NOTE: You are looking at documentation for an older release. For the latest information, see the current release documentation.
Writing analyzers
editWriting analyzers
editThere are times when you would like to analyze text in a bespoke fashion, either by configuring how one of Elasticsearch’s built-in analyzers works, or by combining analysis components together to build a custom analyzer.
The analysis chain
editAn analyzer is built of three components:
- 0 or more character filters
- exactly 1 tokenizer
- 0 or more token filters
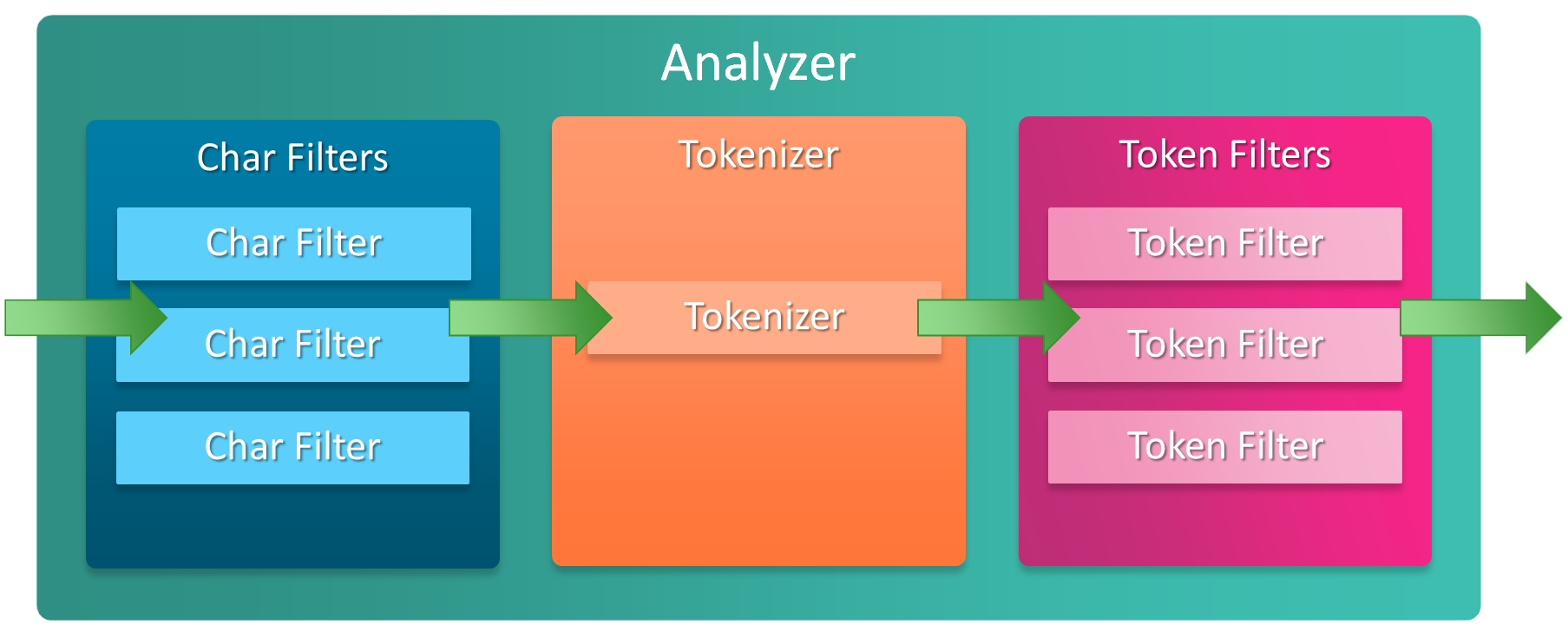
Check out the Elasticsearch documentation on the Anatomy of an analyzer to understand more.
Specifying an analyzer on a field mapping
editAn analyzer can be specified on a text datatype field mapping when creating a new field on a type, usually
when creating the type mapping at index creation time, but also when adding a new field
using the Put Mapping API.
Although you can add new types to an index, or add new fields to a type, you can’t add new analyzers or make changes to existing fields. If you were to do so, the data that has already been indexed would be incorrect and your searches would no longer work as expected.
When you need to make changes to existing fields, you should look at reindexing your data with the Reindex API
Here’s a simple example that specifies that the name field in Elasticsearch,
which maps to the Name POCO property on the Project type, uses the whitespace analyzer at index time
var createIndexResponse = _client.CreateIndex("my-index", c => c
.Mappings(m => m
.Map<Project>(mm => mm
.Properties(p => p
.Text(t => t
.Name(n => n.Name)
.Analyzer("whitespace")
)
)
)
)
);
Configuring a built-in analyzer
editSeveral built-in analyzers can be configured to alter their behaviour. For example, the
standard analyzer can be configured to support a list of stop words with the stop word token filter
it contains.
Configuring a built-in analyzer requires creating an analyzer based on the built-in one
var createIndexResponse = _client.CreateIndex("my-index", c => c
.Settings(s => s
.Analysis(a => a
.Analyzers(aa => aa
.Standard("standard_english", sa => sa
.StopWords("_english_")
)
)
)
)
.Mappings(m => m
.Map<Project>(mm => mm
.Properties(p => p
.Text(t => t
.Name(n => n.Name)
.Analyzer("standard_english")
)
)
)
)
);
|
Pre-defined list of English stopwords within Elasticsearch |
|
|
Use the |
{
"settings": {
"analysis": {
"analyzer": {
"standard_english": {
"type": "standard",
"stopwords": [
"_english_"
]
}
}
}
},
"mappings": {
"doc": {
"properties": {
"name": {
"type": "text",
"analyzer": "standard_english"
}
}
}
}
}
Creating a custom analyzer
editA custom analyzer can be composed when none of the built-in analyzers fit your needs. A custom analyzer
is built from the components that you saw in the analysis chain and a
position increment gap,
that determines the size of gap that Elasticsearch should insert between array elements, when a
field can hold multiple values e.g. a List<string> POCO property.
For this example, imagine we are indexing programming questions, where the question content is HTML and contains source code
public class Question
{
public int Id { get; set; }
public DateTimeOffset CreationDate { get; set; }
public int Score { get; set; }
public string Body { get; set; }
}
Based on our domain knowledge of programming languages, we would like to be able to search questions
that contain "C#", but using the standard analyzer, "C#" will be analyzed and produce the token
"c". This won’t work for our use case as there will be no way to distinguish questions about
"C#" from questions about another popular programming language, "C".
We can solve our issue with a custom analyzer
var createIndexResponse = _client.CreateIndex("questions", c => c
.Settings(s => s
.Analysis(a => a
.CharFilters(cf => cf
.Mapping("programming_language", mca => mca
.Mappings(new []
{
"c# => csharp",
"C# => Csharp"
})
)
)
.Analyzers(an => an
.Custom("question", ca => ca
.CharFilters("html_strip", "programming_language")
.Tokenizer("standard")
.Filters("standard", "lowercase", "stop")
)
)
)
)
.Mappings(m => m
.Map<Question>(mm => mm
.AutoMap()
.Properties(p => p
.Text(t => t
.Name(n => n.Body)
.Analyzer("question")
)
)
)
)
);
Our custom question analyzer will apply the following analysis to a question body
- strip HTML tags
-
map both
C#andc#to"CSharp"and"csharp", respectively (so the#is not stripped by the tokenizer) - tokenize using the standard tokenizer
- filter tokens with the standard token filter
- lowercase tokens
- remove stop word tokens
A full text query will also apply the same analysis to the query input against the
question body at search time, meaning when someone searches including the input "C#", it will also be
analyzed and produce the token "csharp", matching a question body that contains "C#" (as well as "csharp"
and case invariants), because the search time analysis applied is the same as the index time analysis.
Index and Search time analysis
editWith the previous example, we probably don’t want to apply the same analysis to the query input of a full text query against a question body; we know for our problem domain that a query input is not going to contain HTML tags, so we would like to apply different analysis at search time.
An analyzer can be specified when creating the field mapping to use at search time, in addition to an analyzer to use at query time
var createIndexResponse = _client.CreateIndex("questions", c => c
.Settings(s => s
.Analysis(a => a
.CharFilters(cf => cf
.Mapping("programming_language", mca => mca
.Mappings(new[]
{
"c# => csharp",
"C# => Csharp"
})
)
)
.Analyzers(an => an
.Custom("index_question", ca => ca
.CharFilters("html_strip", "programming_language")
.Tokenizer("standard")
.Filters("standard", "lowercase", "stop")
)
.Custom("search_question", ca => ca
.CharFilters("programming_language")
.Tokenizer("standard")
.Filters("standard", "lowercase", "stop")
)
)
)
)
.Mappings(m => m
.Map<Question>(mm => mm
.AutoMap()
.Properties(p => p
.Text(t => t
.Name(n => n.Body)
.Analyzer("index_question")
.SearchAnalyzer("search_question")
)
)
)
)
);
|
Use an analyzer at index time that strips HTML tags |
|
|
Use an analyzer at search time that does not strip HTML tags |
With this in place, the text of a question body will be analyzed with the index_question analyzer
at index time and the input to a full text query on the question body field will be analyzed with
the search_question analyzer that does not use the html_strip character filter.
A Search analyzer can also be specified per query i.e. use a different analyzer for a particular request from the one specified in the mapping. This can be useful when iterating on and improving your search strategy.
Take a look at the analyzer documentation for more details around where analyzers can be specified and the precedence for a given request.