Nori: The Official Elasticsearch Plugin for Korean Language Analysis
Some time ago, we published a blog post about which Korean analyzer you should use in Elasticsearch. The article presented three third-party plugins that you can install to enhance Korean support within your Elasticsearch cluster. We are excited to announce that as of Elasticsearch 6.4, we’ll provide an official, best-in-class plugin called analysis-nori to handle this popular language. In this blog post, I am going to describe the story behind Nori, the new Lucene module that is used by the plugin to handle Korean text analysis.
Segmenting Korean text
Spaces are used in Korean to delimit what is called an eojeol, a sequence of morphemes agglutinated together to form a meaning. For instance 선생님께서 is an eojeol made of three components, 선생 a noun that means teacher, 님 an honorific suffix and 께서 the honorific form of the particles 이 and 가 denoting the subject of a sentence. This eojeol means that an esteemed teacher is the subject of a sentence. Detecting these individual morphemes automatically is a difficult task that requires knowledge of the vocabulary and morphology of words in the language.
MeCab
The number of rules and exceptions in the language makes the development of a rule-based system quite complex so most of the successful implementations of Korean morphological analyzers are done through probabilistic modeling. The 21st Century Sejong Project, started in 1998 by the Korean government, initiated the creation of large-scale Korean corpus. With the publication of this corpus over the years that follow it became easier to build probabilistic modeling of Korean morphology. Today almost all the available morphological analyzers for Korean found their origin in the 21st Century Sejong Project. The mecab-ko-dic is one of them, it uses MeCab (pronounced Mekabu): a popular open source morphological analysis engine to train a probabilistic model of the Korean morphology from parts of the corpus created by the 21st Century Sejong Project.
MeCab was originally written for the segmentation of Japanese. It uses the conditional random fields to learn a bigram model from an annotated corpus of sentences where the cost of moving from one morpheme to another depends only on the previous state. It does not depend on the language which is why it can be used to analyze Japanese and Korean seamlessly, the only difference being the dictionary that is used. Lucene has a morphological analyzer for Japanese since version 3.6, it uses the IPADIC dictionary also created with MeCab to segment and tag Japanese morphemes with their part of speech. Since both dictionaries were created with the same tool, it was tempting to try to reuse the Lucene’s Japanese analyzer to handle this Korean dictionary. The advantage of such a method is that we could benefit from a robust analyzer optimized over the years in terms of memory consumption and throughput. This is how Nori, "play" in Korean, was born. It started by borrowing the code of the Japanese analyzer and evolved to a standalone morphological analyzer for Korean.
The mecab-ko-dic dictionary defines a model to analyze the korean language morphologically. It is made of different files that expose the informations needed to perform the morphological analysis in MeCab. The total size on disk after decompression of the latest distribution is 219MB. Considering that it is the textual form of the dictionary, one of the main challenges for the new Korean module was to provide a compressed form of this data that can be quickly loaded in memory for fast lookups. To achieve this, Nori translates the original dictionary into a binary format. The transformation is done offline, as a standalone process, and the resulting binary dictionary is added as a resource inside the module. This transformation is needed to diminish the size of the module: we don’t want to distribute 200MB of dictionary in a Lucene’s module. This conversion is also done to provide a format that is optimized for lookups. Morphological analysis requires one lookup in the dictionary for each character in the input, so we need efficient data structures. In the next section I’ll describe how we use the original dictionary to build a smaller, optimized for lookups, binary version of the same data.
*.csv file
The vocabulary is defined in a set of comma separated values file where an entry looks like this:
도서관,1781,3535,2110,NNG,*,T,도서관,Compound,*,*,도서/NNG/*+관/NNG/*
The first four columns are generic in the MeCab format. The first column is the surface form of the term, 도서관 (doseogwan), a library in english. It is followed by the left context ID for this term, the right context ID and finally the cost of the term. MeCab uses a bigram language model so the left and right context IDs are used to compute the cost of moving from one state to another. The costs for each transition (left to right) are available in a file named matrix.def. The fifth column is the part of speech for the term based on the Sejong corpus classification.
You can find the full list and their meaning in this Enum POS doc, NNG being a general noun. The extra columns on the right are features that are specific to Korean and the mecab-ko-dic format. In this example, the term is considered as a “Compound”, a noun made of other nouns and the decompounding is provided in the last column, 도서관 (library) => 도서 (book) + 관 (house).
When Nori analyzes an input it needs to perform a lookup in this dictionary on every character in order to build the lattice of all possible segmentations. In order to achieve this efficiently we encode the full vocabulary in an FST (finite state transducer) where the transition labels are the Korean symbols of the dictionary terms and the output is an ID that links the surface form of the terms to the list of associated entries with their feature array.
There are 11,172 possible symbols in Korean so the FST is very dense at the root and becomes sparse very quickly. It encodes the 811,757 terms included in the mecab-ko-dic with 171,397 nodes and 826,926 arcs in less than 5.4MB.
Nori’s feature array uses a custom binary format that encodes each entry of the original csv files using 9 bytes in average for a total size of 7MB. This compression was made possible by taking into account the particularity of the Korean language. For instance, nouns are invariable in Korean. So instead of saving the nouns that compose a specific compound, we encode the size in characters of each split. For the example above, the de-compound of 도서관, can be encoded with 2 for 도서 and 1 for 관. Since compounds are always made of nouns we can also omit the part of speech associated with each split to finally reduce 16 bytes into 2.
Matrix.def
This file contains the connection costs between a right context ID and a left context ID. These costs are computed by MeCab during the learning phase and they are used at analysis time to compute the cost of a possible segmentation. The matrix is big. There are 2690 left context IDs and 3815 right context IDs so the full matrix contains 10,262,350 cells. The original file encodes the matrix with one triplet (right context ID, left context ID, cost) per line for a total of 139MB. To add this information in the binary dictionary we compress the matrix using variable length encoding and serialize the result in a file. This compression reduces the size to less than 12MB. However we need fast lookups in this matrix so when the module starts we load a fully decompressed version of the matrix in memory using 2 bytes per transition (costs are encoded using 16 bits) for a total of 20MB. This is quite a big resource to load in the java heap so this structure is loaded in a direct byte buffer outside of the heap.
The final size of the binary dictionary is 24MB on disk. This is a good compression ratio considering that the binary format is optimized for lookups. Providing a lightweight dictionary is important since it allows the usage of the Lucene’s Korean module in small deployment where there is a limited amount of RAM available.
Morphological analysis
Now that we have a well-constructed binary dictionary that can be used to lookup efficiently any terms that appear in the mecab-ko-dic dictionary, we can analyze text using the Viterbi algorithm to find the most likely segmentation (called the Viterbi path) of any input written in Korean. The figure below shows the Viterbi lattice built from the sentence 21세기 세종계획. (the 21st century Sejong plan):
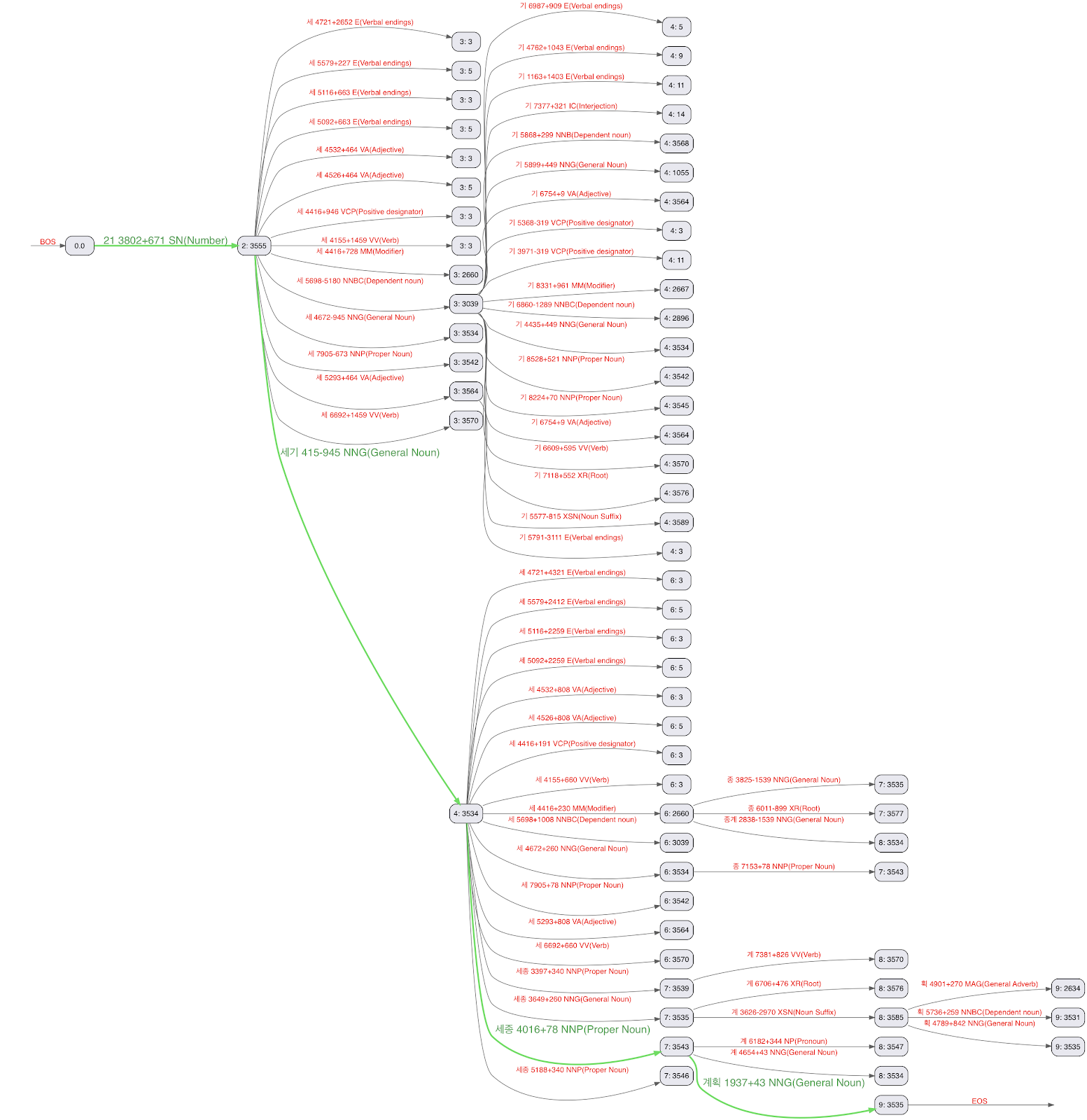
The Viterbi path in green shows the segmentation that Nori outputs:
21 + 세기 (century) + 세종 (Sejong) + 계획 (Plan)
Usually the algorithm to find the best segmentation uses three steps. It finds the next sentence boundary in the input first, then it builds the lattice of all possible path for this sentence and finally it computes the best path (segmentation) by applying the cost of each transition. These steps are applied until all sentences in the input are consumed. Applying these steps sequentially can be slow, so Nori uses a different approach. It uses a single step that is optimized for throughput. It consumes the input forward, character by character, and builds the Viterbi lattice on the fly. Costs are also computed on the fly in order to keep only the least costly path at each character boundary. For instance in the figure above, the path 21 + 세 + 세 is pruned as soon as we discover that 21 + 세기 has a lower cost. The processing stops at each frontier (when a state has only one possible transition) or after 1024 characters (to avoid memory issues if every state has multiple transitions) to output the best segmentation of the current lattice and restart the processing on the next character window.
Benchmarks
Now that we know how Nori is implemented let’s see how it behaves in a real use case.
I used Rally to create a small benchmark to compare the indexing throughput of Nori against two popular community plugins: seunjeon and arirang . The benchmark consists of indexing 413,985 documents extracted from the Korean Wikipedia in a single shard using 8 clients.
The Seunjeon plugin also uses the mecab-ko-dic and has several options to customize the output. I used the latest version (6.1.1.1, as of May 29, 2018) with the default analyzer provided in the plugin and tested with and without the compress option (-Dseunjeon.compress=true) on two Elasticsearch configurations, one with a heap size of 512m and one with 4G.
Arirang uses its own dictionary and does not provide any options so I used the default analyzer provided in the plugin.
The figure below shows the median throughput of the bulk indexing for both configurations:
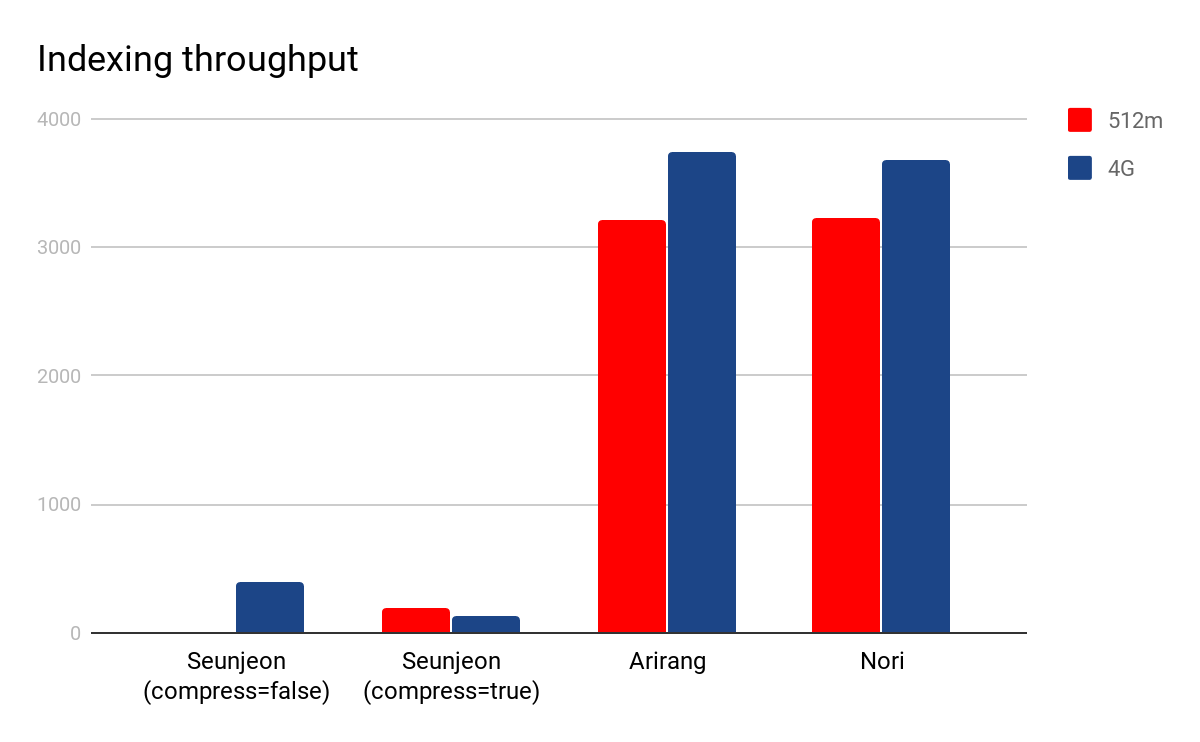 Nori and Arirang performed similarly with an indexing throughput of more than 3000 documents per second. However the Arirang plugin fails to index 10% of the corpus due to negative offsets set by the analyzer. The Seunjeon plugin has a peak at 400 documents per second in its non-compressed version, but it crashed several times with an out of memory error when run on the 512m node, which explains why the result is missing for this configuration. Using the compressed version fixed the issue on the 512m configuration resulting in an indexing throughput of 130 documents per second, almost 30 times slower than Arirang and Nori.
Nori and Arirang performed similarly with an indexing throughput of more than 3000 documents per second. However the Arirang plugin fails to index 10% of the corpus due to negative offsets set by the analyzer. The Seunjeon plugin has a peak at 400 documents per second in its non-compressed version, but it crashed several times with an out of memory error when run on the 512m node, which explains why the result is missing for this configuration. Using the compressed version fixed the issue on the 512m configuration resulting in an indexing throughput of 130 documents per second, almost 30 times slower than Arirang and Nori.
Conclusion
In this article we presented Nori, a fast, lightweight Korean analyzer added to Lucene 7.4.0. We’re trying our best to enhance languages support in Lucene and Elasticsearch, and Nori is a good example of how we approach things. Natural language processing is a journey not a destination so stay tuned. We have more improvements coming soon and in the meantime we encourage you to learn more about this new plugin through the Elasticsearch documentation on Nori, and download the latest version of Elasticsearch to try it yourself!