Getting started with ES|QL queries
editGetting started with ES|QL queries
editThis guide shows how you can use ES|QL to query and aggregate your data.
This getting started is also available as an interactive Python notebook in the elasticsearch-labs GitHub repository.
Prerequisites
editTo follow along with the queries in this guide, you can either set up your own deployment, or use Elastic’s public ES|QL demo environment.
First ingest some sample data. In Kibana, open the main menu and select Dev Tools. Run the following two requests:
resp = client.indices.create(
index="sample_data",
mappings={
"properties": {
"client_ip": {
"type": "ip"
},
"message": {
"type": "keyword"
}
}
},
)
print(resp)
resp1 = client.bulk(
index="sample_data",
operations=[
{
"index": {}
},
{
"@timestamp": "2023-10-23T12:15:03.360Z",
"client_ip": "172.21.2.162",
"message": "Connected to 10.1.0.3",
"event_duration": 3450233
},
{
"index": {}
},
{
"@timestamp": "2023-10-23T12:27:28.948Z",
"client_ip": "172.21.2.113",
"message": "Connected to 10.1.0.2",
"event_duration": 2764889
},
{
"index": {}
},
{
"@timestamp": "2023-10-23T13:33:34.937Z",
"client_ip": "172.21.0.5",
"message": "Disconnected",
"event_duration": 1232382
},
{
"index": {}
},
{
"@timestamp": "2023-10-23T13:51:54.732Z",
"client_ip": "172.21.3.15",
"message": "Connection error",
"event_duration": 725448
},
{
"index": {}
},
{
"@timestamp": "2023-10-23T13:52:55.015Z",
"client_ip": "172.21.3.15",
"message": "Connection error",
"event_duration": 8268153
},
{
"index": {}
},
{
"@timestamp": "2023-10-23T13:53:55.832Z",
"client_ip": "172.21.3.15",
"message": "Connection error",
"event_duration": 5033755
},
{
"index": {}
},
{
"@timestamp": "2023-10-23T13:55:01.543Z",
"client_ip": "172.21.3.15",
"message": "Connected to 10.1.0.1",
"event_duration": 1756467
}
],
)
print(resp1)
response = client.indices.create(
index: 'sample_data',
body: {
mappings: {
properties: {
client_ip: {
type: 'ip'
},
message: {
type: 'keyword'
}
}
}
}
)
puts response
response = client.bulk(
index: 'sample_data',
body: [
{
index: {}
},
{
"@timestamp": '2023-10-23T12:15:03.360Z',
client_ip: '172.21.2.162',
message: 'Connected to 10.1.0.3',
event_duration: 3_450_233
},
{
index: {}
},
{
"@timestamp": '2023-10-23T12:27:28.948Z',
client_ip: '172.21.2.113',
message: 'Connected to 10.1.0.2',
event_duration: 2_764_889
},
{
index: {}
},
{
"@timestamp": '2023-10-23T13:33:34.937Z',
client_ip: '172.21.0.5',
message: 'Disconnected',
event_duration: 1_232_382
},
{
index: {}
},
{
"@timestamp": '2023-10-23T13:51:54.732Z',
client_ip: '172.21.3.15',
message: 'Connection error',
event_duration: 725_448
},
{
index: {}
},
{
"@timestamp": '2023-10-23T13:52:55.015Z',
client_ip: '172.21.3.15',
message: 'Connection error',
event_duration: 8_268_153
},
{
index: {}
},
{
"@timestamp": '2023-10-23T13:53:55.832Z',
client_ip: '172.21.3.15',
message: 'Connection error',
event_duration: 5_033_755
},
{
index: {}
},
{
"@timestamp": '2023-10-23T13:55:01.543Z',
client_ip: '172.21.3.15',
message: 'Connected to 10.1.0.1',
event_duration: 1_756_467
}
]
)
puts response
const response = await client.indices.create({
index: "sample_data",
mappings: {
properties: {
client_ip: {
type: "ip",
},
message: {
type: "keyword",
},
},
},
});
console.log(response);
const response1 = await client.bulk({
index: "sample_data",
operations: [
{
index: {},
},
{
"@timestamp": "2023-10-23T12:15:03.360Z",
client_ip: "172.21.2.162",
message: "Connected to 10.1.0.3",
event_duration: 3450233,
},
{
index: {},
},
{
"@timestamp": "2023-10-23T12:27:28.948Z",
client_ip: "172.21.2.113",
message: "Connected to 10.1.0.2",
event_duration: 2764889,
},
{
index: {},
},
{
"@timestamp": "2023-10-23T13:33:34.937Z",
client_ip: "172.21.0.5",
message: "Disconnected",
event_duration: 1232382,
},
{
index: {},
},
{
"@timestamp": "2023-10-23T13:51:54.732Z",
client_ip: "172.21.3.15",
message: "Connection error",
event_duration: 725448,
},
{
index: {},
},
{
"@timestamp": "2023-10-23T13:52:55.015Z",
client_ip: "172.21.3.15",
message: "Connection error",
event_duration: 8268153,
},
{
index: {},
},
{
"@timestamp": "2023-10-23T13:53:55.832Z",
client_ip: "172.21.3.15",
message: "Connection error",
event_duration: 5033755,
},
{
index: {},
},
{
"@timestamp": "2023-10-23T13:55:01.543Z",
client_ip: "172.21.3.15",
message: "Connected to 10.1.0.1",
event_duration: 1756467,
},
],
});
console.log(response1);
PUT sample_data
{
"mappings": {
"properties": {
"client_ip": {
"type": "ip"
},
"message": {
"type": "keyword"
}
}
}
}
PUT sample_data/_bulk
{"index": {}}
{"@timestamp": "2023-10-23T12:15:03.360Z", "client_ip": "172.21.2.162", "message": "Connected to 10.1.0.3", "event_duration": 3450233}
{"index": {}}
{"@timestamp": "2023-10-23T12:27:28.948Z", "client_ip": "172.21.2.113", "message": "Connected to 10.1.0.2", "event_duration": 2764889}
{"index": {}}
{"@timestamp": "2023-10-23T13:33:34.937Z", "client_ip": "172.21.0.5", "message": "Disconnected", "event_duration": 1232382}
{"index": {}}
{"@timestamp": "2023-10-23T13:51:54.732Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 725448}
{"index": {}}
{"@timestamp": "2023-10-23T13:52:55.015Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 8268153}
{"index": {}}
{"@timestamp": "2023-10-23T13:53:55.832Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 5033755}
{"index": {}}
{"@timestamp": "2023-10-23T13:55:01.543Z", "client_ip": "172.21.3.15", "message": "Connected to 10.1.0.1", "event_duration": 1756467}
The data set used in this guide has been preloaded into the Elastic ES|QL public demo environment. Visit ela.st/ql to start using it.
Run an ES|QL query
editIn Kibana, you can use Console or Discover to run ES|QL queries:
To get started with ES|QL in Console, open the main menu and select Dev Tools.
The general structure of an ES|QL query API request is:
POST /_query?format=txt
{
"query": """
"""
}
Enter the actual ES|QL query between the two sets of triple quotes. For example:
POST /_query?format=txt
{
"query": """
FROM sample_data
"""
}
To get started with ES|QL in Discover, open the main menu and select Discover. Next, select Try ES|QL from the application menu bar.
Adjust the time filter so it includes the timestamps in the sample data (October 23rd, 2023).
After switching to ES|QL mode, the query bar shows a sample query. You can replace this query with the queries in this getting started guide.
To make it easier to write queries, auto-complete offers suggestions with possible commands and functions:
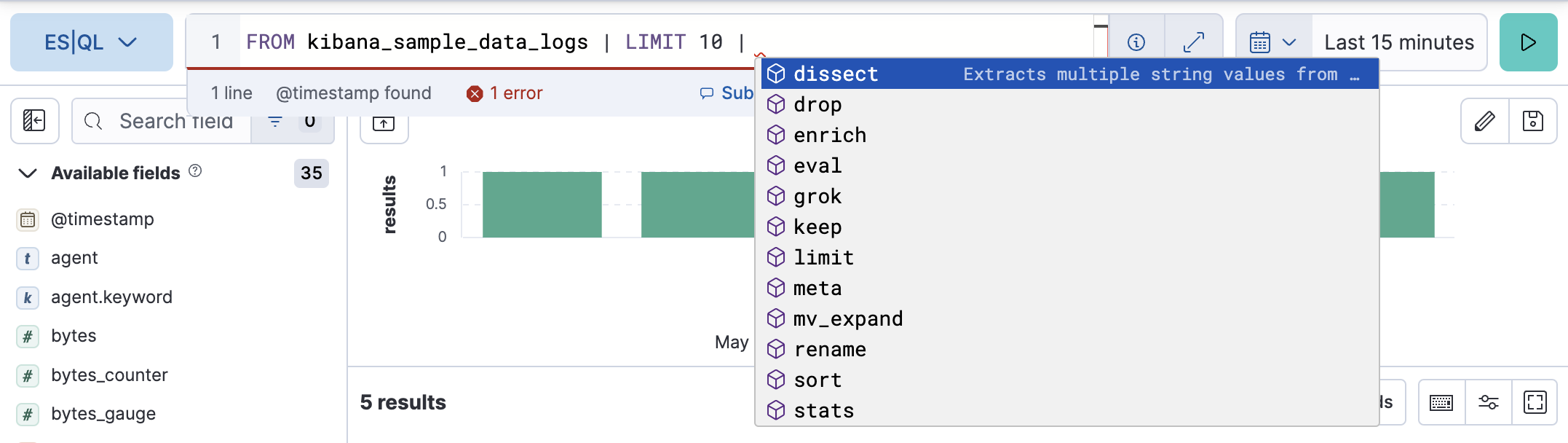
You can adjust the editor’s height by dragging its bottom border to your liking.
Your first ES|QL query
editEach ES|QL query starts with a source command. A source command produces a table, typically with data from Elasticsearch.

The FROM source command returns a table with documents from a data
stream, index, or alias. Each row in the resulting table represents a document.
This query returns up to 1000 documents from the sample_data index:
FROM sample_data
Each column corresponds to a field, and can be accessed by the name of that field.
ES|QL keywords are case-insensitive. The following query is identical to the previous one:
from sample_data
Processing commands
editA source command can be followed by one or more
processing commands, separated by a pipe character:
|. Processing commands change an input table by adding, removing, or changing
rows and columns. Processing commands can perform filtering, projection,
aggregation, and more.
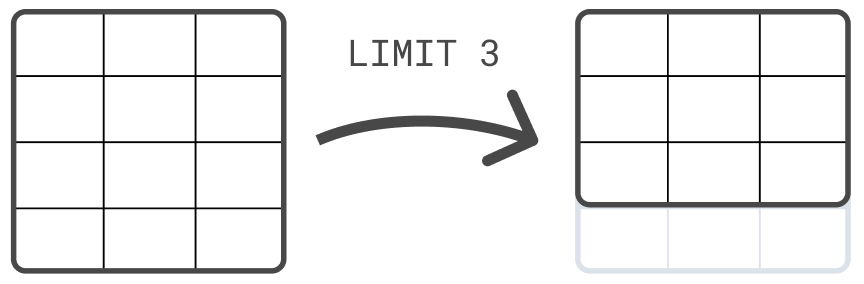
For example, you can use the LIMIT command to limit the number of rows
that are returned, up to a maximum of 10,000 rows:
FROM sample_data | LIMIT 3
For readability, you can put each command on a separate line. However, you don’t have to. The following query is identical to the previous one:
FROM sample_data | LIMIT 3
Sort a table
edit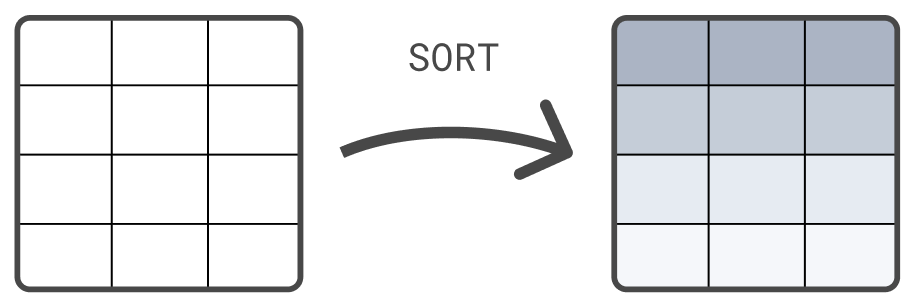
Another processing command is the SORT command. By default, the rows
returned by FROM don’t have a defined sort order. Use the SORT command to
sort rows on one or more columns:
FROM sample_data | SORT @timestamp DESC
Query the data
editUse the WHERE command to query the data. For example, to find all
events with a duration longer than 5ms:
FROM sample_data | WHERE event_duration > 5000000
WHERE supports several operators. For example, you can use LIKE to run a wildcard query against the message column:
FROM sample_data | WHERE message LIKE "Connected*"
More processing commands
editThere are many other processing commands, like KEEP and DROP
to keep or drop columns, ENRICH to enrich a table with data from
indices in Elasticsearch, and DISSECT and GROK to process data. Refer
to Processing commands for an overview of all processing commands.
Chain processing commands
editYou can chain processing commands, separated by a pipe character: |. Each
processing command works on the output table of the previous command. The result
of a query is the table produced by the final processing command.
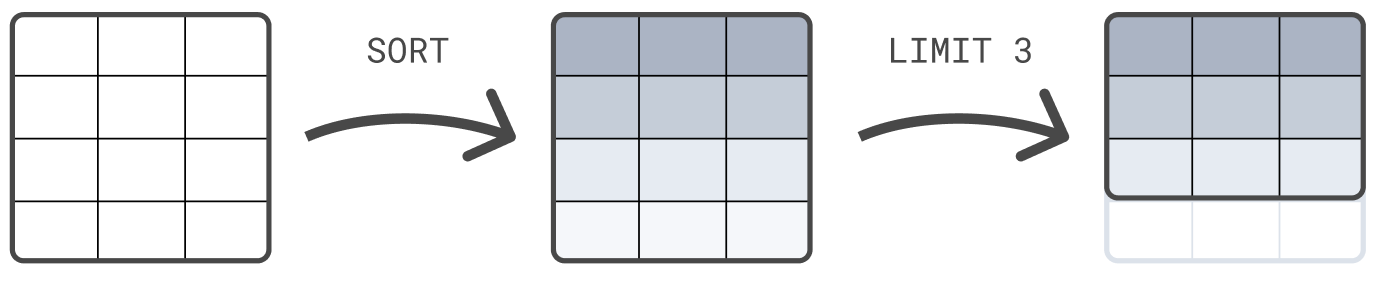
The following example first sorts the table on @timestamp, and next limits the
result set to 3 rows:
FROM sample_data | SORT @timestamp DESC | LIMIT 3
The order of processing commands is important. First limiting the result set to 3 rows before sorting those 3 rows would most likely return a result that is different than this example, where the sorting comes before the limit.
Compute values
editUse the EVAL command to append columns to a table, with calculated
values. For example, the following query appends a duration_ms column. The
values in the column are computed by dividing event_duration by 1,000,000. In
other words: event_duration converted from nanoseconds to milliseconds.
FROM sample_data | EVAL duration_ms = event_duration/1000000.0
EVAL supports several functions. For example, to round a
number to the closest number with the specified number of digits, use the
ROUND function:
FROM sample_data | EVAL duration_ms = ROUND(event_duration/1000000.0, 1)
Calculate statistics
editES|QL can not only be used to query your data, you can also use it to aggregate
your data. Use the STATS command to calculate statistics. For
example, the median duration:
FROM sample_data | STATS median_duration = MEDIAN(event_duration)
You can calculate multiple stats with one command:
FROM sample_data | STATS median_duration = MEDIAN(event_duration), max_duration = MAX(event_duration)
Use BY to group calculated stats by one or more columns. For example, to
calculate the median duration per client IP:
FROM sample_data | STATS median_duration = MEDIAN(event_duration) BY client_ip
Access columns
editYou can access columns by their name. If a name contains special characters,
it needs to be quoted with backticks (`).
Assigning an explicit name to a column created by EVAL or STATS is optional.
If you don’t provide a name, the new column name is equal to the function
expression. For example:
FROM sample_data | EVAL event_duration/1000000.0
In this query, EVAL adds a new column named event_duration/1000000.0.
Because its name contains special characters, to access this column, quote it
with backticks:
FROM sample_data | EVAL event_duration/1000000.0 | STATS MEDIAN(`event_duration/1000000.0`)
Create a histogram
editTo track statistics over time, ES|QL enables you to create histograms using the
BUCKET function. BUCKET creates human-friendly bucket sizes
and returns a value for each row that corresponds to the resulting bucket the
row falls into.
Combine BUCKET with STATS to create a histogram. For example,
to count the number of events per hour:
FROM sample_data | STATS c = COUNT(*) BY bucket = BUCKET(@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
Or the median duration per hour:
FROM sample_data | KEEP @timestamp, event_duration | STATS median_duration = MEDIAN(event_duration) BY bucket = BUCKET(@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
Enrich data
editES|QL enables you to enrich a table with data from indices
in Elasticsearch, using the ENRICH command.
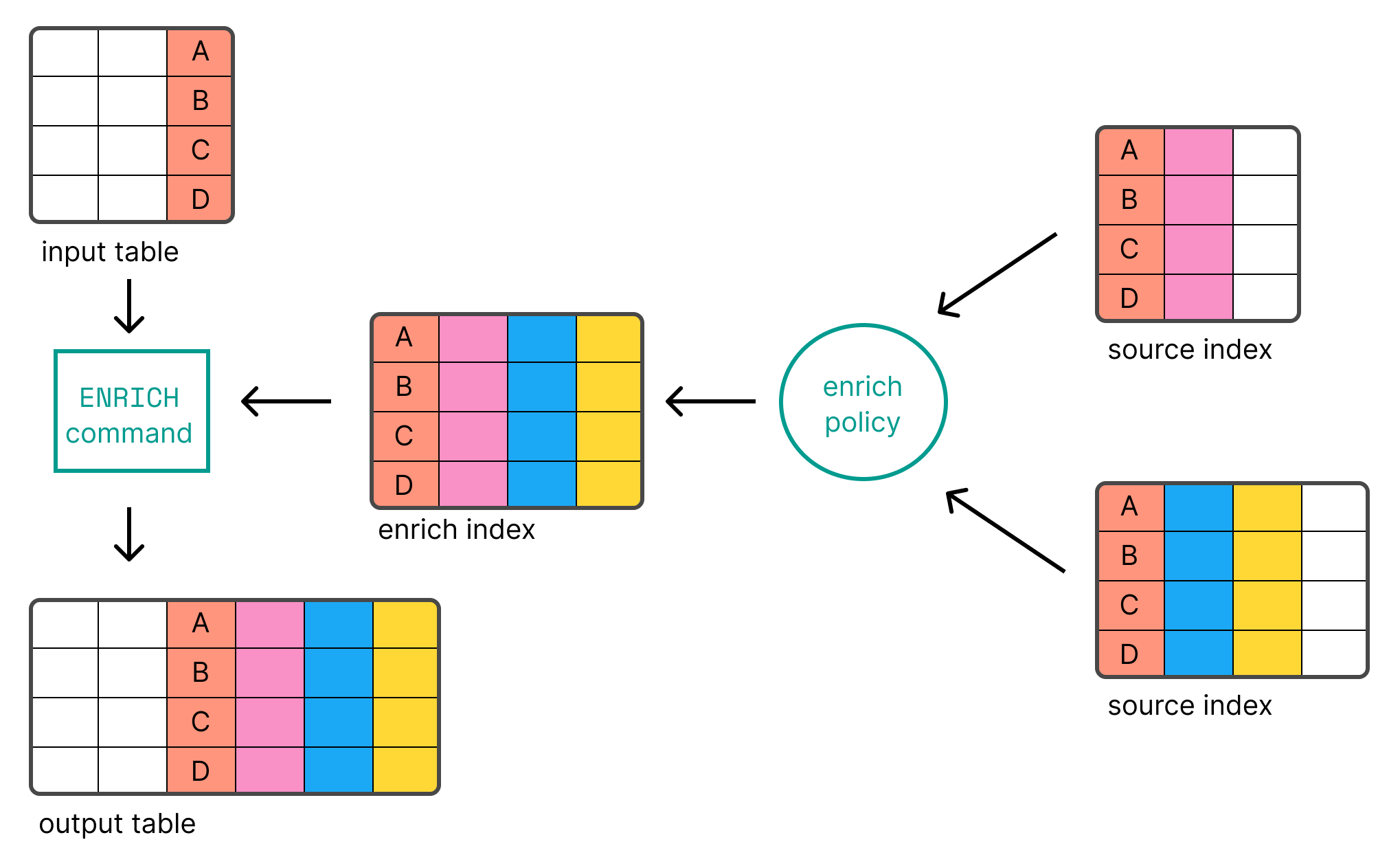
Before you can use ENRICH, you first need to
create and execute
an enrich policy.
The following requests create and execute a policy called clientip_policy. The
policy links an IP address to an environment ("Development", "QA", or
"Production"):
resp = client.indices.create(
index="clientips",
mappings={
"properties": {
"client_ip": {
"type": "keyword"
},
"env": {
"type": "keyword"
}
}
},
)
print(resp)
resp1 = client.bulk(
index="clientips",
operations=[
{
"index": {}
},
{
"client_ip": "172.21.0.5",
"env": "Development"
},
{
"index": {}
},
{
"client_ip": "172.21.2.113",
"env": "QA"
},
{
"index": {}
},
{
"client_ip": "172.21.2.162",
"env": "QA"
},
{
"index": {}
},
{
"client_ip": "172.21.3.15",
"env": "Production"
},
{
"index": {}
},
{
"client_ip": "172.21.3.16",
"env": "Production"
}
],
)
print(resp1)
resp2 = client.enrich.put_policy(
name="clientip_policy",
match={
"indices": "clientips",
"match_field": "client_ip",
"enrich_fields": [
"env"
]
},
)
print(resp2)
resp3 = client.enrich.execute_policy(
name="clientip_policy",
wait_for_completion=False,
)
print(resp3)
response = client.indices.create(
index: 'clientips',
body: {
mappings: {
properties: {
client_ip: {
type: 'keyword'
},
env: {
type: 'keyword'
}
}
}
}
)
puts response
response = client.bulk(
index: 'clientips',
body: [
{
index: {}
},
{
client_ip: '172.21.0.5',
env: 'Development'
},
{
index: {}
},
{
client_ip: '172.21.2.113',
env: 'QA'
},
{
index: {}
},
{
client_ip: '172.21.2.162',
env: 'QA'
},
{
index: {}
},
{
client_ip: '172.21.3.15',
env: 'Production'
},
{
index: {}
},
{
client_ip: '172.21.3.16',
env: 'Production'
}
]
)
puts response
response = client.enrich.put_policy(
name: 'clientip_policy',
body: {
match: {
indices: 'clientips',
match_field: 'client_ip',
enrich_fields: [
'env'
]
}
}
)
puts response
response = client.enrich.execute_policy(
name: 'clientip_policy',
wait_for_completion: false
)
puts response
const response = await client.indices.create({
index: "clientips",
mappings: {
properties: {
client_ip: {
type: "keyword",
},
env: {
type: "keyword",
},
},
},
});
console.log(response);
const response1 = await client.bulk({
index: "clientips",
operations: [
{
index: {},
},
{
client_ip: "172.21.0.5",
env: "Development",
},
{
index: {},
},
{
client_ip: "172.21.2.113",
env: "QA",
},
{
index: {},
},
{
client_ip: "172.21.2.162",
env: "QA",
},
{
index: {},
},
{
client_ip: "172.21.3.15",
env: "Production",
},
{
index: {},
},
{
client_ip: "172.21.3.16",
env: "Production",
},
],
});
console.log(response1);
const response2 = await client.enrich.putPolicy({
name: "clientip_policy",
match: {
indices: "clientips",
match_field: "client_ip",
enrich_fields: ["env"],
},
});
console.log(response2);
const response3 = await client.enrich.executePolicy({
name: "clientip_policy",
wait_for_completion: "false",
});
console.log(response3);
PUT clientips
{
"mappings": {
"properties": {
"client_ip": {
"type": "keyword"
},
"env": {
"type": "keyword"
}
}
}
}
PUT clientips/_bulk
{ "index" : {}}
{ "client_ip": "172.21.0.5", "env": "Development" }
{ "index" : {}}
{ "client_ip": "172.21.2.113", "env": "QA" }
{ "index" : {}}
{ "client_ip": "172.21.2.162", "env": "QA" }
{ "index" : {}}
{ "client_ip": "172.21.3.15", "env": "Production" }
{ "index" : {}}
{ "client_ip": "172.21.3.16", "env": "Production" }
PUT /_enrich/policy/clientip_policy
{
"match": {
"indices": "clientips",
"match_field": "client_ip",
"enrich_fields": ["env"]
}
}
PUT /_enrich/policy/clientip_policy/_execute?wait_for_completion=false
On the demo environment at ela.st/ql,
an enrich policy called clientip_policy has already been created an executed.
The policy links an IP address to an environment ("Development", "QA", or
"Production").
After creating and executing a policy, you can use it with the ENRICH
command:
FROM sample_data | KEEP @timestamp, client_ip, event_duration | EVAL client_ip = TO_STRING(client_ip) | ENRICH clientip_policy ON client_ip WITH env
You can use the new env column that’s added by the ENRICH command in
subsequent commands. For example, to calculate the median duration per
environment:
FROM sample_data | KEEP @timestamp, client_ip, event_duration | EVAL client_ip = TO_STRING(client_ip) | ENRICH clientip_policy ON client_ip WITH env | STATS median_duration = MEDIAN(event_duration) BY env
For more about data enrichment with ES|QL, refer to Data enrichment.
Process data
editYour data may contain unstructured strings that you want to structure to make it easier to analyze the data. For example, the sample data contains log messages like:
"Connected to 10.1.0.3"
By extracting the IP address from these messages, you can determine which IP has accepted the most client connections.
To structure unstructured strings at query time, you can use the ES|QL
DISSECT and GROK commands. DISSECT works by breaking up a
string using a delimiter-based pattern. GROK works similarly, but uses regular
expressions. This makes GROK more powerful, but generally also slower.
In this case, no regular expressions are needed, as the message is
straightforward: "Connected to ", followed by the server IP. To match this
string, you can use the following DISSECT command:
FROM sample_data
| DISSECT message "Connected to %{server_ip}"
This adds a server_ip column to those rows that have a message that matches
this pattern. For other rows, the value of server_ip is null.
You can use the new server_ip column that’s added by the DISSECT command in
subsequent commands. For example, to determine how many connections each server
has accepted:
FROM sample_data
| WHERE STARTS_WITH(message, "Connected to")
| DISSECT message "Connected to %{server_ip}"
| STATS COUNT(*) BY server_ip
For more about data processing with ES|QL, refer to Data processing with DISSECT and GROK.
Learn more
editTo learn more about ES|QL, refer to ES|QL reference and Using ES|QL.