WARNING: Version 5.5 of Filebeat has passed its EOL date.
This documentation is no longer being maintained and may be removed. If you are running this version, we strongly advise you to upgrade. For the latest information, see the current release documentation.
Filebeat Prospectors
editFilebeat Prospectors
editThe filebeat section of the filebeat.yml config file specifies a list of prospectors that Filebeat
uses to locate and process log files. Each prospector item begins with a dash (-)
and specifies prospector-specific configuration options, including
the list of paths that are crawled to locate log files.
Here is a sample configuration:
filebeat.prospectors:
- input_type: log
paths:
- /var/log/apache/httpd-*.log
document_type: apache
- input_type: log
paths:
- /var/log/messages
- /var/log/*.log
Options
editinput_type
editOne of the following input types:
- log: Reads every line of the log file (default)
- stdin: Reads the standard in
The value that you specify here is used as the input_type for each event published to Logstash and Elasticsearch.
paths
editA list of glob-based paths that should be crawled and fetched. All patterns
supported by Golang Glob are also
supported here. For example, to fetch all files from a predefined level of
subdirectories, the following pattern can be used: /var/log/*/*.log. This
fetches all .log files from the subfolders of /var/log. It does not
fetch log files from the /var/log folder itself. Currently it is not possible
to recursively fetch all files in all subdirectories of a directory.
Filebeat starts a harvester for each file that it finds under the specified paths. You can specify one path per line. Each line begins with a dash (-).
encoding
editThe file encoding to use for reading files that contain international characters. See the encoding names recommended by the W3C for use in HTML5.
Here are some sample encodings from W3C recommendation:
- plain, latin1, utf-8, utf-16be-bom, utf-16be, utf-16le, big5, gb18030, gbk, hz-gb-2312,
- euc-kr, euc-jp, iso-2022-jp, shift-jis, and so on
The plain encoding is special, because it does not validate or transform any input.
exclude_lines
editA list of regular expressions to match the lines that you want Filebeat to exclude. Filebeat drops any lines that match a regular expression in the list. By default, no lines are dropped.
If multiline is also specified, each multiline message is combined into a single line before the lines are filtered by exclude_lines.
The following example configures Filebeat to drop any lines that start with "DBG".
filebeat.prospectors:
- paths:
- /var/log/myapp/*.log
exclude_lines: ['^DBG']
See Regular Expression Support for a list of supported regexp patterns.
include_lines
editA list of regular expressions to match the lines that you want Filebeat to include. Filebeat exports only the lines that match a regular expression in the list. By default, all lines are exported.
If multiline is also specified, each multiline message is combined into a single line before the lines are filtered by include_lines.
The following example configures Filebeat to export any lines that start with "ERR" or "WARN":
filebeat.prospectors:
- paths:
- /var/log/myapp/*.log
include_lines: ['^ERR', '^WARN']
If both include_lines and exclude_lines are defined, Filebeat executes include_lines first and then executes exclude_lines.
The order in which the two options are defined doesn’t matter. The include_lines option will always be executed
before the exclude_lines option, even if exclude_lines appears before include_lines in the config file.
The following example exports all Apache log lines except the debugging messages (DBGs):
include_lines: ['apache'] exclude_lines: ['^DBG']
See Regular Expression Support for a list of supported regexp patterns.
exclude_files
editA list of regular expressions to match the files that you want Filebeat to ignore. By default no files are excluded.
The following example configures Filebeat to ignore all the files that have a gz extension:
exclude_files: ['\.gz$']
See Regular Expression Support for a list of supported regexp patterns.
tags
editA list of tags that the Beat includes in the tags field of each published
event. Tags make it easy to select specific events in Kibana or apply
conditional filtering in Logstash. These tags will be appended to the list of
tags specified in the general configuration.
Example:
filebeat.prospectors: - paths: ["/var/log/app/*.json"] tags: ["json"]
fields
editOptional fields that you can specify to add additional information to the
output. For example, you might add fields that you can use for filtering log
data. Fields can be scalar values, arrays, dictionaries, or any nested
combination of these. By default, the fields that you specify here will be
grouped under a fields sub-dictionary in the output document. To store the
custom fields as top-level fields, set the fields_under_root option to true.
If a duplicate field is declared in the general configuration, then its value
will be overwritten by the value declared here.
filebeat.prospectors:
- paths: ["/var/log/app/*.log"]
fields:
app_id: query_engine_12
fields_under_root
editIf this option is set to true, the custom fields are stored as
top-level fields in the output document instead of being grouped under a
fields sub-dictionary. If the custom field names conflict with other field
names added by Filebeat, then the custom fields overwrite the other fields.
ignore_older
editIf this option is enabled, Filebeat ignores any files that were modified before the specified timespan. Configuring ignore_older can be especially useful if you keep log files for a long time. For example, if you want to start Filebeat, but only want to send the newest files and files from last week, you can configure this option.
You can use time strings like 2h (2 hours) and 5m (5 minutes). The default is 0, which disables the setting. Commenting out the config has the same effect as setting it to 0.
You must set ignore_older to be greater than close_inactive.
The files affected by this setting fall into two categories:
- Files that were never harvested
-
Files that were harvested but weren’t updated for longer than
ignore_older
For files which were never seen before, the offset state is set to the end of the file. If a state already exist, the offset is not changed. In case a file is updated again later, reading continues at the set offset position.
The ignore_older setting relies on the modification time of the file to determine if a file is ignored. If the modification time of the file is not updated when lines are written to a file (which can happen on Windows), the ignore_older setting may cause Filebeat to ignore files even though content was added at a later time.
To remove the state of previously harvested files from the registry file, use the clean_inactive configuration option.
Before a file can be ignored by the prospector, it must be closed. To ensure a file is no longer being harvested when it is ignored, you must set ignore_older to a longer duration than close_inactive.
If a file that’s currently being harvested falls under ignore_older, the harvester will first finish reading the file and close it after close_inactive is reached. Then, after that, the file will be ignored.
close_*
editThe close_* configuration options are used to close the harvester after a certain criteria or time. Closing the harvester means closing the file handler. If a file is updated after the harvester is closed, the file will be picked up again after scan_frequency has elapsed. However, if the file is moved or deleted while the harvester is closed, Filebeat will not be able to pick up the file again, and any data that the harvester hasn’t read will be lost.
close_inactive
editWhen this option is enabled, Filebeat closes the file handle if a file has not been harvested for the specified duration. The counter for the defined period starts when the last log line was read by the harvester. It is not based on the modification time of the file. If the closed file changes again, a new harvester is started and the latest changes will be picked up after scan_frequency has elapsed.
We recommended that you set close_inactive to a value that is larger than the least frequent updates to your log files. For example, if your log files get updated every few seconds, you can safely set close_inactive to 1m. If there are log files with very different update rates, you can use multiple prospector configurations with different values.
Setting close_inactive to a lower value means that file handles are closed sooner. However this has the side effect that new log lines are not sent in near real time if the harvester is closed.
The timestamp for closing a file does not depend on the modification time of the file. Instead, Filebeat uses an internal timestamp that reflects when the file was last harvested. For example, if close_inactive is set to 5 minutes, the countdown for the 5 minutes starts after the harvester reads the last line of the file.
You can use time strings like 2h (2 hours) and 5m (5 minutes). The default is 5m.
close_renamed
editOnly use this option if you understand that data loss is a potential side effect.
When this option is enabled, Filebeat closes the file handler when a file is renamed. This happens, for example, when rotating files. By default, the harvester stays open and keeps reading the file because the file handler does not depend on the file name. If the close_renamed option is enabled and the file is renamed or moved in such a way that it’s no longer matched by the file patterns specified for the prospector, the file will not be picked up again. Filebeat will not finish reading the file.
WINDOWS: If your Windows log rotation system shows errors because it can’t rotate the files, you should enable this option.
close_removed
editWhen this option is enabled, Filebeat closes the harvester when a file is removed. Normally a file should only be removed after it’s inactive for the duration specified by close_inactive. However, if a file is removed early and you don’t enable close_removed, Filebeat keeps the file open to make sure the harvester has completed. If this setting results in files that are not completely read because they are removed from disk too early, disable this option.
This option is enabled by default. If you disable this option, you must also disable clean_removed.
WINDOWS: If your Windows log rotation system shows errors because it can’t rotate files, make sure this option is enabled.
close_eof
editOnly use this option if you understand that data loss is a potential side effect.
When this option is enabled, Filebeat closes a file as soon as the end of a file is reached. This is useful when your files are only written once and not updated from time to time. For example, this happens when you are writing every single log event to a new file. This option is disabled by default.
close_timeout
editOnly use this option if you understand that data loss is a potential side effect. Another side effect is that multiline events might not be completely sent before the timeout expires.
When this option is enabled, Filebeat gives every harvester a predefined lifetime. Regardless of where the reader is in the file, reading will stop after the close_timeout period has elapsed. This option can be useful for older log files when you want to spend only a predefined amount of time on the files. While close_timeout will close the file after the predefined timeout, if the file is still being updated, the prospector will start a new harvester again per the defined scan_frequency. And the close_timeout for this harvester will start again with the countdown for the timeout.
If you set close_timeout to equal ignore_older, the file will not be picked up if it’s modified while the harvester is closed. This combination of settings normally leads to data loss, and the complete file is not sent.
When you use close_timeout for logs that contain multiline events, the harvester might stop in the middle of a multiline event, which means that only parts of the event will be sent. If the harvester is started again and the file still exists, only the second part of the event will be sent.
The close_timeout setting won’t apply if your output is stalled and no further events can be sent. At least one event must be sent after close_timeout elapses so the harvester can be closed after sending the event.
This option is set to 0 by default which means it is disabled.
clean_*
editThe clean_* options are used to clean up the state entries in the registry file. These settings help to reduce the size of the registry file and can prevent a potential inode reuse issue.
clean_inactive
editOnly use this option if you understand that data loss is a potential side effect.
When this option is enabled, Filebeat removes the state of a file after the specified period of inactivity has elapsed. The state can only be removed if the file is already ignored by Filebeat (the file is older than ignore_older). The clean_inactive setting must be greater than ignore_older + scan_frequency to make sure that no states are removed while a file is still being harvested. Otherwise, the setting could result in Filebeat resending the full content constantly because clean_inactive removes state for files that are still detected by the prospector. If a file is updated or appears again, the file is read from the beginning.
The clean_inactive configuration option is useful to reduce the size of the registry file, especially if a large amount of new files are generated every day.
This config option is also useful to prevent Filebeat problems resulting from inode reuse on Linux. For more information, see Inode reuse causes Filebeat to skip lines?.
Every time a file is renamed, the file state is updated and the counter for clean_inactive starts at 0 again.
clean_removed
editWhen this option is enabled, Filebeat cleans files from the registry if they cannot be found on disk anymore. This setting does not apply to renamed files or files that were moved to another directory that is still visible to Filebeat. This option is enabled by default.
If a shared drive disappears for a short period and appears again, all files will be read again from the beginning because the states were removed from the registry file. In such cases, we recommend that you disable the clean_removed option.
You must disable this option if you also disable close_removed.
scan_frequency
editHow often the prospector checks for new files in the paths that are specified
for harvesting. For example, if you specify a glob like /var/log/*, the
directory is scanned for files using the frequency specified by
scan_frequency. Specify 1s to scan the directory as frequently as possible
without causing Filebeat to scan too frequently. We do not recommend to set this value <1s.
If you require log lines to be sent in near real time do not use a very low scan_frequency but adjust close_inactive so the file handler stays open and constantly polls your files.
The default setting is 10s.
document_type
editDeprecated in 5.5.
Use fields instead
The event type to use for published lines read by harvesters. For Elasticsearch
output, the value that you specify here is used to set the type field in the output
document. The default value is log.
harvester_buffer_size
editThe size in bytes of the buffer that each harvester uses when fetching a file. The default is 16384.
max_bytes
editThe maximum number of bytes that a single log message can have. All bytes after max_bytes are discarded and not sent.
This setting is especially useful for multiline log messages, which can get large. The default is 10MB (10485760).
json
editThese options make it possible for Filebeat to decode logs structured as JSON messages. Filebeat processes the logs line by line, so the JSON decoding only works if there is one JSON object per line.
The decoding happens before line filtering and multiline. You can combine JSON decoding with filtering
and multiline if you set the message_key option. This can be helpful in situations where the application
logs are wrapped in JSON objects, like it happens for example with Docker.
Example configuration:
json.keys_under_root: true json.add_error_key: true json.message_key: log
-
keys_under_root - By default, the decoded JSON is placed under a "json" key in the output document. If you enable this setting, the keys are copied top level in the output document. The default is false.
-
overwrite_keys -
If
keys_under_rootand this setting are enabled, then the values from the decoded JSON object overwrite the fields that Filebeat normally adds (type, source, offset, etc.) in case of conflicts. -
add_error_key -
If this setting is enabled, Filebeat adds a "json_error" key in case of JSON
unmarshalling errors or when a
message_keyis defined in the configuration but cannot be used. -
message_key - An optional configuration setting that specifies a JSON key on which to apply the line filtering and multiline settings. If specified the key must be at the top level in the JSON object and the value associated with the key must be a string, otherwise no filtering or multiline aggregation will occur.
multiline
editIf you are sending multiline events to Logstash, use the options described here to handle multiline events before sending the event data to Logstash. Trying to implement multiline event handling in Logstash (for example, by using the Logstash multiline codec) may result in the mixing of streams and corrupted data.
Options that control how Filebeat deals with log messages that span multiple lines. Multiline messages are common in files that contain Java stack traces.
The following example shows how to configure Filebeat to handle a multiline message where the first line of the message begins with a bracket ([).
multiline.pattern: '^\[' multiline.negate: true multiline.match: after
Filebeat takes all the lines that do not start with [ and combines them with the previous line that does. For example, you could use this configuration to join the following lines of a multiline message into a single event:
[beat-logstash-some-name-832-2015.11.28] IndexNotFoundException[no such index]
at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver$WildcardExpressionResolver.resolve(IndexNameExpressionResolver.java:566)
at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver.concreteIndices(IndexNameExpressionResolver.java:133)
at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver.concreteIndices(IndexNameExpressionResolver.java:77)
at org.elasticsearch.action.admin.indices.delete.TransportDeleteIndexAction.checkBlock(TransportDeleteIndexAction.java:75)
See Managing Multiline Messages for more configuration examples.
You specify the following settings under multiline to control how Filebeat combines the lines in the message:
-
pattern - Specifies the regular expression pattern to match. Note that the regexp patterns supported by Filebeat differ somewhat from the patterns supported by Logstash. See Regular Expression Support for a list of supported regexp patterns.
-
negate -
Defines whether the pattern is negated. The default is
false. -
match -
Specifies how Filebeat combines matching lines into an event. The settings are
afterorbefore. The behavior of these settings depends on what you specify fornegate:Setting for negateSetting for matchResult Example pattern: ^bfalseafterConsecutive lines that match the pattern are appended to the previous line that doesn’t match.
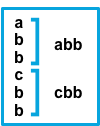
falsebeforeConsecutive lines that match the pattern are prepended to the next line that doesn’t match.
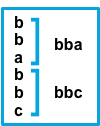
trueafterConsecutive lines that don’t match the pattern are appended to the previous line that does match.
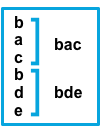
truebeforeConsecutive lines that don’t match the pattern are prepended to the next line that does match.
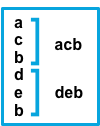
The
aftersetting is equivalent topreviousin Logstash, andbeforeis equivalent tonext. -
max_lines -
The maximum number of lines that can be combined into one event. If
the multiline message contains more than
max_lines, any additional lines are discarded. The default is 500. -
timeout - After the specified timeout, Filebeat sends the multiline event even if no new pattern is found to start a new event. The default is 5s.
tail_files
editIf this option is set to true, Filebeat starts reading new files at the end of each file instead of the beginning. When this option is used in combination with log rotation, it’s possible that the first log entries in a new file might be skipped. The default setting is false.
This option applies to files that Filebeat has not already processed. If you ran Filebeat previously and the state of the file was already persisted, tail_files will not apply. Harvesting will continue at the previous offset. To apply tail_files to all files, you must stop Filebeat and remove the registry file. Be aware that doing this removes ALL previous states.
You can use this setting to avoid indexing old log lines when you run Filebeat on a set of log files for the first time. After the first run, we recommend disabling this option, or you risk losing lines during file rotation.
pipeline
editThe Ingest Node pipeline ID to set for the events generated by this prospector.
The pipeline ID can also be configured in the Elasticsearch output, but this option usually results in simpler configuration files. If the pipeline is configured both in the prospector and in the output, the option from the prospector is the one used.
symlinks
editThe symlinks option allows Filebeat to harvest symlinks in addition to regular files. When harvesting symlinks, Filebeat opens and reads the original file even though it reports the path of the symlink.
When you configure a symlink for harvesting, make sure the original path is excluded. If a single prospector is configured to harvest both the symlink and the original file, the prospector will detect the problem and only process the first file it finds. However, if two different prospectors are configured (one to read the symlink and the other the original path), both paths will be harvested, causing Filebeat to send duplicate data and the prospectors to overwrite each other’s state.
The symlinks option can be useful if symlinks to the log files have additional metadata in the file name, and you want to process the metadata in Logstash. This is, for example, the case for Kubernetes log files.
Because this option may lead to data loss, it is disabled by default.
backoff
editThe backoff options specify how aggressively Filebeat crawls open files for updates. You can use the default values in most cases.
The backoff option defines how long Filebeat
waits before checking a file again after EOF is reached. The default is 1s, which means
the file is checked every second if new lines were added. This enables near real-time crawling. Every time a new line appears in the file, the backoff value is reset to the initial
value. The default is 1s.
max_backoff
editThe maximum time for Filebeat to wait before checking a file again after EOF is
reached. After having backed off multiple times from checking the file, the wait time
will never exceed max_backoff regardless of what is specified for backoff_factor.
Because it takes a maximum of 10s to read a new line, specifying 10s for max_backoff means that, at the worst, a new line could be added to the log file if Filebeat has
backed off multiple times. The default is 10s.
Requirement: max_backoff should always be set to max_backoff <= scan_frequency. In case max_backoff should be bigger, it is recommended to close the file handler instead let the prospector pick up the file again.
backoff_factor
editThis option specifies how fast the waiting time is increased. The bigger the
backoff factor, the faster the max_backoff value is reached. The backoff factor
increments exponentially. The minimum value allowed is 1. If this value is set to 1,
the backoff algorithm is disabled, and the backoff value is used for waiting for new
lines. The backoff value will be multiplied each time with the backoff_factor until
max_backoff is reached. The default is 2.
harvester_limit
editThe harvester_limit option limits the number of harvesters that are started in parallel for one prospector. This directly relates
to the maximum number of file handlers that are opened. The default for harvester_limit is 0, which means there is no limit. This
configuration is useful if the number of files to be harvested exceeds the open file handler limit of the operating system.
Setting a limit on the number of harvesters means that potentially not all files are opened in parallel. Therefore we recommended that you use
this option in combination with the close_* options to make sure harvesters are stopped more often so that new files can be
picked up.
Currently if a new harvester can be started again, the harvester is picked randomly. This means it’s possible that the harvester for a file that was just closed and then updated again might be started instead of the harvester for a file that hasn’t been harvested for a longer period of time.
This configuration option applies per prospector. You can use this option to indirectly set higher priorities on certain prospectors by assigning a higher limit of harvesters.
enabled
editThe enabled option can be used with each prospector to define if a prospector is enabled or not. By default, enabled is set to true.