ES|QL functions and operators
editES|QL functions and operators
editES|QL provides a comprehensive set of functions and operators for working with data. The reference documentation is divided into the following categories:
Functions overview
editAggregate functions
Math functions
String functions
Date and time functions
-
[preview]
This functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
AUTO_BUCKET -
DATE_DIFF -
DATE_EXTRACT -
DATE_FORMAT -
DATE_PARSE -
DATE_TRUNC -
NOW
Type conversion functions
-
TO_BOOLEAN -
TO_CARTESIANPOINT -
TO_CARTESIANSHAPE -
TO_DATETIME -
TO_DEGREES -
TO_DOUBLE -
TO_GEOPOINT -
TO_GEOSHAPE -
TO_INTEGER -
TO_IP -
TO_LONG -
TO_RADIANS -
TO_STRING -
[preview]
This functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
TO_UNSIGNED_LONG -
TO_VERSION
Operators overview
editES|QL aggregate functions
editThe STATS ... BY function supports these aggregate functions:
AVG
editSyntax
AVG(expression)
-
expression - Numeric expression.
Description
The average of a numeric expression.
Supported types
The result is always a double no matter the input type.
Examples
FROM employees | STATS AVG(height)
| AVG(height):double |
|---|
1.7682 |
The expression can use inline functions. For example, to calculate the average
over a multivalued column, first use MV_AVG to average the multiple values per
row, and use the result with the AVG function:
FROM employees | STATS avg_salary_change = AVG(MV_AVG(salary_change))
| avg_salary_change:double |
|---|
1.3904535864978902 |
COUNT
editSyntax
COUNT([expression])
Parameters
-
expression -
Expression that outputs values to be counted.
If omitted, equivalent to
COUNT(*)(the number of rows).
Description
Returns the total number (count) of input values.
Supported types
Can take any field type as input.
Examples
FROM employees | STATS COUNT(height)
| COUNT(height):long |
|---|
100 |
To count the number of rows, use COUNT() or COUNT(*):
FROM employees | STATS count = COUNT(*) BY languages | SORT languages DESC
| count:long | languages:integer |
|---|---|
10 |
null |
21 |
5 |
18 |
4 |
17 |
3 |
19 |
2 |
15 |
1 |
The expression can use inline functions. This example splits a string into
multiple values using the SPLIT function and counts the values:
ROW words="foo;bar;baz;qux;quux;foo" | STATS word_count = COUNT(SPLIT(words, ";"))
| word_count:long |
|---|
6 |
COUNT_DISTINCT
editSyntax
COUNT_DISTINCT(expression[, precision_threshold])
Parameters
-
expression - Expression that outputs the values on which to perform a distinct count.
-
precision_threshold - Precision threshold. Refer to Counts are approximate. The maximum supported value is 40000. Thresholds above this number will have the same effect as a threshold of 40000. The default value is 3000.
Description
Returns the approximate number of distinct values.
Supported types
Can take any field type as input.
Examples
FROM hosts | STATS COUNT_DISTINCT(ip0), COUNT_DISTINCT(ip1)
| COUNT_DISTINCT(ip0):long | COUNT_DISTINCT(ip1):long |
|---|---|
7 |
8 |
With the optional second parameter to configure the precision threshold:
FROM hosts | STATS COUNT_DISTINCT(ip0, 80000), COUNT_DISTINCT(ip1, 5)
| COUNT_DISTINCT(ip0, 80000):long | COUNT_DISTINCT(ip1, 5):long |
|---|---|
7 |
9 |
The expression can use inline functions. This example splits a string into
multiple values using the SPLIT function and counts the unique values:
ROW words="foo;bar;baz;qux;quux;foo" | STATS distinct_word_count = COUNT_DISTINCT(SPLIT(words, ";"))
| distinct_word_count:long |
|---|
5 |
Counts are approximate
editComputing exact counts requires loading values into a set and returning its size. This doesn’t scale when working on high-cardinality sets and/or large values as the required memory usage and the need to communicate those per-shard sets between nodes would utilize too many resources of the cluster.
This COUNT_DISTINCT function is based on the
HyperLogLog++
algorithm, which counts based on the hashes of the values with some interesting
properties:
- configurable precision, which decides on how to trade memory for accuracy,
- excellent accuracy on low-cardinality sets,
- fixed memory usage: no matter if there are tens or billions of unique values, memory usage only depends on the configured precision.
For a precision threshold of c, the implementation that we are using requires
about c * 8 bytes.
The following chart shows how the error varies before and after the threshold:
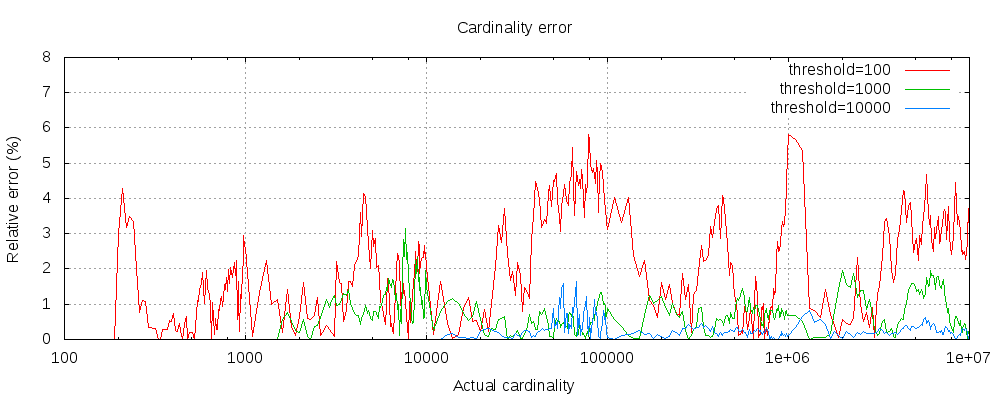
For all 3 thresholds, counts have been accurate up to the configured threshold. Although not guaranteed, this is likely to be the case. Accuracy in practice depends on the dataset in question. In general, most datasets show consistently good accuracy. Also note that even with a threshold as low as 100, the error remains very low (1-6% as seen in the above graph) even when counting millions of items.
The HyperLogLog++ algorithm depends on the leading zeros of hashed values, the exact distributions of hashes in a dataset can affect the accuracy of the cardinality.
The COUNT_DISTINCT function takes an optional second parameter to configure
the precision threshold. The precision_threshold options allows to trade memory
for accuracy, and defines a unique count below which counts are expected to be
close to accurate. Above this value, counts might become a bit more fuzzy. The
maximum supported value is 40000, thresholds above this number will have the
same effect as a threshold of 40000. The default value is 3000.
MAX
editSyntax
MAX(expression)
Parameters
-
expression - Expression from which to return the maximum value.
Description
Returns the maximum value of a numeric expression.
Example
FROM employees | STATS MAX(languages)
| MAX(languages):integer |
|---|
5 |
The expression can use inline functions. For example, to calculate the maximum
over an average of a multivalued column, use MV_AVG to first average the
multiple values per row, and use the result with the MAX function:
FROM employees | STATS max_avg_salary_change = MAX(MV_AVG(salary_change))
| max_avg_salary_change:double |
|---|
13.75 |
MEDIAN
editSyntax
MEDIAN(expression)
Parameters
-
expression - Expression from which to return the median value.
Description
Returns the value that is greater than half of all values and less than half of
all values, also known as the 50% PERCENTILE.
Like PERCENTILE, MEDIAN is usually approximate.
MEDIAN is also non-deterministic.
This means you can get slightly different results using the same data.
Example
FROM employees | STATS MEDIAN(salary), PERCENTILE(salary, 50)
| MEDIAN(salary):double | PERCENTILE(salary, 50):double |
|---|---|
47003 |
47003 |
The expression can use inline functions. For example, to calculate the median of
the maximum values of a multivalued column, first use MV_MAX to get the
maximum value per row, and use the result with the MEDIAN function:
FROM employees | STATS median_max_salary_change = MEDIAN(MV_MAX(salary_change))
| median_max_salary_change:double |
|---|
7.69 |
MEDIAN_ABSOLUTE_DEVIATION
editSyntax
MEDIAN_ABSOLUTE_DEVIATION(expression)
Parameters
-
expression - Expression from which to return the median absolute deviation.
Description
Returns the median absolute deviation, a measure of variability. It is a robust statistic, meaning that it is useful for describing data that may have outliers, or may not be normally distributed. For such data it can be more descriptive than standard deviation.
It is calculated as the median of each data point’s deviation from the median of
the entire sample. That is, for a random variable X, the median absolute
deviation is median(|median(X) - X|).
Like PERCENTILE, MEDIAN_ABSOLUTE_DEVIATION is
usually approximate.
MEDIAN_ABSOLUTE_DEVIATION is also non-deterministic.
This means you can get slightly different results using the same data.
Example
FROM employees | STATS MEDIAN(salary), MEDIAN_ABSOLUTE_DEVIATION(salary)
| MEDIAN(salary):double | MEDIAN_ABSOLUTE_DEVIATION(salary):double |
|---|---|
47003 |
10096.5 |
The expression can use inline functions. For example, to calculate the the
median absolute deviation of the maximum values of a multivalued column, first
use MV_MAX to get the maximum value per row, and use the result with the
MEDIAN_ABSOLUTE_DEVIATION function:
FROM employees | STATS m_a_d_max_salary_change = MEDIAN_ABSOLUTE_DEVIATION(MV_MAX(salary_change))
| m_a_d_max_salary_change:double |
|---|
5.69 |
MIN
editSyntax
MIN(expression)
Parameters
-
expression - Expression from which to return the minimum value.
Description
Returns the minimum value of a numeric expression.
Example
FROM employees | STATS MIN(languages)
| MIN(languages):integer |
|---|
1 |
The expression can use inline functions. For example, to calculate the minimum
over an average of a multivalued column, use MV_AVG to first average the
multiple values per row, and use the result with the MIN function:
FROM employees | STATS min_avg_salary_change = MIN(MV_AVG(salary_change))
| min_avg_salary_change:double |
|---|
-8.46 |
PERCENTILE
editSyntax
PERCENTILE(expression, percentile)
Parameters
-
expression - Expression from which to return a percentile.
-
percentile - A constant numeric expression.
Description
Returns the value at which a certain percentage of observed values occur. For
example, the 95th percentile is the value which is greater than 95% of the
observed values and the 50th percentile is the MEDIAN.
Example
FROM employees
| STATS p0 = PERCENTILE(salary, 0)
, p50 = PERCENTILE(salary, 50)
, p99 = PERCENTILE(salary, 99)
| p0:double | p50:double | p99:double |
|---|---|---|
25324 |
47003 |
74970.29 |
The expression can use inline functions. For example, to calculate a percentile
of the maximum values of a multivalued column, first use MV_MAX to get the
maximum value per row, and use the result with the PERCENTILE function:
FROM employees | STATS p80_max_salary_change = PERCENTILE(MV_MAX(salary_change), 80)
| p80_max_salary_change:double |
|---|
12.132 |
PERCENTILE is (usually) approximate
editThere are many different algorithms to calculate percentiles. The naive
implementation simply stores all the values in a sorted array. To find the 50th
percentile, you simply find the value that is at my_array[count(my_array) * 0.5].
Clearly, the naive implementation does not scale — the sorted array grows linearly with the number of values in your dataset. To calculate percentiles across potentially billions of values in an Elasticsearch cluster, approximate percentiles are calculated.
The algorithm used by the percentile metric is called TDigest (introduced by
Ted Dunning in
Computing Accurate Quantiles using T-Digests).
When using this metric, there are a few guidelines to keep in mind:
-
Accuracy is proportional to
q(1-q). This means that extreme percentiles (e.g. 99%) are more accurate than less extreme percentiles, such as the median - For small sets of values, percentiles are highly accurate (and potentially 100% accurate if the data is small enough).
- As the quantity of values in a bucket grows, the algorithm begins to approximate the percentiles. It is effectively trading accuracy for memory savings. The exact level of inaccuracy is difficult to generalize, since it depends on your data distribution and volume of data being aggregated
The following chart shows the relative error on a uniform distribution depending on the number of collected values and the requested percentile:
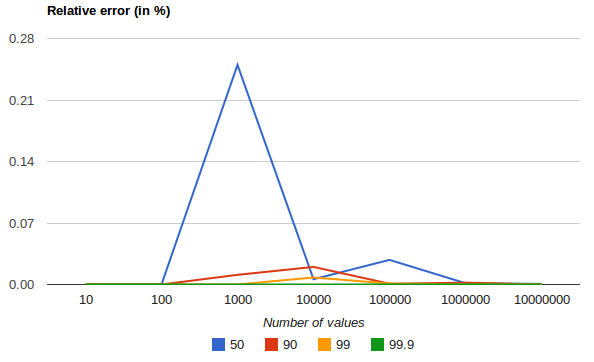
It shows how precision is better for extreme percentiles. The reason why error diminishes for large number of values is that the law of large numbers makes the distribution of values more and more uniform and the t-digest tree can do a better job at summarizing it. It would not be the case on more skewed distributions.
PERCENTILE is also non-deterministic.
This means you can get slightly different results using the same data.
ST_CENTROID
editCalculate the spatial centroid over a field with spatial point geometry type.
FROM airports | STATS centroid=ST_CENTROID(location)
| centroid:geo_point |
|---|
POINT(-0.030548143003023033 24.37553649504829) |
Supported types:
| v | result |
|---|---|
geo_point |
geo_point |
cartesian_point |
cartesian_point |
SUM
editSyntax
SUM(expression)
-
expression - Numeric expression.
Description
Returns the sum of a numeric expression.
Example
FROM employees | STATS SUM(languages)
| SUM(languages):long |
|---|
281 |
The expression can use inline functions. For example, to calculate
the sum of each employee’s maximum salary changes, apply the
MV_MAX function to each row and then sum the results:
FROM employees | STATS total_salary_changes = SUM(MV_MAX(salary_change))
| total_salary_changes:double |
|---|
446.75 |
ES|QL mathematical functions
editES|QL supports these mathematical functions:
ABS
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Returns the absolute value.
Supported types
| n | result |
|---|---|
double |
double |
integer |
integer |
long |
long |
unsigned_long |
unsigned_long |
Examples
ROW number = -1.0 | EVAL abs_number = ABS(number)
| number:double | abs_number:double |
|---|---|
-1.0 |
1.0 |
FROM employees | KEEP first_name, last_name, height | EVAL abs_height = ABS(0.0 - height)
| first_name:keyword | last_name:keyword | height:double | abs_height:double |
|---|---|---|---|
Alejandro |
McAlpine |
1.48 |
1.48 |
Amabile |
Gomatam |
2.09 |
2.09 |
Anneke |
Preusig |
1.56 |
1.56 |
ACOS
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Returns the arccosine of n as an
angle, expressed in radians.
Supported types
| n | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW a=.9 | EVAL acos=ACOS(a)
| a:double | acos:double |
|---|---|
.9 |
0.45102681179626236 |
ASIN
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Returns the arcsine of the input numeric expression as an angle, expressed in radians.
Supported types
| n | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW a=.9 | EVAL asin=ASIN(a)
| a:double | asin:double |
|---|---|
.9 |
1.1197695149986342 |
ATAN
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Returns the arctangent of the input numeric expression as an angle, expressed in radians.
Supported types
| n | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW a=12.9 | EVAL atan=ATAN(a)
| a:double | atan:double |
|---|---|
12.9 |
1.4934316673669235 |
ATAN2
editSyntax
Parameters
-
y -
Numeric expression. If
null, the function returnsnull. -
x -
Numeric expression. If
null, the function returnsnull.
Description
The angle between the positive x-axis and the ray from the origin to the point (x , y) in the Cartesian plane, expressed in radians.
Supported types
| y | x | result |
|---|---|---|
double |
double |
double |
double |
integer |
double |
double |
long |
double |
double |
unsigned_long |
double |
integer |
double |
double |
integer |
integer |
double |
integer |
long |
double |
integer |
unsigned_long |
double |
long |
double |
double |
long |
integer |
double |
long |
long |
double |
long |
unsigned_long |
double |
unsigned_long |
double |
double |
unsigned_long |
integer |
double |
unsigned_long |
long |
double |
unsigned_long |
unsigned_long |
double |
Example
ROW y=12.9, x=.6 | EVAL atan2=ATAN2(y, x)
| y:double | x:double | atan2:double |
|---|---|---|
12.9 |
0.6 |
1.5243181954438936 |
CEIL
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Round a number up to the nearest integer.
This is a noop for long (including unsigned) and integer.
For double this picks the closest double value to the integer
similar to Math.ceil.
Supported types
| n | result |
|---|---|
double |
double |
integer |
integer |
long |
long |
unsigned_long |
unsigned_long |
Example
ROW a=1.8 | EVAL a=CEIL(a)
| a:double |
|---|
2 |
COS
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Returns the cosine of n. Input expected in
radians.
Supported types
| n | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW a=1.8 | EVAL cos=COS(a)
| a:double | cos:double |
|---|---|
1.8 |
-0.2272020946930871 |
COSH
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Returns the hyperbolic cosine.
Supported types
| n | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW a=1.8 | EVAL cosh=COSH(a)
| a:double | cosh:double |
|---|---|
1.8 |
3.1074731763172667 |
E
editSyntax
Description
Returns Euler’s number.
Example
ROW E()
| E():double |
|---|
2.718281828459045 |
FLOOR
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Rounds a number down to the nearest integer.
This is a noop for long (including unsigned) and integer.
For double this picks the closest double value to the integer
similar to Math.floor.
Supported types
| n | result |
|---|---|
double |
double |
integer |
integer |
long |
long |
unsigned_long |
unsigned_long |
Example
ROW a=1.8 | EVAL a=FLOOR(a)
| a:double |
|---|
1 |
LOG
editSyntax
LOG([base,] value)
Parameters
-
base -
Numeric expression. If
null, the function returnsnull. The base is an optional input parameter. If a base is not provided, this function returns the natural logarithm (base e) of a value. -
value -
Numeric expression. If
null, the function returnsnull.
Description
Returns the logarithm of a value to a base. The input can be any numeric value, the return value is always a double.
Logs of zero, negative numbers, infinites and base of one return null as well as a warning.
Supported types
| base | value | result |
|---|---|---|
double |
double |
double |
double |
integer |
double |
double |
long |
double |
double |
unsigned_long |
double |
integer |
double |
double |
integer |
integer |
double |
integer |
long |
double |
integer |
unsigned_long |
double |
long |
double |
double |
long |
integer |
double |
long |
long |
double |
long |
unsigned_long |
double |
unsigned_long |
double |
double |
unsigned_long |
integer |
double |
unsigned_long |
long |
double |
unsigned_long |
unsigned_long |
double |
Example
ROW base = 2.0, value = 8.0 | EVAL s = LOG(base, value)
| base: double | value: double | s:double |
|---|---|---|
2.0 |
8.0 |
3.0 |
row value = 100 | EVAL s = LOG(value);
| value: integer | s:double |
|---|---|
100 |
4.605170185988092 |
LOG10
editSyntax
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Returns the logarithm to base 10. The input can be any numeric value, the return value is always a double.
Logs of 0, negative numbers, and infinites return null as well as a warning.
Supported types
| n | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW d = 1000.0 | EVAL s = LOG10(d)
| d: double | s:double |
|---|---|
1000.0 |
3.0 |
PI
editSyntax
Description
Returns the ratio of a circle’s circumference to its diameter.
Example
ROW PI()
| PI():double |
|---|
3.141592653589793 |
POW
editSyntax
Parameters
-
base -
Numeric expression. If
null, the function returnsnull. -
exponent -
Numeric expression. If
null, the function returnsnull.
Description
Returns the value of base raised to the power of exponent. Both arguments
must be numeric. The output is always a double. Note that it is still possible
to overflow a double result here; in that case, null will be returned.
Supported types
| base | exponent | result |
|---|---|---|
double |
double |
double |
double |
integer |
double |
double |
long |
double |
double |
unsigned_long |
double |
integer |
double |
double |
integer |
integer |
double |
integer |
long |
double |
integer |
unsigned_long |
double |
long |
double |
double |
long |
integer |
double |
long |
long |
double |
long |
unsigned_long |
double |
unsigned_long |
double |
double |
unsigned_long |
integer |
double |
unsigned_long |
long |
double |
unsigned_long |
unsigned_long |
double |
Examples
ROW base = 2.0, exponent = 2 | EVAL result = POW(base, exponent)
| base:double | exponent:integer | result:double |
|---|---|---|
2.0 |
2 |
4.0 |
The exponent can be a fraction, which is similar to performing a root.
For example, the exponent of 0.5 will give the square root of the base:
ROW base = 4, exponent = 0.5 | EVAL s = POW(base, exponent)
| base:integer | exponent:double | s:double |
|---|---|---|
4 |
0.5 |
2.0 |
ROUND
editSyntax
Parameters
-
value -
Numeric expression. If
null, the function returnsnull. -
decimals -
Numeric expression. If
null, the function returnsnull.
Description
Rounds a number to the closest number with the specified number of digits. Defaults to 0 digits if no number of digits is provided. If the specified number of digits is negative, rounds to the number of digits left of the decimal point.
Supported types
| value | decimals | result |
|---|---|---|
double |
integer |
double |
Example
FROM employees | KEEP first_name, last_name, height | EVAL height_ft = ROUND(height * 3.281, 1)
| first_name:keyword | last_name:keyword | height:double | height_ft:double |
|---|---|---|---|
Arumugam |
Ossenbruggen |
2.1 |
6.9 |
Kwee |
Schusler |
2.1 |
6.9 |
Saniya |
Kalloufi |
2.1 |
6.9 |
SIN
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Sine trigonometric function. Input expected in radians.
Supported types
| n | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW a=1.8 | EVAL sin=SIN(a)
| a:double | sin:double |
|---|---|
1.8 |
0.9738476308781951 |
SINH
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Sine hyperbolic function.
Supported types
| n | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW a=1.8 | EVAL sinh=SINH(a)
| a:double | sinh:double |
|---|---|
1.8 |
2.94217428809568 |
SQRT
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Returns the square root of a number. The input can be any numeric value, the return value is always a double.
Square roots of negative numbers are NaN. Square roots of infinites are infinite.
Supported types
| n | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW d = 100.0 | EVAL s = SQRT(d)
| d: double | s:double |
|---|---|
100.0 |
10.0 |
TAN
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Tangent trigonometric function. Input expected in radians.
Supported types
| n | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW a=1.8 | EVAL tan=TAN(a)
| a:double | tan:double |
|---|---|
1.8 |
-4.286261674628062 |
TANH
editSyntax
Parameters
-
n -
Numeric expression. If
null, the function returnsnull.
Description
Tangent hyperbolic function.
Supported types
| n | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW a=1.8 | EVAL tanh=TANH(a)
| a:double | tanh:double |
|---|---|
1.8 |
0.9468060128462683 |
TAU
editSyntax
Description
Returns the ratio of a circle’s circumference to its radius.
Example
ROW TAU()
| TAU():double |
|---|
6.283185307179586 |
ES|QL string functions
editES|QL supports these string functions:
CONCAT
editSyntax
CONCAT(string1, string2[, ..., stringN])
Parameters
-
stringX - Strings to concatenate.
Description
Concatenates two or more strings.
Example
FROM employees | KEEP first_name, last_name | EVAL fullname = CONCAT(first_name, " ", last_name)
| first_name:keyword | last_name:keyword | fullname:keyword |
|---|---|---|
Alejandro |
McAlpine |
Alejandro McAlpine |
Amabile |
Gomatam |
Amabile Gomatam |
Anneke |
Preusig |
Anneke Preusig |
LEFT
editSyntax
Parameters
-
str - The string from which to return a substring.
-
length - The number of characters to return.
Description
Returns the substring that extracts length chars from str starting from the left.
Supported types
| str | length | result |
|---|---|---|
keyword |
integer |
keyword |
text |
integer |
keyword |
Example
FROM employees | KEEP last_name | EVAL left = LEFT(last_name, 3) | SORT last_name ASC | LIMIT 5
| last_name:keyword | left:keyword |
|---|---|
Awdeh |
Awd |
Azuma |
Azu |
Baek |
Bae |
Bamford |
Bam |
Bernatsky |
Ber |
LENGTH
editSyntax
LENGTH(str)
Parameters
-
str -
String expression. If
null, the function returnsnull.
Description
Returns the character length of a string.
Example
FROM employees | KEEP first_name, last_name | EVAL fn_length = LENGTH(first_name)
| first_name:keyword | last_name:keyword | fn_length:integer |
|---|---|---|
Alejandro |
McAlpine |
9 |
Amabile |
Gomatam |
7 |
Anneke |
Preusig |
6 |
LTRIM
editSyntax
Parameters
-
str -
String expression. If
null, the function returnsnull.
Description
Removes leading whitespaces from strings.
Supported types
| str | result |
|---|---|
keyword |
keyword |
text |
text |
Example
ROW message = " some text ", color = " red "
| EVAL message = LTRIM(message)
| EVAL color = LTRIM(color)
| EVAL message = CONCAT("'", message, "'")
| EVAL color = CONCAT("'", color, "'")
| message:keyword | color:keyword |
|---|---|
'some text ' |
'red ' |
REPLACE
editSyntax
Parameters
-
str - String expression.
-
regex - Regular expression.
-
newStr - Replacement string.
Description
The function substitutes in the string str any match of the regular expression
regex with the replacement string newStr.
If any of the arguments is null, the result is null.
Supported types
| str | regex | newStr | result |
|---|---|---|---|
keyword |
keyword |
keyword |
keyword |
keyword |
keyword |
text |
keyword |
keyword |
text |
keyword |
keyword |
keyword |
text |
text |
keyword |
text |
keyword |
keyword |
keyword |
text |
keyword |
text |
keyword |
text |
text |
keyword |
keyword |
text |
text |
text |
keyword |
Example
This example replaces any occurrence of the word "World" with the word "Universe":
ROW str = "Hello World" | EVAL str = REPLACE(str, "World", "Universe") | KEEP str
| str:keyword |
|---|
Hello Universe |
RIGHT
editSyntax
Parameters
-
str - The string from which to returns a substring.
-
length - The number of characters to return.
Description
Return the substring that extracts length chars from str starting from the right.
Supported types
| str | length | result |
|---|---|---|
keyword |
integer |
keyword |
text |
integer |
keyword |
Example
FROM employees | KEEP last_name | EVAL right = RIGHT(last_name, 3) | SORT last_name ASC | LIMIT 5
| last_name:keyword | right:keyword |
|---|---|
Awdeh |
deh |
Azuma |
uma |
Baek |
aek |
Bamford |
ord |
Bernatsky |
sky |
RTRIM
editSyntax
Parameters
-
str -
String expression. If
null, the function returnsnull.
Description
Removes trailing whitespaces from strings.
Supported types
| str | result |
|---|---|
keyword |
keyword |
text |
text |
Example
ROW message = " some text ", color = " red "
| EVAL message = RTRIM(message)
| EVAL color = RTRIM(color)
| EVAL message = CONCAT("'", message, "'")
| EVAL color = CONCAT("'", color, "'")
| message:keyword | color:keyword |
|---|---|
' some text' |
' red' |
SPLIT
editParameters
-
str -
String expression. If
null, the function returnsnull. -
delim - Delimiter. Only single byte delimiters are currently supported.
Description
Splits a single valued string into multiple strings.
Supported types
| str | delim | result |
|---|---|---|
keyword |
keyword |
keyword |
text |
text |
keyword |
Example
ROW words="foo;bar;baz;qux;quux;corge" | EVAL word = SPLIT(words, ";")
| words:keyword | word:keyword |
|---|---|
foo;bar;baz;qux;quux;corge |
[foo,bar,baz,qux,quux,corge] |
SUBSTRING
editSyntax
Parameters
-
str -
String expression. If
null, the function returnsnull. -
start - Start position.
-
length -
Length of the substring from the start position. Optional; if omitted, all
positions after
startare returned.
Description
Returns a substring of a string, specified by a start position and an optional length.
Supported types
| str | start | length | result |
|---|---|---|---|
keyword |
integer |
integer |
keyword |
text |
integer |
integer |
keyword |
Examples
This example returns the first three characters of every last name:
FROM employees | KEEP last_name | EVAL ln_sub = SUBSTRING(last_name, 1, 3)
| last_name:keyword | ln_sub:keyword |
|---|---|
Awdeh |
Awd |
Azuma |
Azu |
Baek |
Bae |
Bamford |
Bam |
Bernatsky |
Ber |
A negative start position is interpreted as being relative to the end of the string. This example returns the last three characters of of every last name:
FROM employees | KEEP last_name | EVAL ln_sub = SUBSTRING(last_name, -3, 3)
| last_name:keyword | ln_sub:keyword |
|---|---|
Awdeh |
deh |
Azuma |
uma |
Baek |
aek |
Bamford |
ord |
Bernatsky |
sky |
If length is omitted, substring returns the remainder of the string. This example returns all characters except for the first:
FROM employees | KEEP last_name | EVAL ln_sub = SUBSTRING(last_name, 2)
| last_name:keyword | ln_sub:keyword |
|---|---|
Awdeh |
wdeh |
Azuma |
zuma |
Baek |
aek |
Bamford |
amford |
Bernatsky |
ernatsky |
TO_LOWER
editSyntax
Parameters
-
str -
String expression. If
null, the function returnsnull.
Description
Returns a new string representing the input string converted to lower case.
Supported types
| str | result |
|---|---|
keyword |
keyword |
text |
text |
Example
ROW message = "Some Text" | EVAL message_lower = TO_LOWER(message)
| message:keyword | message_lower:keyword |
|---|---|
Some Text |
some text |
TO_UPPER
editSyntax
Parameters
-
str -
String expression. If
null, the function returnsnull.
Description
Returns a new string representing the input string converted to upper case.
Supported types
| str | result |
|---|---|
keyword |
keyword |
text |
text |
Example
ROW message = "Some Text" | EVAL message_upper = TO_UPPER(message)
| message:keyword | message_upper:keyword |
|---|---|
Some Text |
SOME TEXT |
TRIM
editSyntax
Parameters
-
str -
String expression. If
null, the function returnsnull.
Description
Removes leading and trailing whitespaces from strings.
Supported types
| str | result |
|---|---|
keyword |
keyword |
text |
text |
Example
ROW message = " some text ", color = " red " | EVAL message = TRIM(message) | EVAL color = TRIM(color)
| message:s | color:s |
|---|---|
some text |
red |
ES|QL date-time functions
editES|QL supports these date-time functions:
-
[preview]
This functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
AUTO_BUCKET -
DATE_DIFF -
DATE_EXTRACT -
DATE_FORMAT -
DATE_PARSE -
DATE_TRUNC -
NOW
AUTO_BUCKET
editThis functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
Syntax
AUTO_BUCKET(expression, buckets, from, to)
Parameters
-
field - Numeric or date expression from which to derive buckets.
-
buckets - Target number of buckets.
-
from - Start of the range. Can be a number or a date expressed as a string.
-
to - End of the range. Can be a number or a date expressed as a string.
Description
Creates human-friendly buckets and returns a value for each row that corresponds to the resulting bucket the row falls into.
Using a target number of buckets, a start of a range, and an end of a range,
AUTO_BUCKET picks an appropriate bucket size to generate the target number of
buckets or fewer. For example, asking for at most 20 buckets over a year results
in monthly buckets:
FROM employees | WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z" | EVAL month = AUTO_BUCKET(hire_date, 20, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z") | KEEP hire_date, month | SORT hire_date
| hire_date:date | month:date |
|---|---|
1985-02-18T00:00:00.000Z |
1985-02-01T00:00:00.000Z |
1985-02-24T00:00:00.000Z |
1985-02-01T00:00:00.000Z |
1985-05-13T00:00:00.000Z |
1985-05-01T00:00:00.000Z |
1985-07-09T00:00:00.000Z |
1985-07-01T00:00:00.000Z |
1985-09-17T00:00:00.000Z |
1985-09-01T00:00:00.000Z |
1985-10-14T00:00:00.000Z |
1985-10-01T00:00:00.000Z |
1985-10-20T00:00:00.000Z |
1985-10-01T00:00:00.000Z |
1985-11-19T00:00:00.000Z |
1985-11-01T00:00:00.000Z |
1985-11-20T00:00:00.000Z |
1985-11-01T00:00:00.000Z |
1985-11-20T00:00:00.000Z |
1985-11-01T00:00:00.000Z |
1985-11-21T00:00:00.000Z |
1985-11-01T00:00:00.000Z |
The goal isn’t to provide exactly the target number of buckets, it’s to pick a range that people are comfortable with that provides at most the target number of buckets.
Combine AUTO_BUCKET with
STATS ... BY to create a histogram:
FROM employees | WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z" | EVAL month = AUTO_BUCKET(hire_date, 20, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z") | STATS hires_per_month = COUNT(*) BY month | SORT month
| hires_per_month:long | month:date |
|---|---|
2 |
1985-02-01T00:00:00.000Z |
1 |
1985-05-01T00:00:00.000Z |
1 |
1985-07-01T00:00:00.000Z |
1 |
1985-09-01T00:00:00.000Z |
2 |
1985-10-01T00:00:00.000Z |
4 |
1985-11-01T00:00:00.000Z |
AUTO_BUCKET does not create buckets that don’t match any documents.
That’s why this example is missing 1985-03-01 and other dates.
Asking for more buckets can result in a smaller range. For example, asking for at most 100 buckets in a year results in weekly buckets:
FROM employees | WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z" | EVAL week = AUTO_BUCKET(hire_date, 100, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z") | STATS hires_per_week = COUNT(*) BY week | SORT week
| hires_per_week:long | week:date |
|---|---|
2 |
1985-02-18T00:00:00.000Z |
1 |
1985-05-13T00:00:00.000Z |
1 |
1985-07-08T00:00:00.000Z |
1 |
1985-09-16T00:00:00.000Z |
2 |
1985-10-14T00:00:00.000Z |
4 |
1985-11-18T00:00:00.000Z |
AUTO_BUCKET does not filter any rows. It only uses the provided range to
pick a good bucket size. For rows with a value outside of the range, it returns
a bucket value that corresponds to a bucket outside the range. Combine
AUTO_BUCKET with WHERE to filter rows.
AUTO_BUCKET can also operate on numeric fields. For example, to create a
salary histogram:
FROM employees | EVAL bs = AUTO_BUCKET(salary, 20, 25324, 74999) | STATS COUNT(*) by bs | SORT bs
| COUNT(*):long | bs:double |
|---|---|
9 |
25000.0 |
9 |
30000.0 |
18 |
35000.0 |
11 |
40000.0 |
11 |
45000.0 |
10 |
50000.0 |
7 |
55000.0 |
9 |
60000.0 |
8 |
65000.0 |
8 |
70000.0 |
Unlike the earlier example that intentionally filters on a date range, you
rarely want to filter on a numeric range. You have to find the min and max
separately. ES|QL doesn’t yet have an easy way to do that automatically.
Examples
Create hourly buckets for the last 24 hours, and calculate the number of events per hour:
FROM sample_data | WHERE @timestamp >= NOW() - 1 day and @timestamp < NOW() | EVAL bucket = AUTO_BUCKET(@timestamp, 25, NOW() - 1 day, NOW()) | STATS COUNT(*) BY bucket
Create monthly buckets for the year 1985, and calculate the average salary by hiring month:
FROM employees | WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z" | EVAL bucket = AUTO_BUCKET(hire_date, 20, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z") | STATS AVG(salary) BY bucket | SORT bucket
| AVG(salary):double | bucket:date |
|---|---|
46305.0 |
1985-02-01T00:00:00.000Z |
44817.0 |
1985-05-01T00:00:00.000Z |
62405.0 |
1985-07-01T00:00:00.000Z |
49095.0 |
1985-09-01T00:00:00.000Z |
51532.0 |
1985-10-01T00:00:00.000Z |
54539.75 |
1985-11-01T00:00:00.000Z |
DATE_DIFF
editSyntax
Parameters
-
unit - Time difference unit.
-
startTimestamp - Start timestamp.
-
endTimestamp - End timestamp.
Description
Subtracts the startTimestamp from the endTimestamp and returns the
difference in multiples of unit. If startTimestamp is later than the
endTimestamp, negative values are returned.
| Datetime difference units | |
|---|---|
unit |
abbreviations |
year |
years, yy, yyyy |
quarter |
quarters, qq, q |
month |
months, mm, m |
dayofyear |
dy, y |
day |
days, dd, d |
week |
weeks, wk, ww |
weekday |
weekdays, dw |
hour |
hours, hh |
minute |
minutes, mi, n |
second |
seconds, ss, s |
millisecond |
milliseconds, ms |
microsecond |
microseconds, mcs |
nanosecond |
nanoseconds, ns |
Supported types
| unit | startTimestamp | endTimestamp | result |
|---|---|---|---|
keyword |
datetime |
datetime |
integer |
text |
datetime |
datetime |
integer |
Example
ROW date1 = TO_DATETIME("2023-12-02T11:00:00.000Z"), date2 = TO_DATETIME("2023-12-02T11:00:00.001Z")
| EVAL dd_ms = DATE_DIFF("microseconds", date1, date2)
| date1:date | date2:date | dd_ms:integer |
|---|---|---|
2023-12-02T11:00:00.000Z |
2023-12-02T11:00:00.001Z |
1000 |
DATE_EXTRACT
editSyntax
DATE_EXTRACT(date_part, date)
Parameters
-
date_part -
Part of the date to extract. Can be:
aligned_day_of_week_in_month,aligned_day_of_week_in_year,aligned_week_of_month,aligned_week_of_year,ampm_of_day,clock_hour_of_ampm,clock_hour_of_day,day_of_month,day_of_week,day_of_year,epoch_day,era,hour_of_ampm,hour_of_day,instant_seconds,micro_of_day,micro_of_second,milli_of_day,milli_of_second,minute_of_day,minute_of_hour,month_of_year,nano_of_day,nano_of_second,offset_seconds,proleptic_month,second_of_day,second_of_minute,year, oryear_of_era. Refer to java.time.temporal.ChronoField for a description of these values.If
null, the function returnsnull. -
date -
Date expression. If
null, the function returnsnull.
Description
Extracts parts of a date, like year, month, day, hour.
Examples
ROW date = DATE_PARSE("yyyy-MM-dd", "2022-05-06")
| EVAL year = DATE_EXTRACT("year", date)
| date:date | year:long |
|---|---|
2022-05-06T00:00:00.000Z |
2022 |
Find all events that occurred outside of business hours (before 9 AM or after 5 PM), on any given date:
FROM sample_data
| WHERE DATE_EXTRACT("hour_of_day", @timestamp) < 9 AND DATE_EXTRACT("hour_of_day", @timestamp) >= 17
| @timestamp:date | client_ip:ip | event_duration:long | message:keyword |
|---|
DATE_FORMAT
editSyntax
DATE_FORMAT([format,] date)
Parameters
-
format -
Date format (optional). If no format is specified, the
yyyy-MM-dd'T'HH:mm:ss.SSSZformat is used. Ifnull, the function returnsnull. -
date -
Date expression. If
null, the function returnsnull.
Description
Returns a string representation of a date, in the provided format.
Example
FROM employees
| KEEP first_name, last_name, hire_date
| EVAL hired = DATE_FORMAT("YYYY-MM-dd", hire_date)
| first_name:keyword | last_name:keyword | hire_date:date | hired:keyword |
|---|---|---|---|
Alejandro |
McAlpine |
1991-06-26T00:00:00.000Z |
1991-06-26 |
Amabile |
Gomatam |
1992-11-18T00:00:00.000Z |
1992-11-18 |
Anneke |
Preusig |
1989-06-02T00:00:00.000Z |
1989-06-02 |
DATE_PARSE
editSyntax
DATE_PARSE([format,] date_string)
Parameters
-
format -
The date format. Refer to the
DateTimeFormatterdocumentation for the syntax. Ifnull, the function returnsnull. -
date_string -
Date expression as a string. If
nullor an empty string, the function returnsnull.
Description
Returns a date by parsing the second argument using the format specified in the first argument.
Example
ROW date_string = "2022-05-06"
| EVAL date = DATE_PARSE("yyyy-MM-dd", date_string)
| date_string:keyword | date:date |
|---|---|
2022-05-06 |
2022-05-06T00:00:00.000Z |
DATE_TRUNC
editSyntax
DATE_TRUNC(interval, date)
Parameters
-
interval -
Interval, expressed using the timespan literal
syntax. If
null, the function returnsnull. -
date -
Date expression. If
null, the function returnsnull.
Description
Rounds down a date to the closest interval.
Examples
FROM employees | KEEP first_name, last_name, hire_date | EVAL year_hired = DATE_TRUNC(1 year, hire_date)
| first_name:keyword | last_name:keyword | hire_date:date | year_hired:date |
|---|---|---|---|
Alejandro |
McAlpine |
1991-06-26T00:00:00.000Z |
1991-01-01T00:00:00.000Z |
Amabile |
Gomatam |
1992-11-18T00:00:00.000Z |
1992-01-01T00:00:00.000Z |
Anneke |
Preusig |
1989-06-02T00:00:00.000Z |
1989-01-01T00:00:00.000Z |
Combine DATE_TRUNC with STATS ... BY to create date histograms. For
example, the number of hires per year:
FROM employees | EVAL year = DATE_TRUNC(1 year, hire_date) | STATS hires = COUNT(emp_no) BY year | SORT year
| hires:long | year:date |
|---|---|
11 |
1985-01-01T00:00:00.000Z |
11 |
1986-01-01T00:00:00.000Z |
15 |
1987-01-01T00:00:00.000Z |
9 |
1988-01-01T00:00:00.000Z |
13 |
1989-01-01T00:00:00.000Z |
12 |
1990-01-01T00:00:00.000Z |
6 |
1991-01-01T00:00:00.000Z |
8 |
1992-01-01T00:00:00.000Z |
3 |
1993-01-01T00:00:00.000Z |
4 |
1994-01-01T00:00:00.000Z |
5 |
1995-01-01T00:00:00.000Z |
1 |
1996-01-01T00:00:00.000Z |
1 |
1997-01-01T00:00:00.000Z |
1 |
1999-01-01T00:00:00.000Z |
Or an hourly error rate:
FROM sample_data | EVAL error = CASE(message LIKE "*error*", 1, 0) | EVAL hour = DATE_TRUNC(1 hour, @timestamp) | STATS error_rate = AVG(error) by hour | SORT hour
| error_rate:double | hour:date |
|---|---|
0.0 |
2023-10-23T12:00:00.000Z |
0.6 |
2023-10-23T13:00:00.000Z |
NOW
editSyntax
NOW()
Description
Returns current date and time.
Example
ROW current_date = NOW()
To retrieve logs from the last hour:
FROM sample_data | WHERE @timestamp > NOW() - 1 hour
ES|QL type conversion functions
editES|QL supports these type conversion functions:
-
TO_BOOLEAN -
TO_CARTESIANPOINT -
TO_CARTESIANSHAPE -
TO_DATETIME -
TO_DEGREES -
TO_DOUBLE -
TO_GEOPOINT -
TO_GEOSHAPE -
TO_INTEGER -
TO_IP -
TO_LONG -
TO_RADIANS -
TO_STRING -
[preview]
This functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
TO_UNSIGNED_LONG -
TO_VERSION
TO_BOOLEAN
editAlias
TO_BOOL
Syntax
TO_BOOLEAN(v)
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts an input value to a boolean value.
A string value of "true" will be case-insensitive converted to the Boolean true. For anything else, including the empty string, the function will return false.
The numerical value of 0 will be converted to false, anything else will be converted to true.
Supported types
The input type must be of a string or numeric type.
Example
ROW str = ["true", "TRuE", "false", "", "yes", "1"] | EVAL bool = TO_BOOLEAN(str)
| str:keyword | bool:boolean |
|---|---|
["true", "TRuE", "false", "", "yes", "1"] |
[true, true, false, false, false, false] |
TO_CARTESIANPOINT
editSyntax
TO_CARTESIANPOINT(v)
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts an input value to a point value.
A string will only be successfully converted if it respects the WKT Point format.
Supported types
| v | result |
|---|---|
cartesian_point |
cartesian_point |
keyword |
cartesian_point |
text |
cartesian_point |
Example
ROW wkt = ["POINT(4297.11 -1475.53)", "POINT(7580.93 2272.77)"] | MV_EXPAND wkt | EVAL pt = TO_CARTESIANPOINT(wkt)
| wkt:keyword | pt:cartesian_point |
|---|---|
"POINT(4297.11 -1475.53)" |
POINT(4297.11 -1475.53) |
"POINT(7580.93 2272.77)" |
POINT(7580.93 2272.77) |
TO_CARTESIANSHAPE
editSyntax
TO_CARTESIANSHAPE(v)
Parameters
-
v -
Input value. The input can be a single- or multi-valued column or an expression.
The input type must be a string, a
cartesian_shapeor acartesian_point.
Description
Converts an input value to a cartesian_shape value.
A string will only be successfully converted if it respects the WKT format.
Supported types
| v | result |
|---|---|
cartesian_point |
cartesian_shape |
cartesian_shape |
cartesian_shape |
keyword |
cartesian_shape |
text |
cartesian_shape |
Example
ROW wkt = ["POINT(4297.11 -1475.53)", "POLYGON ((3339584.72 1118889.97, 4452779.63 4865942.27, 2226389.81 4865942.27, 1113194.90 2273030.92, 3339584.72 1118889.97))"] | MV_EXPAND wkt | EVAL geom = TO_CARTESIANSHAPE(wkt)
| wkt:keyword | geom:cartesian_shape |
|---|---|
"POINT(4297.11 -1475.53)" |
POINT(4297.11 -1475.53) |
"POLYGON 3339584.72 1118889.97, 4452779.63 4865942.27, 2226389.81 4865942.27, 1113194.90 2273030.92, 3339584.72 1118889.97" |
POLYGON 3339584.72 1118889.97, 4452779.63 4865942.27, 2226389.81 4865942.27, 1113194.90 2273030.92, 3339584.72 1118889.97 |
TO_DATETIME
editAlias
TO_DT
Syntax
TO_DATETIME(v)
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts an input value to a date value.
A string will only be successfully converted if it’s respecting the format
yyyy-MM-dd'T'HH:mm:ss.SSS'Z'. To convert dates in other formats, use
DATE_PARSE.
Supported types
The input type must be of a string or numeric type.
Examples
ROW string = ["1953-09-02T00:00:00.000Z", "1964-06-02T00:00:00.000Z", "1964-06-02 00:00:00"] | EVAL datetime = TO_DATETIME(string)
| string:keyword | datetime:date |
|---|---|
["1953-09-02T00:00:00.000Z", "1964-06-02T00:00:00.000Z", "1964-06-02 00:00:00"] |
[1953-09-02T00:00:00.000Z, 1964-06-02T00:00:00.000Z] |
Note that in this example, the last value in the source multi-valued field has not been converted. The reason being that if the date format is not respected, the conversion will result in a null value. When this happens a Warning header is added to the response. The header will provide information on the source of the failure:
"Line 1:112: evaluation of [TO_DATETIME(string)] failed, treating result as null. Only first 20 failures recorded."
A following header will contain the failure reason and the offending value:
"java.lang.IllegalArgumentException: failed to parse date field [1964-06-02 00:00:00] with format [yyyy-MM-dd'T'HH:mm:ss.SSS'Z']"
If the input parameter is of a numeric type, its value will be interpreted as milliseconds since the Unix epoch. For example:
ROW int = [0, 1] | EVAL dt = TO_DATETIME(int)
| int:integer | dt:date |
|---|---|
[0, 1] |
[1970-01-01T00:00:00.000Z, 1970-01-01T00:00:00.001Z] |
TO_DEGREES
editSyntax
TO_DEGREES(v)
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts a number in radians to degrees.
Supported types
The input type must be of a numeric type and result is always double.
Example
ROW rad = [1.57, 3.14, 4.71] | EVAL deg = TO_DEGREES(rad)
| rad:double | deg:double |
|---|---|
[1.57, 3.14, 4.71] |
[89.95437383553924, 179.9087476710785, 269.86312150661774] |
TO_DOUBLE
editAlias
TO_DBL
Syntax
TO_DOUBLE(v)
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts an input value to a double value.
If the input parameter is of a date type, its value will be interpreted as milliseconds since the Unix epoch, converted to double.
Boolean true will be converted to double 1.0, false to 0.0.
Supported types
The input type must be of a boolean, date, string or numeric type.
Example
ROW str1 = "5.20128E11", str2 = "foo"
| EVAL dbl = TO_DOUBLE("520128000000"), dbl1 = TO_DOUBLE(str1), dbl2 = TO_DOUBLE(str2)
| str1:keyword | str2:keyword | dbl:double | dbl1:double | dbl2:double |
|---|---|---|---|---|
5.20128E11 |
foo |
5.20128E11 |
5.20128E11 |
null |
Note that in this example, the last conversion of the string isn’t possible. When this happens, the result is a null value. In this case a Warning header is added to the response. The header will provide information on the source of the failure:
"Line 1:115: evaluation of [TO_DOUBLE(str2)] failed, treating result as null. Only first 20 failures recorded."
A following header will contain the failure reason and the offending value:
"java.lang.NumberFormatException: For input string: \"foo\""
TO_GEOPOINT
editSyntax
TO_GEOPOINT(v)
Parameters
-
v -
Input value. The input can be a single- or multi-valued column or an expression.
The input type must be a string or a
geo_point.
Description
Converts an input value to a geo_point value.
Supported types
| v | result |
|---|---|
geo_point |
geo_point |
keyword |
geo_point |
text |
geo_point |
A string will only be successfully converted if it respects the WKT Point format.
Example
ROW wkt = "POINT(42.97109630194 14.7552534413725)" | EVAL pt = TO_GEOPOINT(wkt)
| wkt:keyword | pt:geo_point |
|---|---|
"POINT(42.97109630194 14.7552534413725)" |
POINT(42.97109630194 14.7552534413725) |
TO_GEOSHAPE
editSyntax
TO_GEOPOINT(v)
Parameters
-
v -
Input value. The input can be a single- or multi-valued column or an expression.
The input type must be a string, a
geo_shapeor ageo_point.
Description
Converts an input value to a geo_shape value.
A string will only be successfully converted if it respects the WKT format.
Supported types
| v | result |
|---|---|
geo_point |
geo_shape |
geo_shape |
geo_shape |
keyword |
geo_shape |
text |
geo_shape |
Example
ROW wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))" | EVAL geom = TO_GEOSHAPE(wkt)
| wkt:keyword | geom:geo_shape |
|---|---|
"POLYGON 30 10, 40 40, 20 40, 10 20, 30 10" |
POLYGON 30 10, 40 40, 20 40, 10 20, 30 10 |
TO_INTEGER
editAlias
TO_INT
Syntax
TO_INTEGER(v)
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts an input value to an integer value.
If the input parameter is of a date type, its value will be interpreted as milliseconds since the Unix epoch, converted to integer.
Boolean true will be converted to integer 1, false to 0.
Supported types
The input type must be of a boolean, date, string or numeric type.
Example
ROW long = [5013792, 2147483647, 501379200000] | EVAL int = TO_INTEGER(long)
| long:long | int:integer |
|---|---|
[5013792, 2147483647, 501379200000] |
[5013792, 2147483647] |
Note that in this example, the last value of the multi-valued field cannot be converted as an integer. When this happens, the result is a null value. In this case a Warning header is added to the response. The header will provide information on the source of the failure:
"Line 1:61: evaluation of [TO_INTEGER(long)] failed, treating result as null. Only first 20 failures recorded."
A following header will contain the failure reason and the offending value:
"org.elasticsearch.xpack.ql.InvalidArgumentException: [501379200000] out of [integer] range"
TO_IP
editSyntax
TO_IP(v)
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts an input string to an IP value.
Example
ROW str1 = "1.1.1.1", str2 = "foo" | EVAL ip1 = TO_IP(str1), ip2 = TO_IP(str2) | WHERE CIDR_MATCH(ip1, "1.0.0.0/8")
| str1:keyword | str2:keyword | ip1:ip | ip2:ip |
|---|---|---|---|
1.1.1.1 |
foo |
1.1.1.1 |
null |
Note that in this example, the last conversion of the string isn’t possible. When this happens, the result is a null value. In this case a Warning header is added to the response. The header will provide information on the source of the failure:
"Line 1:68: evaluation of [TO_IP(str2)] failed, treating result as null. Only first 20 failures recorded."
A following header will contain the failure reason and the offending value:
"java.lang.IllegalArgumentException: 'foo' is not an IP string literal."
TO_LONG
editSyntax
TO_LONG(v)
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts an input value to a long value.
If the input parameter is of a date type, its value will be interpreted as milliseconds since the Unix epoch, converted to long.
Boolean true will be converted to long 1, false to 0.
Supported types
The input type must be of a boolean, date, string or numeric type.
Example
ROW str1 = "2147483648", str2 = "2147483648.2", str3 = "foo" | EVAL long1 = TO_LONG(str1), long2 = TO_LONG(str2), long3 = TO_LONG(str3)
| str1:keyword | str2:keyword | str3:keyword | long1:long | long2:long | long3:long |
|---|---|---|---|---|---|
2147483648 |
2147483648.2 |
foo |
2147483648 |
2147483648 |
null |
Note that in this example, the last conversion of the string isn’t possible. When this happens, the result is a null value. In this case a Warning header is added to the response. The header will provide information on the source of the failure:
"Line 1:113: evaluation of [TO_LONG(str3)] failed, treating result as null. Only first 20 failures recorded."
A following header will contain the failure reason and the offending value:
"java.lang.NumberFormatException: For input string: \"foo\""
TO_RADIANS
editSyntax
TO_RADIANS(v)
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts a number in degrees to radians.
Supported types
The input type must be of a numeric type and result is always double.
Example
ROW deg = [90.0, 180.0, 270.0] | EVAL rad = TO_RADIANS(deg)
| deg:double | rad:double |
|---|---|
[90.0, 180.0, 270.0] |
[1.5707963267948966, 3.141592653589793, 4.71238898038469] |
TO_STRING
editAlias
TO_STR
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts an input value into a string.
Supported types
| v | result |
|---|---|
boolean |
keyword |
cartesian_point |
keyword |
cartesian_shape |
keyword |
datetime |
keyword |
double |
keyword |
geo_point |
keyword |
geo_shape |
keyword |
integer |
keyword |
ip |
keyword |
keyword |
keyword |
long |
keyword |
text |
keyword |
unsigned_long |
keyword |
version |
keyword |
Example
ROW a=10 | EVAL j = TO_STRING(a)
| a:integer | j:keyword |
|---|---|
10 |
"10" |
It also works fine on multivalued fields:
ROW a=[10, 9, 8] | EVAL j = TO_STRING(a)
| a:integer | j:keyword |
|---|---|
[10, 9, 8] |
["10", "9", "8"] |
TO_UNSIGNED_LONG
editThis functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
Aliases
TO_ULONG, TO_UL
Syntax
TO_UNSIGNED_LONG(v)
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts an input value to an unsigned long value.
Supported types
The input type must be of a boolean, date, string or numeric type.
If the input parameter is of a date type, its value will be interpreted as milliseconds since the Unix epoch, converted to unsigned long.
Boolean true will be converted to unsigned long 1, false to 0.
Example
ROW str1 = "2147483648", str2 = "2147483648.2", str3 = "foo" | EVAL long1 = TO_UNSIGNED_LONG(str1), long2 = TO_ULONG(str2), long3 = TO_UL(str3)
| str1:keyword | str2:keyword | str3:keyword | long1:unsigned_long | long2:unsigned_long | long3:unsigned_long |
|---|---|---|---|---|---|
2147483648 |
2147483648.2 |
foo |
2147483648 |
2147483648 |
null |
Note that in this example, the last conversion of the string isn’t possible. When this happens, the result is a null value. In this case a Warning header is added to the response. The header will provide information on the source of the failure:
"Line 1:133: evaluation of [TO_UL(str3)] failed, treating result as null. Only first 20 failures recorded."
A following header will contain the failure reason and the offending value:
"java.lang.NumberFormatException: Character f is neither a decimal digit number, decimal point, nor \"e\" notation exponential mark."
TO_VERSION
editAlias
TO_VER
Syntax
Parameters
-
v - Input value. The input can be a single- or multi-valued column or an expression.
Description
Converts an input string to a version value.
Supported types
| v | result |
|---|---|
keyword |
version |
text |
version |
version |
version |
Example
ROW v = TO_VERSION("1.2.3")
| v:version |
|---|
1.2.3 |
ES|QL conditional functions and expressions
editConditional functions return one of their arguments by evaluating in an if-else manner. ES|QL supports these conditional functions:
CASE
editSyntax
CASE(condition1, value1[, ..., conditionN, valueN][, default_value])
Parameters
-
conditionX - A condition.
-
valueX -
The value that’s returned when the corresponding condition is the first to
evaluate to
true. -
default_value - The default value that’s is returned when no condition matches.
Description
Accepts pairs of conditions and values. The function returns the value that
belongs to the first condition that evaluates to true.
If the number of arguments is odd, the last argument is the default value which
is returned when no condition matches. If the number of arguments is even, and
no condition matches, the function returns null.
Example
Determine whether employees are monolingual, bilingual, or polyglot:
FROM employees
| EVAL type = CASE(
languages <= 1, "monolingual",
languages <= 2, "bilingual",
"polyglot")
| KEEP emp_no, languages, type
| emp_no:integer | languages:integer | type:keyword |
|---|---|---|
10001 |
2 |
bilingual |
10002 |
5 |
polyglot |
10003 |
4 |
polyglot |
10004 |
5 |
polyglot |
10005 |
1 |
monolingual |
Calculate the total connection success rate based on log messages:
FROM sample_data
| EVAL successful = CASE(
STARTS_WITH(message, "Connected to"), 1,
message == "Connection error", 0
)
| STATS success_rate = AVG(successful)
| success_rate:double |
|---|
0.5 |
Calculate an hourly error rate as a percentage of the total number of log messages:
FROM sample_data | EVAL error = CASE(message LIKE "*error*", 1, 0) | EVAL hour = DATE_TRUNC(1 hour, @timestamp) | STATS error_rate = AVG(error) by hour | SORT hour
| error_rate:double | hour:date |
|---|---|
0.0 |
2023-10-23T12:00:00.000Z |
0.6 |
2023-10-23T13:00:00.000Z |
COALESCE
editSyntax
COALESCE(expression1 [, ..., expressionN])
Parameters
-
expressionX - Expression to evaluate.
Description
Returns the first of its arguments that is not null. If all arguments are null,
it returns null.
Example
ROW a=null, b="b" | EVAL COALESCE(a, b)
| a:null | b:keyword | COALESCE(a, b):keyword |
|---|---|---|
null |
b |
b |
GREATEST
editSyntax
Parameters
-
first - First of the columns to evaluate.
-
rest - The rest of the columns to evaluate.
Description
Returns the maximum value from multiple columns. This is similar to MV_MAX
except it is intended to run on multiple columns at once.
When run on keyword or text fields, this returns the last string
in alphabetical order. When run on boolean columns this will return
true if any values are true.
Supported types
| first | rest | result |
|---|---|---|
boolean |
boolean |
boolean |
double |
double |
double |
integer |
integer |
integer |
ip |
ip |
ip |
keyword |
keyword |
keyword |
long |
long |
long |
text |
text |
text |
version |
version |
version |
Example
ROW a = 10, b = 20 | EVAL g = GREATEST(a, b)
| a:integer | b:integer | g:integer |
|---|---|---|
10 |
20 |
20 |
LEAST
editSyntax
Parameters
-
first - First of the columns to evaluate.
-
rest - The rest of the columns to evaluate.
Description
Returns the minimum value from multiple columns. This is similar to
MV_MIN except it is intended to run on multiple columns at once.
When run on keyword or text fields, this returns the first string
in alphabetical order. When run on boolean columns this will return
false if any values are false.
Supported types
| first | rest | result |
|---|---|---|
boolean |
boolean |
boolean |
double |
double |
double |
integer |
integer |
integer |
ip |
ip |
ip |
keyword |
keyword |
keyword |
long |
long |
long |
text |
text |
text |
version |
version |
version |
Example
ROW a = 10, b = 20 | EVAL l = LEAST(a, b)
| a:integer | b:integer | l:integer |
|---|---|---|
10 |
20 |
10 |
ES|QL multivalue functions
editES|QL supports these multivalue functions:
MV_AVG
editSyntax
MV_AVG(expression)
Parameters
-
expression - Multivalue expression.
Description
Converts a multivalued expression into a single valued column containing the average of all of the values.
Supported types
| field | result |
|---|---|
double |
double |
integer |
double |
long |
double |
unsigned_long |
double |
Example
ROW a=[3, 5, 1, 6] | EVAL avg_a = MV_AVG(a)
| a:integer | avg_a:double |
|---|---|
[3, 5, 1, 6] |
3.75 |
MV_CONCAT
editSyntax
Parameters
-
v - Multivalue expression.
-
delim - Delimiter.
Description
Converts a multivalued string expression into a single valued column containing the concatenation of all values separated by a delimiter.
Supported types
| v | delim | result |
|---|---|---|
keyword |
keyword |
keyword |
keyword |
text |
keyword |
text |
keyword |
keyword |
text |
text |
keyword |
Examples
ROW a=["foo", "zoo", "bar"] | EVAL j = MV_CONCAT(a, ", ")
| a:keyword | j:keyword |
|---|---|
["foo", "zoo", "bar"] |
"foo, zoo, bar" |
To concat non-string columns, call TO_STRING first:
ROW a=[10, 9, 8] | EVAL j = MV_CONCAT(TO_STRING(a), ", ")
| a:integer | j:keyword |
|---|---|
[10, 9, 8] |
"10, 9, 8" |
MV_COUNT
editSyntax
Parameters
-
v - Multivalue expression.
Description
Converts a multivalued expression into a single valued column containing a count of the number of values.
Supported types
| v | result |
|---|---|
boolean |
integer |
cartesian_point |
integer |
cartesian_shape |
integer |
datetime |
integer |
double |
integer |
geo_point |
integer |
geo_shape |
integer |
integer |
integer |
ip |
integer |
keyword |
integer |
long |
integer |
text |
integer |
unsigned_long |
integer |
version |
integer |
Example
ROW a=["foo", "zoo", "bar"] | EVAL count_a = MV_COUNT(a)
| a:keyword | count_a:integer |
|---|---|
["foo", "zoo", "bar"] |
3 |
MV_DEDUPE
editSyntax
Parameters
-
v - Multivalue expression.
Description
Removes duplicates from a multivalue expression.
MV_DEDUPE may, but won’t always, sort the values in the column.
Supported types
| v | result |
|---|---|
boolean |
boolean |
datetime |
datetime |
double |
double |
integer |
integer |
ip |
ip |
keyword |
keyword |
long |
long |
text |
text |
version |
version |
Example
ROW a=["foo", "foo", "bar", "foo"] | EVAL dedupe_a = MV_DEDUPE(a)
| a:keyword | dedupe_a:keyword |
|---|---|
["foo", "foo", "bar", "foo"] |
["foo", "bar"] |
MV_FIRST
editSyntax
Parameters
-
v - Multivalue expression.
Description
Converts a multivalued expression into a single valued column containing the
first value. This is most useful when reading from a function that emits
multivalued columns in a known order like SPLIT.
The order that multivalued fields are read from
underlying storage is not guaranteed. It is frequently ascending, but don’t
rely on that. If you need the minimum value use MV_MIN instead of
MV_FIRST. MV_MIN has optimizations for sorted values so there isn’t a
performance benefit to MV_FIRST.
Supported types
| v | result |
|---|---|
boolean |
boolean |
cartesian_point |
cartesian_point |
cartesian_shape |
cartesian_shape |
datetime |
datetime |
double |
double |
geo_point |
geo_point |
geo_shape |
geo_shape |
integer |
integer |
ip |
ip |
keyword |
keyword |
long |
long |
text |
text |
unsigned_long |
unsigned_long |
version |
version |
Example
ROW a="foo;bar;baz" | EVAL first_a = MV_FIRST(SPLIT(a, ";"))
| a:keyword | first_a:keyword |
|---|---|
foo;bar;baz |
"foo" |
MV_LAST
editSyntax
Parameters
-
v - Multivalue expression.
Description
Converts a multivalue expression into a single valued column containing the last
value. This is most useful when reading from a function that emits multivalued
columns in a known order like SPLIT.
The order that multivalued fields are read from
underlying storage is not guaranteed. It is frequently ascending, but don’t
rely on that. If you need the maximum value use MV_MAX instead of
MV_LAST. MV_MAX has optimizations for sorted values so there isn’t a
performance benefit to MV_LAST.
Supported types
| v | result |
|---|---|
boolean |
boolean |
cartesian_point |
cartesian_point |
cartesian_shape |
cartesian_shape |
datetime |
datetime |
double |
double |
geo_point |
geo_point |
geo_shape |
geo_shape |
integer |
integer |
ip |
ip |
keyword |
keyword |
long |
long |
text |
text |
unsigned_long |
unsigned_long |
version |
version |
Example
ROW a="foo;bar;baz" | EVAL last_a = MV_LAST(SPLIT(a, ";"))
| a:keyword | last_a:keyword |
|---|---|
foo;bar;baz |
"baz" |
MV_MAX
editSyntax
Parameters
-
v - Multivalue expression.
Description
Converts a multivalued expression into a single valued column containing the maximum value.
Supported types
| v | result |
|---|---|
boolean |
boolean |
datetime |
datetime |
double |
double |
integer |
integer |
ip |
ip |
keyword |
keyword |
long |
long |
text |
text |
unsigned_long |
unsigned_long |
version |
version |
Examples
ROW a=[3, 5, 1] | EVAL max_a = MV_MAX(a)
| a:integer | max_a:integer |
|---|---|
[3, 5, 1] |
5 |
It can be used by any column type, including keyword columns. In that case
it picks the last string, comparing their utf-8 representation byte by byte:
ROW a=["foo", "zoo", "bar"] | EVAL max_a = MV_MAX(a)
| a:keyword | max_a:keyword |
|---|---|
["foo", "zoo", "bar"] |
"zoo" |
MV_MEDIAN
editMV_MEDIAN(v)
Parameters
-
v - Multivalue expression.
Description
Converts a multivalued column into a single valued column containing the median value.
Supported types
| v | result |
|---|---|
double |
double |
integer |
integer |
long |
long |
unsigned_long |
unsigned_long |
Examples
ROW a=[3, 5, 1] | EVAL median_a = MV_MEDIAN(a)
| a:integer | median_a:integer |
|---|---|
[3, 5, 1] |
3 |
If the row has an even number of values for a column, the result will be the average of the middle two entries. If the column is not floating point, the average rounds down:
ROW a=[3, 7, 1, 6] | EVAL median_a = MV_MEDIAN(a)
| a:integer | median_a:integer |
|---|---|
[3, 7, 1, 6] |
4 |
MV_MIN
editSyntax
Parameters
-
v - Multivalue expression.
Description
Converts a multivalued expression into a single valued column containing the minimum value.
Supported types
| v | result |
|---|---|
boolean |
boolean |
datetime |
datetime |
double |
double |
integer |
integer |
ip |
ip |
keyword |
keyword |
long |
long |
text |
text |
unsigned_long |
unsigned_long |
version |
version |
Examples
ROW a=[2, 1] | EVAL min_a = MV_MIN(a)
| a:integer | min_a:integer |
|---|---|
[2, 1] |
1 |
It can be used by any column type, including keyword columns. In that case,
it picks the first string, comparing their utf-8 representation byte by byte:
ROW a=["foo", "bar"] | EVAL min_a = MV_MIN(a)
| a:keyword | min_a:keyword |
|---|---|
["foo", "bar"] |
"bar" |
MV_SUM
editMV_SUM(v)
Parameters
-
v - Multivalue expression.
Description
Converts a multivalued column into a single valued column containing the sum of all of the values.
Supported types
| v | result |
|---|---|
double |
double |
integer |
integer |
long |
long |
unsigned_long |
unsigned_long |
Example
ROW a=[3, 5, 6] | EVAL sum_a = MV_SUM(a)
| a:integer | sum_a:integer |
|---|---|
[3, 5, 6] |
14 |
ES|QL operators
editBoolean operators for comparing against one or multiple expressions.
Binary operators
editAdd +
editSupported types:
| lhs | rhs | result |
|---|---|---|
date_period |
date_period |
date_period |
date_period |
datetime |
datetime |
datetime |
date_period |
datetime |
datetime |
time_duration |
datetime |
double |
double |
double |
double |
integer |
double |
double |
long |
double |
integer |
double |
double |
integer |
integer |
integer |
integer |
long |
long |
long |
double |
double |
long |
integer |
long |
long |
long |
long |
time_duration |
datetime |
datetime |
time_duration |
time_duration |
time_duration |
unsigned_long |
unsigned_long |
unsigned_long |
Subtract -
editSupported types:
| lhs | rhs | result |
|---|---|---|
date_period |
date_period |
date_period |
datetime |
date_period |
datetime |
datetime |
time_duration |
datetime |
double |
double |
double |
integer |
integer |
integer |
long |
long |
long |
time_duration |
time_duration |
time_duration |
unsigned_long |
unsigned_long |
unsigned_long |
Multiply *
editSupported types:
| lhs | rhs | result |
|---|---|---|
double |
double |
double |
integer |
integer |
integer |
long |
long |
long |
unsigned_long |
unsigned_long |
unsigned_long |
Divide /
editSupported types:
| lhs | rhs | result |
|---|---|---|
double |
double |
double |
integer |
integer |
integer |
long |
long |
long |
Modulus %
editSupported types:
| lhs | rhs | result |
|---|---|---|
double |
double |
double |
integer |
integer |
integer |
long |
long |
long |
Unary operators
editThe only unary operators is negation (-):
Supported types:
| v | result |
|---|---|
date_period |
date_period |
double |
double |
integer |
integer |
long |
long |
time_duration |
time_duration |
Logical operators
editThe following logical operators are supported:
-
AND -
OR -
NOT
IS NULL and IS NOT NULL predicates
editFor NULL comparison, use the IS NULL and IS NOT NULL predicates:
FROM employees | WHERE birth_date IS NULL | KEEP first_name, last_name | SORT first_name | LIMIT 3
| first_name:keyword | last_name:keyword |
|---|---|
Basil |
Tramer |
Florian |
Syrotiuk |
Lucien |
Rosenbaum |
FROM employees | WHERE is_rehired IS NOT NULL | STATS COUNT(emp_no)
| COUNT(emp_no):long |
|---|
84 |
CIDR_MATCH
editSyntax
CIDR_MATCH(ip, block1[, ..., blockN])
Parameters
-
ip -
IP address of type
ip(both IPv4 and IPv6 are supported). -
blockX - CIDR block to test the IP against.
Description
Returns true if the provided IP is contained in one of the provided CIDR
blocks.
Example
FROM hosts | WHERE CIDR_MATCH(ip1, "127.0.0.2/32", "127.0.0.3/32") | KEEP card, host, ip0, ip1
| card:keyword | host:keyword | ip0:ip | ip1:ip |
|---|---|---|---|
eth1 |
beta |
127.0.0.1 |
127.0.0.2 |
eth0 |
gamma |
fe80::cae2:65ff:fece:feb9 |
127.0.0.3 |
ENDS_WITH
editSyntax
Parameters
-
str -
String expression. If
null, the function returnsnull. -
suffix -
String expression. If
null, the function returnsnull.
Description
Returns a boolean that indicates whether a keyword string ends with another string.
Supported types
| str | suffix | result |
|---|---|---|
keyword |
keyword |
boolean |
text |
text |
boolean |
Example
FROM employees | KEEP last_name | EVAL ln_E = ENDS_WITH(last_name, "d")
| last_name:keyword | ln_E:boolean |
|---|---|
Awdeh |
false |
Azuma |
false |
Baek |
false |
Bamford |
true |
Bernatsky |
false |
IN
editThe IN operator allows testing whether a field or expression equals
an element in a list of literals, fields or expressions:
ROW a = 1, b = 4, c = 3 | WHERE c-a IN (3, b / 2, a)
| a:integer | b:integer | c:integer |
|---|---|---|
1 |
4 |
3 |
LIKE
editUse LIKE to filter data based on string patterns using wildcards. LIKE
usually acts on a field placed on the left-hand side of the operator, but it can
also act on a constant (literal) expression. The right-hand side of the operator
represents the pattern.
The following wildcard characters are supported:
-
*matches zero or more characters. -
?matches one character.
FROM employees | WHERE first_name LIKE "?b*" | KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
Ebbe |
Callaway |
Eberhardt |
Terkki |
RLIKE
editUse RLIKE to filter data based on string patterns using using
regular expressions. RLIKE usually acts on a field placed on
the left-hand side of the operator, but it can also act on a constant (literal)
expression. The right-hand side of the operator represents the pattern.
FROM employees | WHERE first_name RLIKE ".leja.*" | KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
Alejandro |
McAlpine |
STARTS_WITH
editSyntax
Parameters
-
str -
String expression. If
null, the function returnsnull. -
prefix -
String expression. If
null, the function returnsnull.
Description
Returns a boolean that indicates whether a keyword string starts with another string.
Supported types
| str | prefix | result |
|---|---|---|
keyword |
keyword |
boolean |
text |
text |
boolean |
Example
FROM employees | KEEP last_name | EVAL ln_S = STARTS_WITH(last_name, "B")
| last_name:keyword | ln_S:boolean |
|---|---|
Awdeh |
false |
Azuma |
false |
Baek |
true |
Bamford |
true |
Bernatsky |
true |