Elasticsearch as a system of engagement in financial services
One thing you can always count on is that as technology advances, data volume and usage will keep growing. More data can lead to more informed, faster decisions and optimizations.
That growth is not always equally distributed, though. Often, read-side queries far outweighs write-side actions, meaning we search for answers in data much more often than we create, update, or delete our datasets. So while many data stores can store petabytes of data, they often can’t use data at that scale. If pushed far enough, traditional RDBMS databases lack enough affordable read-side performance.
For example, in one of their mainframes, Barclays found that 92% of traffic across all channels was triggered by just 25 transactions. And 85% of those 25 transactions were read-only. This is because, fundamentally, online transaction processing (OLTP) systems have not been designed as massive retrieval databases, but instead focus on referential integrity, lookups, and minimization of disk space. While these attributes can be useful, read-side queries tend to suffer in RDBMS-powered architectures as usage grows. Online analytical processing (OLAP) databases perform somewhat better, but still lack robust search features, like multilingual full-text search or recommendation search.
Elasticsearch, though, excels at read-side queries at any scale. It is the industry leader in search engines and able to horizontally scale while staying fast. By combining both into a dual database architecture, we can have it all. Let’s take a look at some of the powerful tools Elasticsearch has up its sleeve, and see why it’s the perfect choice as a system of engagement (SoE) for any infrastructure.
Use case: Mainframe offloading
Let’s look at a practical example of a system of engagement. PSD2 is a set of APIs that are part of Open Banking Regulation. Open Banking, as its name suggests, means that the consumer of financial products (accounts, loans, credit cards) have the right to access that data and use it however they see fit. Before open banking, you could only really see your transactional information on the terms provided by your bank, such as bank statements. After PSD2 regulation came into effect, any bank is allowed to consume the PSD2 APIs of other banks and create a finance 360-degree view of a person.
These developments are exciting, as they will unlock new use cases for personal finance, customer 360, and payments. At the same time, it will put even more pressure on the system of record (SoR), as customers and data scientists tend to ask complex questions, while the mainframe is so central to the organization’s success that it's best kept simple. The solution is to use Elasticsearch as a system of engagement to take care of answering complex questions.
A typical implementation consists of:
- System of record (write-model): The legacy system that holds the business data. Note that Elasticsearch can be used as a system of record, but for the sake of this example, it’s assumed that existing infrastructure will need to remain in place.
- System of engagement (read-model): Acts as the analytical and search speed layer. As most user interactions are read-only, it is the main system underpinning user engagement.
- Elastic Stack for monitoring (observability): This is where all other components will write their logs, metrics, and traces (APM) that provide complete transparency in how the architecture is performing and how it is used. Are all components running? How many users are active today? Do we see any suspicious behavior? This oversight is commonly referred to as observability.
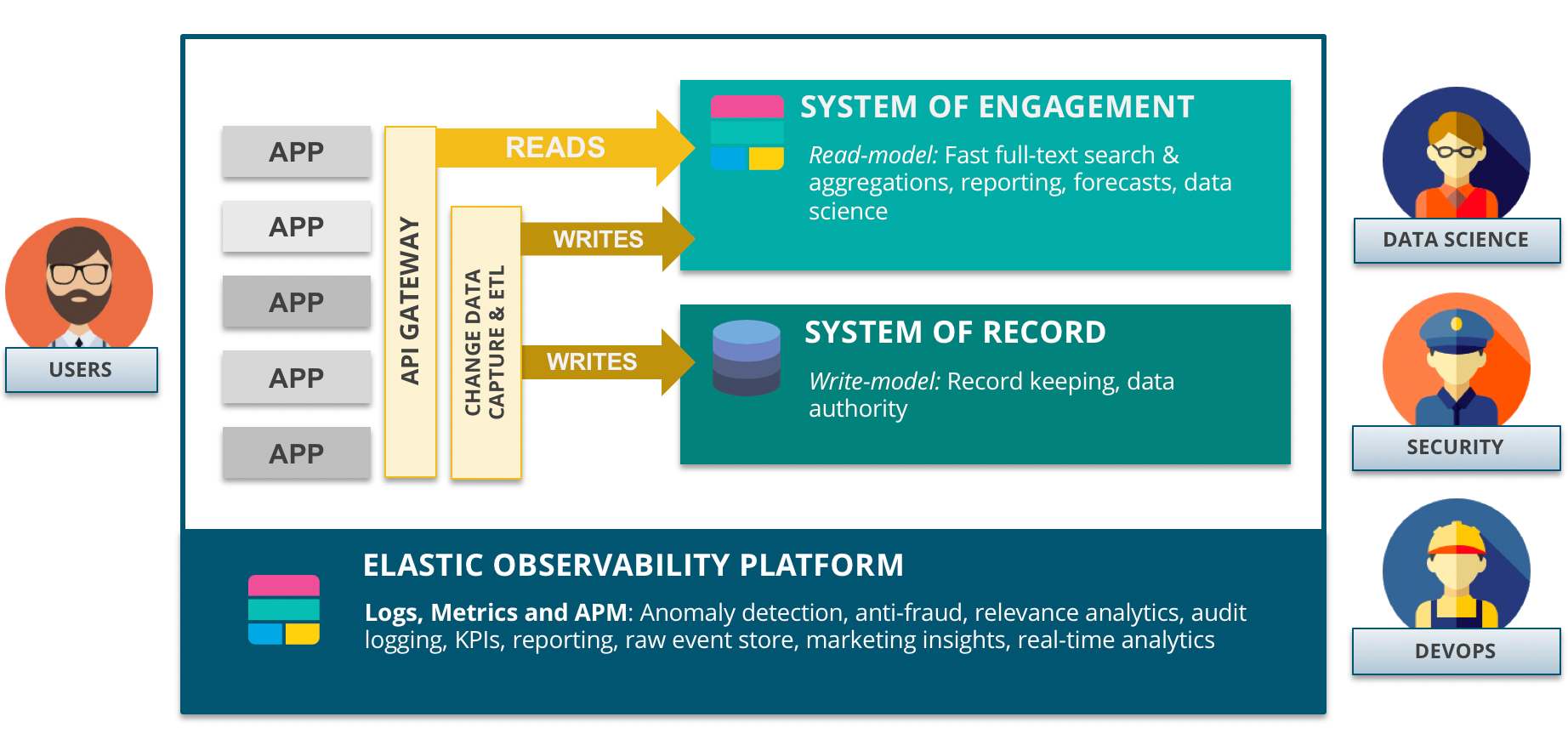
Approaches to streamline data between systems of record and Elasticsearch:
- Batch: Set up a scheduled job to sync systems of record with Elasticsearch on a predetermined interval. This can be done easily with Logstash JDBC inputs.
- Real-time: This method allows for near real-time synchronization between the two databases. This can be as simple as writing data twice from the application. Beats and Logstash can do this as well as they support incoming API calls using TCP connections. There are also several open source change data capture (CDC) projects that aim to help out with propagating changes in a SoR to Elasticsearch. An architectural pattern related to the speed layer is Command Query Responsibility Segregation (CQRS).
Both Rabobank and Collector Bank are using Elastic for highly scalable, affordable transactional search and have written about their experience.
Not only is Rabobank searching faster than ever, they’re searching through more data than ever. With over 23 billion transactions spanning 80TB of data, Rabobank sees upwards of 200 events per second — over 10 million per day. And each query can span thousands of accounts, with corporate customers having over 5,000 accounts that they can now query at once. And being able to do all this without adding any extra operations to their costly mainframes has helped save them millions of euros per year.
More examples of systems of engagement:
- Enterprise resource planning (ERP): Offloading data sitting in ERP systems and making it available to customer agents, web portals, and mobile apps without having to touch the ERP, thus reducing the pressure on it.
- Customer 360 / Know Your Customer (KYC) compliance: Combining data from many sources to bring together all information around an entity (entity centric), such as a person or a company.
- Data virtualization and data lakes: Reducing the number of tools necessary to access a breadth of information.
- E-commerce: Using Elasticsearch as the sole datastore to run an e-commerce frontend: search, analytics, aggregations, suggestions, and forecasting.
- Fraud: Finding suspicious patterns in data requires putting all known facts about an entity in a single database, and then requires capabilities such as fuzzy matching, traversing relationships, correlation, and outlier detection.
The Elastic advantage
In real-life cases, Elastic has shown to:
- Simplify the existing SoR by offloading complex questions, reducing risk.
- Lower license costs of SoR, with the additional benefit of not getting charged for things like exceptional peak loads, seats, extensions, queries, or customers.
- Increase development output by improving access to skills, lower maintenance, and lower complexity.
All search cases are unique, yours included. Still, we can cluster search cases together over a number of attributes and let a couple of search use cases emerge.
Use case | Searchable data size | Query complexity | Query volume |
Site search, application search | Low/Moderate | Low/Moderate | Moderate |
Enterprise search | (Very) Large | Moderate | Low/Moderate |
Knowledge search: fraud, patents, legal, scientific, etc. | Large | (Very) High | Low/Moderate |
System of engagement, speed layer | (Very) Large | Moderate | (Very) High |
Elasticsearch comes fully equipped with features for all these search challenges, including:
- Horizontal scalability: a document store that is fully cloud-ready and lets you scale the cluster as needed, for any workload.
- Flattened documents instead of star schemas, forgoing the need for expensive read-side joining of large sets of data.
- Sorted indices that store data in sequence along one or more sort columns, like time, so that those queries run even faster.
- Trimmed indices, which give the user full control over resource utilization including disk and memory needed to run the workload.
- Rollups and data frames, that allow for highly compressed indices optimized for aggregations, essentially pre-aggregating the raw data.
- Elasticsearch SQL, for making the transition easier for users starting with Elasticsearch but experienced in SQL, who will be able to create their queries in the language they are used to.