---|---|---|
["[1998-08-10T17:15:42] [WARN]"] |
1998-08-10T17:15:42 |
WARN |
Append modifier (+)
editDissect supports appending two or more results together for the output. Values are appended left to right. An append separator can be specified. In this example the append_separator is defined as a space.
ROW message="john jacob jingleheimer schmidt"
| DISSECT message """%{+name} %{+name} %{+name} %{+name}""" APPEND_SEPARATOR=" "
| message:keyword | name:keyword |
|---|---|
john jacob jingleheimer schmidt |
john jacob jingleheimer schmidt |
Append with order modifier (+ and /n)
editDissect supports appending two or more results together for the output.
Values are appended based on the order defined (/n). An append separator can be specified.
In this example the append_separator is defined as a comma.
ROW message="john jacob jingleheimer schmidt"
| DISSECT message """%{+name/2} %{+name/4} %{+name/3} %{+name/1}""" APPEND_SEPARATOR=","
| message:keyword | name:keyword |
|---|---|
john jacob jingleheimer schmidt |
schmidt,john,jingleheimer,jacob |
Named skip key (?)
editDissect supports ignoring matches in the final result. This can be done with an empty key %{}, but for readability
it may be desired to give that empty key a name.
This can be done with a named skip key using the {?name} syntax. In the
following query, ident and auth are not added to the output table:
ROW message="1.2.3.4 - - 30/Apr/1998:22:00:52 +0000"
| DISSECT message """%{clientip} %{?ident} %{?auth} %{@timestamp}"""
| message:keyword | clientip:keyword | @timestamp:keyword |
|---|---|---|
1.2.3.4 - - 30/Apr/1998:22:00:52 +0000 |
1.2.3.4 |
30/Apr/1998:22:00:52 +0000 |
Limitations
editThe DISSECT command does not support reference keys.
Process data with GROK
editThe GROK processing command matches a string against a pattern based on
regular expressions, and extracts the specified keys as columns.
For example, the following pattern:
%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}
matches a log line of this format:
1.2.3.4 [2023-01-23T12:15:00.000Z] Connected
Putting it together as an ES|QL query:
ROW a = "1.2.3.4 [2023-01-23T12:15:00.000Z] Connected"
| GROK a """%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}"""
GROK adds the following columns to the input table:
| @timestamp:keyword | ip:keyword | status:keyword |
|---|---|---|
2023-01-23T12:15:00.000Z |
1.2.3.4 |
Connected |
Special regex characters in grok patterns, like [ and ] need to be escaped
with a \. For example, in the earlier pattern:
%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}
In ES|QL queries, when using single quotes for strings, the backslash character itself is a special character that
needs to be escaped with another \. For this example, the corresponding ES|QL
query becomes:
ROW a = "1.2.3.4 [2023-01-23T12:15:00.000Z] Connected"
| GROK a "%{IP:ip} \\[%{TIMESTAMP_ISO8601:@timestamp}\\] %{GREEDYDATA:status}"
For this reason, in general it is more convenient to use triple quotes """ for GROK patterns,
that do not require escaping for backslash.
ROW a = "1.2.3.4 [2023-01-23T12:15:00.000Z] Connected"
| GROK a """%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}"""
Grok patterns
editThe syntax for a grok pattern is %{SYNTAX:SEMANTIC}
The SYNTAX is the name of the pattern that matches your text. For example,
3.44 is matched by the NUMBER pattern and 55.3.244.1 is matched by the
IP pattern. The syntax is how you match.
The SEMANTIC is the identifier you give to the piece of text being matched.
For example, 3.44 could be the duration of an event, so you could call it
simply duration. Further, a string 55.3.244.1 might identify the client
making a request.
By default, matched values are output as keyword string data types. To convert a
semantic’s data type, suffix it with the target data type. For example
%{NUMBER:num:int}, which converts the num semantic from a string to an
integer. Currently the only supported conversions are int and float. For
other types, use the Type conversion functions.
For an overview of the available patterns, refer to GitHub. You can also retrieve a list of all patterns using a REST API.
Regular expressions
editGrok is based on regular expressions. Any regular expressions are valid in grok as well. Grok uses the Oniguruma regular expression library. Refer to the Oniguruma GitHub repository for the full supported regexp syntax.
Custom patterns
editIf grok doesn’t have a pattern you need, you can use the Oniguruma syntax for named capture which lets you match a piece of text and save it as a column:
(?<field_name>the pattern here)
For example, postfix logs have a queue id that is a 10 or 11-character
hexadecimal value. This can be captured to a column named queue_id with:
(?<queue_id>[0-9A-F]{10,11})
Examples
editThe following example parses a string that contains a timestamp, an IP address, an email address, and a number:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 [email protected] 42" | GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num}""" | KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:keyword |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
By default, GROK outputs keyword string columns. int and float types can
be converted by appending :type to the semantics in the pattern. For example
{NUMBER:num:int}:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 [email protected] 42" | GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}""" | KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:integer |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
For other type conversions, use Type conversion functions:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 [email protected] 42" | GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}""" | KEEP date, ip, email, num | EVAL date = TO_DATETIME(date)
| ip:keyword | email:keyword | num:integer | date:date |
|---|---|---|---|
127.0.0.1 |
42 |
2023-01-23T12:15:00.000Z |
If a field name is used more than once, GROK creates a multi-valued
column:
FROM addresses
| KEEP city.name, zip_code
| GROK zip_code """%{WORD:zip_parts} %{WORD:zip_parts}"""
| city.name:keyword | zip_code:keyword | zip_parts:keyword |
|---|---|---|
Amsterdam |
1016 ED |
["1016", "ED"] |
San Francisco |
CA 94108 |
["CA", "94108"] |
Tokyo |
100-7014 |
null |
Grok debugger
editTo write and debug grok patterns, you can use the
Grok Debugger. It provides a UI for
testing patterns against sample data. Under the covers, it uses the same engine
as the GROK command.
Limitations
editThe GROK command does not support configuring custom
patterns, or multiple patterns. The GROK command is not
subject to Grok watchdog settings.